Что такое облака, и когда имеет смысл строить облачные решения? И если строить, то какие платформы использовать? Нужно ли предоставлять клиентам облачные сервисы? А может, лучше использовать виртуализацию? И чем отличается виртуализация от облаков? Эти вопросы задают все IT и «не IT» компании: от крупных операторов связи до небольших стартапов. Давайте попробуем разобраться! В предыдущей статье мы рассмотрели понятия SDN и NFV. Возникает вопрос — если и то и другое связано с виртуализацией и сетями, то это получились облака? Ведь все мы прекрасно знаем, что облака — это виртуализация ресурсов где-то в сети. Я попробовал найти формальное определение облаков, но не нашел. Определения были расплывчаты и нечетки, как настоящие облака. И тогда у меня возникло чувство, что ОБЛАКАМ невозможно дать четкого определения, они как ЛЮБОВЬ, которую можно только описывать и характеризовать с разных сторон. Дальнейшее расследование подтвердило это предположение. Для начала нашел стандарт Cloud Computing, который разрабатывает NIST (National Institute of Standards and Technology). Он выделяет 3 измерения облачных сервисов:

Dilmurod @dilikjanread-only
Engineer Datacom
Тридцать лет С++. Интервью с Бьерном Страуструпом
10 min
Translation

Ранее мы делали материал про использование C и C++ в Data Science. А сегодня мы хотим поделиться с вами интервью с автором C++ Бьерном Страуструпом. Далее в посте вас ждет рассказ о профессиональном пути Бьерна, деталях создания собственного языка программирования и извлеченные им из этого уроки.
Дональд Кнут
8 min

Дональд Эрвин Кнут — американский учёный, почётный профессор Стэнфордского университета и нескольких других университетов в разных странах, преподаватель и идеолог программирования, автор 19 монографий (в том числе ряда классических книг по программированию) и более 160 статей, разработчик нескольких известных программных технологий. Автор всемирно известной серии книг, посвящённой основным алгоритмам и методам вычислительной математики, а также создатель настольных издательских систем TEX и METAFONT, предназначенных для набора и вёрстки книг, посвящённых технической тематике (в первую очередь — физико-математических).
Эволюция языков программирования
5 min
Пятница — самое время расслабиться и вспомнить, с чего все началось. Представляем вам краткий экскурс в историю разработки от GeekBrains.

Обзор: Puppet, Chef, Ansible, Salt
9 min
Ведущие инструменты для управления конфигурацией по разному подходят к автоматизации серверов
От переводчика: в связи с грядущим внедрением одной из подобных описанным в статье систем, приходится изучать доселе неведомые продукты. Захотелось перевести, поскольку подобных обзорных статей на русском языке не нашлось (не исключаю, что плохо искал), и, надеюсь, кому-то и пригодится. За возможные ошибки и неточности перевода просьба ногами не бить.
Быстрое развитие виртуализации вкупе с увеличением мощности серверов, соответствующих промышленным стандартам, а также доступность «облачных» вычислений привели к значительному росту числа нуждающихся в управлении серверов, как внутри, так и вне организации. И если когда-то мы делали это при помощи стоек с физическими серверам в центре обработки данных этажом ниже, то теперь мы должны управлять гораздо большим количеством серверов, которые могут быть распределены по всему земному шару.
В этот момент средства управления конфигурациями и вступают в игру. Во многих случаях, мы управляем группами одинаковых серверов, на которых запущены одинаковые приложения и сервисы. Они размещаются на системах виртуализации внутри организации, или же запускаются как «облачные» и гостевые в удаленных ЦОД. В некоторых случаях, мы можем говорить о большом количестве оборудования, которое существует только для поддержки очень больших приложений или об оборудовании, обслуживающем мириады небольших сервисов. В любом случае, возможность «взмахнуть волшебной палочкой» и заставить их всех выполнить волю системного администратора не может быть обесценена. Это единственный путь управлять огромными и растущими инфраструктурами.
Puppet, Chef, Ansible и Salt были задуманы чтобы упростить настройку и обслуживание десятков, сотен и джае тысяч серверов. Это не значит, что маленькие компании не получат выгоды от этих инструментов, так как автоматизация обычно делает жизнь проще в инфраструктуре любого размера.
Я пристально взглянул на каждый из этих четырех инструментов, исследовал их дизайн и функциональность, и убежден, что несмотря на то, что некоторые оценены выше, чем другие, для каждого есть свое место, в зависимости от целей внедрения. Здесь я подвожу итоги моих находок.
Система управления Ansible
25 min
Tutorial

Представьте себе, что вам нужно управлять парком серверов, расположенных к тому же в разных географических точках. Каждый из этих серверов требует настройки, регулярного обновления и мониторинга. Конечно, для решения этих задач можно воспользоваться самым простым способом: подключиться к каждому серверу по ssh и внести необходимые изменения. При всей своей простоте этот способ сопряжен с некоторыми трудностями: он чрезвычайно трудоемок, а на выполнение однообразных операций уходит очень много времени.
Чтобы упростить процессы настройки и конфигурирования серверов, можно также писать shell-скрипты. Но и этот способ вряд ли можно назвать совершенным. Скрипты нужно постоянно изменять, подстраивая их под каждую новую задачу. При их написании необходимо учитывать различие операционных систем и версий. Не будем забывать и о том, что отладка скриптов отнимает много усилий и забирает немало времени.
Оптимальным вариантом решения описанных проблем является внедрение системы удаленного управления конфигурацией. В таких системах достаточно лишь описать нужное состояние управляемого узла. Система должна сама определить, что нужно сделать для достижения этого состояния, и осуществит все необходимые действия.
Со всеми сложностями, о которых идет речь выше, мы хорошо знакомы на собственном опыте: у нас имеется 10 точек присутствия с NS-серверами, расположенные в разных точках планеты. На них необходимо регулярно вносить различные изменения: обновлять операционную систему, устанавливать и обновлять различное ПО, изменять конфигурцию и т.п. Мы решили все эти операции автоматизировать и внедрить систему удаленного управления конфигурациями. Изучив имеющиеся решения, мы остановили свой выбор на Ansible.
В этой статье мы бы хотели подробно рассказать о его возможностях этого инструмента управления конфигурациями и поделиться собственным опытом его использования.
15 вещей, которые вы должны знать об Ansible
9 min
Предлагаю читателям «Хабрахабра» перевод опубликованной на codeheaven.io статьи «15 Things You Should Know About Ansible» за авторством Marlon Bernardes.
В последнее время я много работал с Ansible и решил поделиться некоторыми вещами, которые выучил по пути. Ниже вы найдете список из 15 вещей, которые, как я думаю, вы должны знать об Ansible. Что-то пропустил? Просто оставьте комментарий и поделитесь вашими личными советами.
В последнее время я много работал с Ansible и решил поделиться некоторыми вещами, которые выучил по пути. Ниже вы найдете список из 15 вещей, которые, как я думаю, вы должны знать об Ansible. Что-то пропустил? Просто оставьте комментарий и поделитесь вашими личными советами.
Ansible против Puppet
15 min
Translation
Ansible и Puppet представляют собой системы управления конфигурациями (SCM), необходимые для построения повторяющихся инфраструктур.
Ansible отличается простотой использования, имеет безагентную архитектуру (не требует установки агента/клиента на целевую систему) и YAML-подобный DSL, написана на Python и легко расширяется за счет модулей. Обычно управляет конфигурацией Linux.
Puppet имеет клиент-серверную архитектуру (периодически опрашивает сервер, чтобы внести в конфигурацию изменения, внесенные администратором сети), написана на Ruby и имеет Ruby-подобный DSL. Это приложение позволяет централизованно управлять конфигурацией ПО, установленного на нескольких компьютерах.
В статье проводится сравнение преимуществ и недостатков этих SCM.

Ansible отличается простотой использования, имеет безагентную архитектуру (не требует установки агента/клиента на целевую систему) и YAML-подобный DSL, написана на Python и легко расширяется за счет модулей. Обычно управляет конфигурацией Linux.
Puppet имеет клиент-серверную архитектуру (периодически опрашивает сервер, чтобы внести в конфигурацию изменения, внесенные администратором сети), написана на Ruby и имеет Ruby-подобный DSL. Это приложение позволяет централизованно управлять конфигурацией ПО, установленного на нескольких компьютерах.
В статье проводится сравнение преимуществ и недостатков этих SCM.
Разделение control и data plane в сетевом оборудовании
10 min

В работе сетевого устройства можно выделить две абстракции – управляющий уровень (control plane) и передающий уровень (data plane). Сontrol plane отвечает за логику работы сетевого устройства для обеспечения в дальнейшем возможности передачи пакетов (заполнение различных таблиц, например, маршрутизации, отработку различных служебных протоколов ARP/STP/и пр.). Data plane в свою очередь отвечает непосредственно за передачу полезного трафика через наше сетевое устройство. Т.е. сontrol plane нам предоставляет информацию куда и как слать сетевой трафик, а data plane уже выполняет поставленные перед ним задачи. Данные абстракции могут быть выделены как на логическом, так и на физическом уровне. Но всегда ли на сетевом оборудовании присутствует такое разделение и где именно выполняются функции каждой из абстракций? Давайте попробуем в этом разобраться.
NSX Advanced Load Balancer – умный автомасштабируемый балансировщик нагрузки. Часть 2: установка и настройка
8 min
Tutorial
В прошлый раз я рассказал о функциях балансировщика нагрузки NSX ALB, описал его архитектуру и схему работы. Мы посмотрели, как работает глобальная балансировка серверов (GSLB), которая объединяет серверы на географически разнесенных площадках в единый пул. В том числе, так можно распределять нагрузку между серверами в облаке и локальными серверами.
В этой статье поделюсь опытом внедрения системы для тестирования в нашем облаке. Опишу установку NSX ALB в VMware vCenter и основные этапы настройки для тех, кто хочет самостоятельно подключить для глобальной балансировки свою локальную площадку.
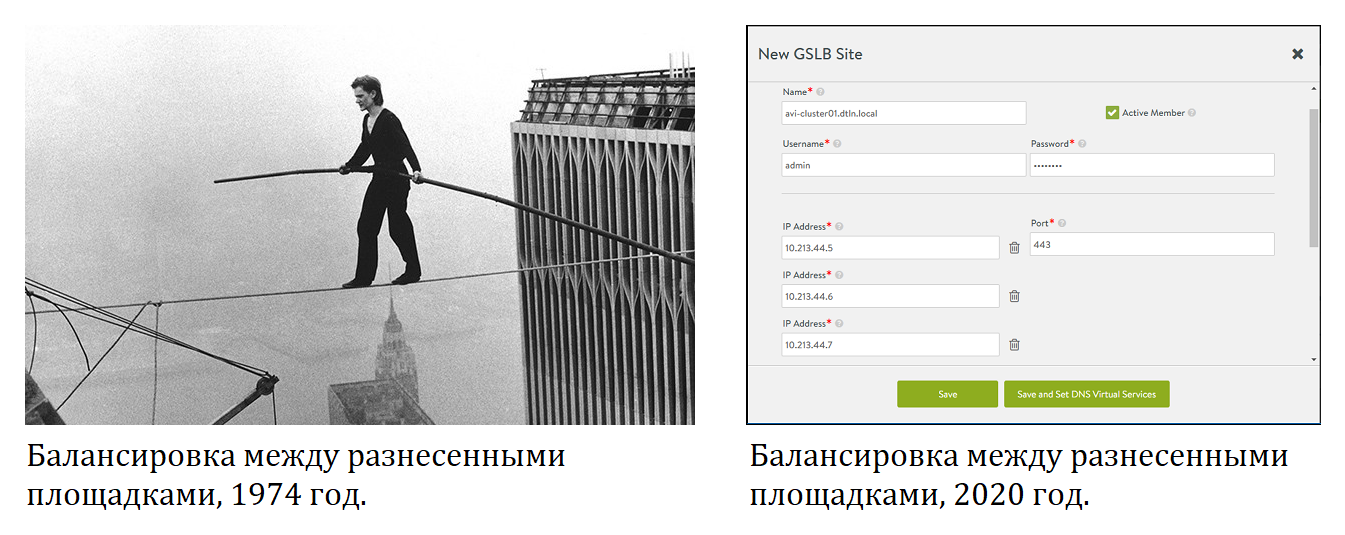
В этой статье поделюсь опытом внедрения системы для тестирования в нашем облаке. Опишу установку NSX ALB в VMware vCenter и основные этапы настройки для тех, кто хочет самостоятельно подключить для глобальной балансировки свою локальную площадку.
- развертывание и настройка контроллера;
- предварительная настройка сети;
- создание виртуального сервиса (VS) и подключение серверов для балансировки;
- настройка глобального сервиса балансировки серверов.
4 книги по цифровой трансформации для тимлидов, шпаргалка по Quarkus & Observability…
3 min
Мы собрали для вас короткий дайджест полезных материалов, найденных нами в сети за последние две недели. Оставайтесь с нами – станьте частью DevNation!
Red Hat Advanced Cluster Management и управление приложениями, часть 1. Развертывание в нескольких средах
9 min
Мы начинаем серию постов, в которой покажем, как Advanced Cluster Management (ACM) предоставляет обширные возможности для управление жизненным циклом приложений, которые должны существовать сразу в нескольких средах, неважно, в облаке или в корпоративном дата-центре.
Сегодня мы сосредоточимся на тех аспектах ACM, которые относятся к категории GitOps, и разберем их, используя следующую модельную конфигурацию:

Сегодня мы сосредоточимся на тех аспектах ACM, которые относятся к категории GitOps, и разберем их, используя следующую модельную конфигурацию:
NSX Advanced Load Balancer – умный автомасштабируемый балансировщик нагрузки. Часть 1: архитектура и особенности
9 min
В этом посте я хочу рассказать о системе балансировки нагрузки VMware NSX Advanced Load Balancer (by Avi Networks), или NSX ALB. Чуть больше года назад компания VMware купила компанию Avi Networks, и тогда же система балансировки сменила название с Avi Vantage на NSX ALB, но старое название Avi также сохранилось. С тех пор происходит интеграция балансировщика с продуктами VMware, в первую очередь, NSX. Но при этом остается возможность его автономного использования.
В сети почти нет систематизированной информации про NSX ALB на русском языке, только документация от вендора на английском. Поэтому в первой части я обобщил разрозненные источники и сделал обзор продукта: рассказал про особенности, архитектуру и логику работы, в том числе для географически разнесенных площадок. Во второй части я описал, как развернуть и настроить систему. Надеюсь, обе статьи будут полезны тем, кто ищет балансировщик для работы в облачных средах и хочет быстро оценить возможности NSX ALB.

В сети почти нет систематизированной информации про NSX ALB на русском языке, только документация от вендора на английском. Поэтому в первой части я обобщил разрозненные источники и сделал обзор продукта: рассказал про особенности, архитектуру и логику работы, в том числе для географически разнесенных площадок. Во второй части я описал, как развернуть и настроить систему. Надеюсь, обе статьи будут полезны тем, кто ищет балансировщик для работы в облачных средах и хочет быстро оценить возможности NSX ALB.
Как выбрать сервер видеоконференцсвязи
9 min
Выбор сервера – задача, с которой так или иначе сталкиваются все, кто занимается построением или масштабированием сети видеоконференцсвязи (или короче – ВКС). Давайте попробуем разобрать основные вопросы, возникающие при выборе инфраструктурных элементов системы видеоконференцсвязи.
Анализ таблиц маршрутизации, или зачем ещё сетевому инженеру Python
29 min
Hello Habr! Эта моя первая статья на Хабре, и родилась она из вопроса на одном из профессиональных форумов. Выглядел вопрос, несколько перефразируя, следующим образом:
- Имеется набор текстовых файлов, содержащих вывод таблиц маршрутизации с различных сетевых устройств;
- Каждый файл содержит информацию с одного устройства;
- Устройства могут иметь различный формат вывода таблицы маршрутизации;
- Необходимо на основании имеющихся данных по запросу выводить путь до произвольной подсети или IP-адреса с каждого из устройств;
- Вывод должен включать на каждом участке пути информацию о записи из таблицы маршрутизации, по которой будет смаршрутизирован пакет.
Задача мне показалась мне интересной и перекликалась с одной из собственных сетевых утилит, планируемых в перспективе.Поэтому в свободный вечер, поразмыслив над ее решением, написал Proof-of-Concept реализацию на Python 2.7 под формат Cisco IOS, IOS-XE и ASA, отвечающую основным требованиям.
В статье попытаюсь воспроизвести ход мысли и прокомментировать основные моменты.
Материал рассчитан на людей, уже базово знакомых с основами сетей и Python.
Всем заинтересовавшимся добро пожаловать под кат!
Визуализация сетевых топологий, или зачем еще сетевому инженеру Python #2
49 min
Привет, Хабр! Эта статья написана по мотивам решения задания на недавно прошедшем онлайн-марафоне DevNet от Cisco. Участникам предлагалось автоматизировать анализ и визуализацию произвольной сетевой топологии и, опционально, происходящих в ней изменений.
Задача является не самой тривиальной, и в блогосфере встречается довольно мало статей на эту тему. Ниже представляю разбор собственной реализации, а также описание используемых инструментов и подходов.
Всем заинтересовавшимся добро пожаловать под кат!
Cisco Meraki MX: настройки безопасности на периметре в 4 клика
4 min
Tutorial
Администраторы небольших и средних компаний часто не используют большинство функций своего корпоративного файрвола. По статистике, основных причин этого несколько. В 25 % случаев главные настройки выполнены, а на другие у администратора не хватает времени. Еще в 34 % случаев они не справились с настройками. И в 41 % случаев все имеющиеся функции попросту не требуются им. Из этого можно сделать вывод: шлюз безопасности нужно выбирать только в соответствии со своими собственными задачами и возможностями, не ориентируясь на весь перечень функций.
Для требований большинства компаний – как малых и средних, так и крупных с географически распределенной инфраструктурой – отлично подойдут шлюзы безопасности Cisco Meraki MX. Они просты в настройке, не требуют присутствия администраторов безопасности в отдаленных филиалах и вместе с тем используют те же наборы сигнатур, что и топ-решения Cisco Firepower.
Для требований большинства компаний – как малых и средних, так и крупных с географически распределенной инфраструктурой – отлично подойдут шлюзы безопасности Cisco Meraki MX. Они просты в настройке, не требуют присутствия администраторов безопасности в отдаленных филиалах и вместе с тем используют те же наборы сигнатур, что и топ-решения Cisco Firepower.
Программный интернет шлюз для уже не маленькой компании (Shorewall, OpenVPN, OSPF). Часть 1
13 min
Tutorial
Представляю пока две статьи, ориентированных на «продолжающих» системных администраторов, для опытных я вряд ли открою что-то новое.
В этих статьях мы рассмотрим построение интернет шлюза на linux, позволяющего связать несколько офисов компании, и обеспечить ограниченный доступ в сеть, приоритезацию трафика (QoS) и простую балансировку нагрузки с резервированием канала между двумя провайдерами.
Конкретно в этой части:
А во второй части будут рассмотрены:
В третьей части:
В четвертой части:
В этих статьях мы рассмотрим построение интернет шлюза на linux, позволяющего связать несколько офисов компании, и обеспечить ограниченный доступ в сеть, приоритезацию трафика (QoS) и простую балансировку нагрузки с резервированием канала между двумя провайдерами.
Конкретно в этой части:
- Простейшая настройка Shorewall
- Ужасно сложная настройка dnsmasq
- Не менее сложная настройка OpenVPN
- И для многих продолжающих админов нетипичная, динамическая маршрутизация, на примере OSPF
А во второй части будут рассмотрены:
- Более подробная настройка Shorewall
- Страшный и не понятный QoS
- Балансировка нагрузки и резервирование
В третьей части:
- QoS во всю ширь в Shorewall
- Более подробная настройка Shorewall
- Раскидывание трафика по каналам в соответствии с протоколами
- Костыли, без них, никуда
В четвертой части:
- Автоматические события
- Макросы
Руководство и шпаргалка по Wireshark
7 min
Tutorial
Translation
 Даже поверхностное знание программы Wireshark и её фильтров на порядок сэкономит время при устранении проблем сетевого или прикладного уровня. Wireshark полезен для многих задач в работе сетевого инженера, специалиста по безопасности или системного администратора. Вот несколько примеров использования:
Даже поверхностное знание программы Wireshark и её фильтров на порядок сэкономит время при устранении проблем сетевого или прикладного уровня. Wireshark полезен для многих задач в работе сетевого инженера, специалиста по безопасности или системного администратора. Вот несколько примеров использования:Устранение неполадок сетевого подключения
- Визуальное отображение потери пакетов
- Анализ ретрансляции TCP
- График по пакетам с большой задержкой ответа
Исследование сессий прикладного уровня (даже при шифровании с помощью SSL/TLS, см. ниже)
- Полный просмотр HTTP-сессий, включая все заголовки и данные для запросов и ответов
- Просмотр сеансов Telnet, просмотр паролей, введённых команд и ответов
- Просмотр трафика SMTP и POP3, чтение писем
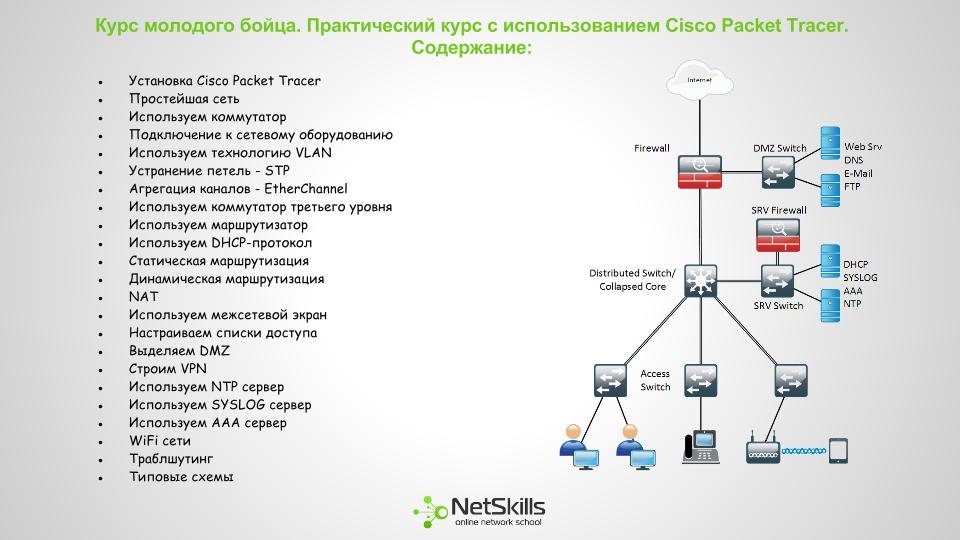
Курс молодого бойца. Практический курс по Cisco Packet Tracer
4 min
Быстрый старт
Началось все примерено пару лет назад. Работая в небольшой компании (системный интегратор) из небольшого города столкнулся с постоянной текучкой кадров. Специфика работы такова, что системный инженер за весьма короткий срок получает большой опыт работы с оборудованием и ПО ведущих мировых вендоров. Стоимость такого человека на рынке труда сразу возрастает (особенно, если он успевает получить пару сертификатов) и он просто уходит на более оплачиваемую работу (уезжает в резиновую Москву).
Естественно, что руководство такая ситуация не устраивала, но тут ничего не поделаешь. Единственный доступный вариант — это поставить обучение специалистов на конвеер. Чтобы даже студент после окончания университета мог приступить к работе через две-три недели экспресс-обучения. Так и было решено сформировать курсы для обучения внутри компании по различным направлениям. На мою долю упала разработка мини-курса по быстрому обучению сотрудников настройке сетевого оборудования.
Собственно после этого и началось создание «Курса молодого бойца» по сетевым технологиям.