
Вызов функций на локально развернутых LLM возможен. Прочитайте статью и узнайте, как это можно реализовать и насколько хорошо это работает!

Software Developer
Вызов функций на локально развернутых LLM возможен. Прочитайте статью и узнайте, как это можно реализовать и насколько хорошо это работает!

Насколько опасно умножать числа с помощью ChatGPT и OpenAI o1-preview, насколько можно доверять вычисленным ей константам? Стоит ли тратить деньги на o1-preview, если есть mini (в контексте умножения чисел)? Мини-исследование под катом.
Хайп вокруг нейросетей, выровненных при помощи инструкций и человеческой оценки (известных в народе под единым брендом «ChatGPT»), трудно не заметить. Люди разных профессий и возрастов дивятся примерами нейросетевых генераций, используют ChatGPT для создания контента и рассуждают на темы сознания, а также повсеместного отнимания нейросетями рабочих мест. Отдадим должное качеству продукта от OpenAI — так и подмывает использовать эту технологию по любому поводу — «напиши статью», «исправь код», «дай совет по общению с девушками».
Но как достичь или хотя бы приблизиться к подобному качеству? Что играет ключевую роль при обучении — данные, архитектура, ёмкость модели или что-то ещё? Создатели ChatGPT, к сожалению, не раскрывают деталей своих экспериментов, поэтому многочисленные исследователи нащупывают свой путь и опираются на результаты друг друга.
Мы с радостью хотим поделиться с сообществом своим опытом по созданию подобной модели, включая технические детали, а также дать возможность попробовать её, в том числе через API. Итак, «Салют, GigaChat! Как приручить дракона?»

Сегодня в ленте было про GPU для дата-центров. Смешно было про "мейнфреймы в офисе для AI" - в статье, на которую ссылается автор, нет ничего про то, что искуственный интеллект может или будет работать на мейнфреймах. И опять про "аппаратное ускорение AI" на пользовательских устройствах. Автор, вы сами попробуйте добраться до этого аппаратного ускорения, и если найдете как - напишите статью. А то элементарная попытка использования GPU для работы TensorFlow Lite приводит только к потерянному времени, а ускорители NPU больше не поддерживаются именно там, где должны были бы. То есть за хайпом вокруг "аппаратного ускорения ИИ" производители создали новую категорию устройств, и теперь стандартно ноутбук будет стоить в 2 раза больше, чем было раньше. А по факту пользоваться этим ускорением будут только компании-производители, чтобы еще больше заработать денег на пользователях через рекламу, "правильные" модели и торговлю персональными данными.
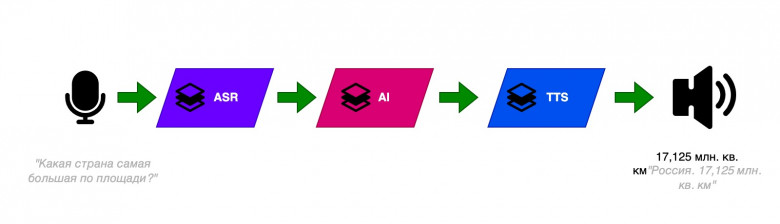
А мы сегодня запустим TensorFlow Lite на устройствах разного класса и года выпуска и посмотрим, что там с производительностью и ускорением.

По мере того, как я погружался в тему машинного обучения на мобильных устройствах, я все больше ощущал какой-то заговор. Как я уже писал, простые обучалки начали исчезать из интернета несколько лет назад. А простые обучалки – это те, в которых простые модели, то есть то, что делают люди, которые только начинают разбираться в теме. Вместо этого сейчас предлагается использовать готовые датасеты вполне определенным образом, и от этого остается один шаг до использования готовых моделей. А еще, примеры для мобильных устройств на главном сайте TensorFlow устарели и не работают на современных версиях библиотеки, причем уже давно! И похоже, что скоро NPU, которые есть в каждом современном телефоне, станут для нас абсолютно бесполезными.
Долгое время я прекрасно обходился без использования технологий искусственного интеллекта. Одни задачи можно было реализовать без всякого ИИ, а для других или готовых моделей не было или это были какие-то коммерческие облачные API.
В последнее время всё сильно изменилось и волна популярности искусственного интеллекта принесла множество крутейших моделей, позволяющих реализовать новые идеи или переосмыслить старые.
Казалось бы, есть и локально запускаемые аналоги ChatGPT или сервисов генерации изображений. Есть библиотеки типа llama.cpp - бери и используй! Но если бы было всё так просто, то не было бы этой статьи.
Для тех, кто не может ждать, можете посмотреть, чего теперь можно добиться относительно быстро:

Когда я прочитал новость о том, что исследователи MIT обнаружили вплоть до 10% ошибок в разметке самых популярных датасетов для обучения нейросетей, то решил, что нужно рассказать и о нашем опыте работы с публичными датасетами.
Уже более пяти лет мы занимаемся анализом сетевого трафика и машинным обучением моделей обнаружения компьютерных атак. И часто используем для этого публичные наборы обучающих данных. Расскажу, с какими сложностями мы при этом столкнулись и почему больше не верим публичным датасетам.

Celery можно любить или не любить, но избежать работы с ним практически невозможно. Однако, не все инженеры задумываются о том, что происходит в момент вызова Celery задач. И в этой статье я хочу рассказать, как именно происходит вызов и отправка сообщения, к чему может привести игнорирование того, что Celery под собой имеет транспорт, и что может произойти, если этот транспорт начнет сбоить.

Мы разработали бенчмарк LIBRA, который включает в себя 21 адаптированный набор данных для тщательного изучения способности LLM понимать длинный контекст. Помимо самих данных для оценки, мы опубликовали кодовую базу и лидерборд для сравнения моделей.

Используя технику Retrieval-Augmented Generation ("Поисковая расширенная генерация"), мы настроим русскоязычного бота, который будет отвечать на вопросы потенциальных работников для выдуманного свечного завода в городе Градск.
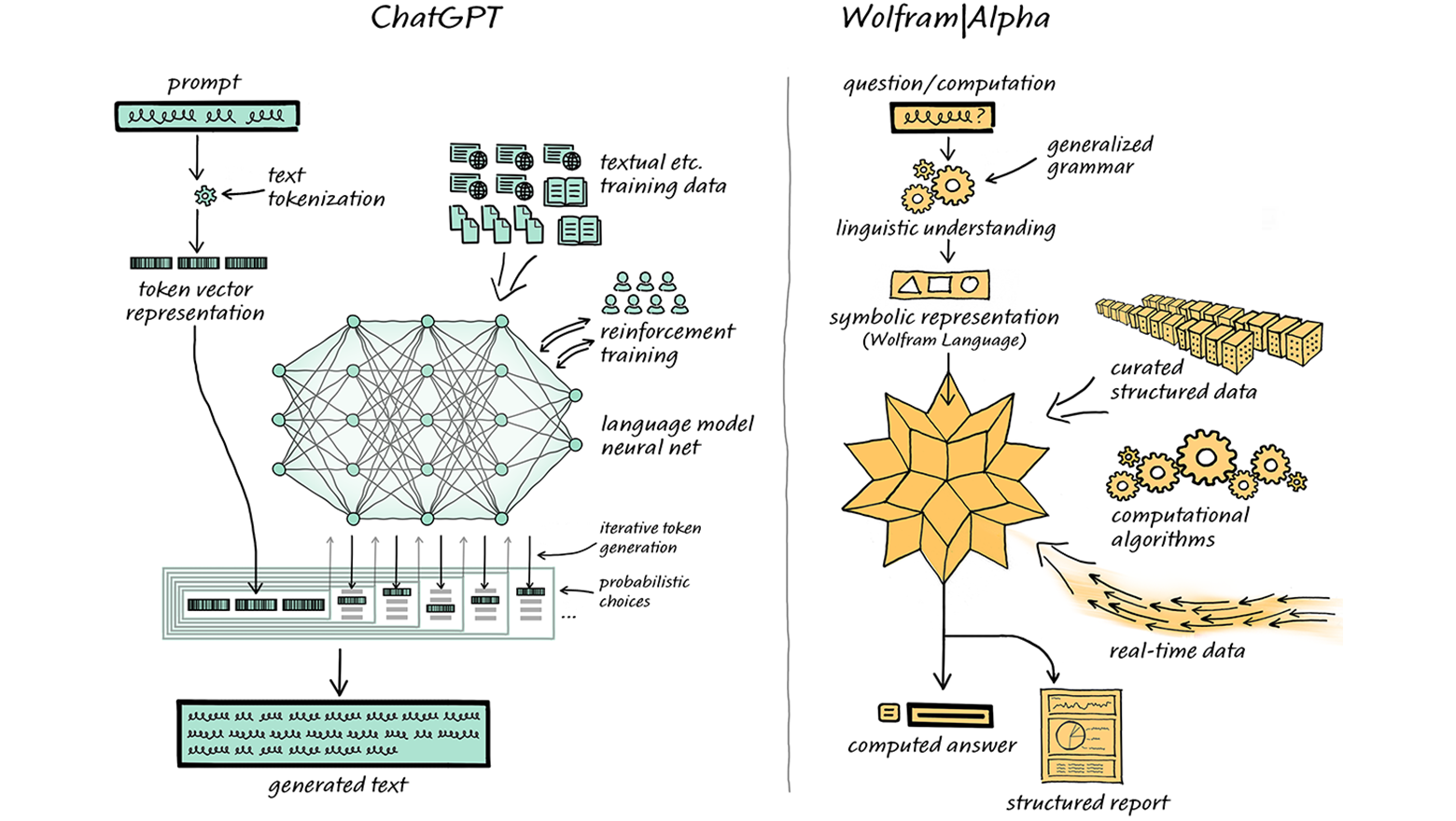
Четвёртая версия ChatGPT одних заставила пищать от восторга, а других повергла в уныние. Кто-то уже нашёл этой системе множество творческих применений, а кто-то пророчит, что эта нейросеть лишит работы кучу людей. Теперь возможности ChatGPT стали ещё шире: систему интегрировали с Wolfram | Alpha, легендарным движком для вычисления ответов в самых разных областях знания. Мы перевели для вас огромную подробную статью об этом от одного из разработчиков Wolfram | Alpha.

Сегодня мы выкладываем в опенсорс наш новый инструмент — алгоритм YaFSDP, который помогает существенно ускорить процесс обучения больших языковых моделей.
В этой статье мы расскажем о том, как можно организовать обучение больших языковых моделей на кластере и какие проблемы при этом возникают. Рассмотрим альтернативные методы ZeRo и FSDP, которые помогают организовать этот процесс. И объясним, чем YaFSDP отличается от них.

Всех приветствую, меня зовут Антон Рябых, работаю в Doubletapp. Вместе с коллегой Данилом Гальпериным мы написали статью про важный этап в процессе обучения нейронных сетей и получения необходимых нам результатов — оптимизацию модели. Зачем нужно оптимизировать модель, если и так все работает? Но как только вы начнете разворачивать модель на устройстве, которое будет ее обрабатывать, перед вами встанет множество проблем.
Более крупные модели занимают больше места для хранения, что затрудняет их распространение. Более крупные модели требуют больше времени для работы и могут потребовать более дорогого оборудования. Это особенно важно, если вы создаете модель для приложения, работающего в реальном времени.
Оптимизация моделей направлена на уменьшение размера моделей при минимизации потерь в точности и производительности.
Методы оптимизации
• Pruning — устранение части параметров нейронной сети.
• Quantization — уменьшение точности обрабатываемых типов данных.
• Knowledge distillation — обновление топологии исходной модели до более эффективной, с уменьшенным количеством параметров и более быстрым выполнением.
• Weight clustering — сокращение количества уникальных параметров в весах модели.
• OpenVino, TensorRT — фреймворки, с помощью которых можно оптимизировать модели.

Энкодер предложений (sentence encoder) – это модель, которая сопоставляет коротким текстам векторы в многомерном пространстве, причём так, что у текстов, похожих по смыслу, и векторы тоже похожи. Обычно для этой цели используются нейросети, а полученные векторы называются эмбеддингами. Они полезны для кучи задач, например, few-shot классификации текстов, семантического поиска, или оценки качества перефразирования.
Но некоторые из таких полезных моделей занимают очень много памяти или работают медленно, особенно на обычных CPU. Можно ли выбрать наилучший энкодер предложений с учётом качества, быстродействия, и памяти? Я сравнил 25 энкодеров на 10 задачах и составил их рейтинг. Самой качественной моделью оказался mUSE, самой быстрой из предобученных – FastText, а по балансу скорости и качества победил rubert-tiny2. Код бенчмарка выложен в репозитории encodechka, а подробности – под катом.
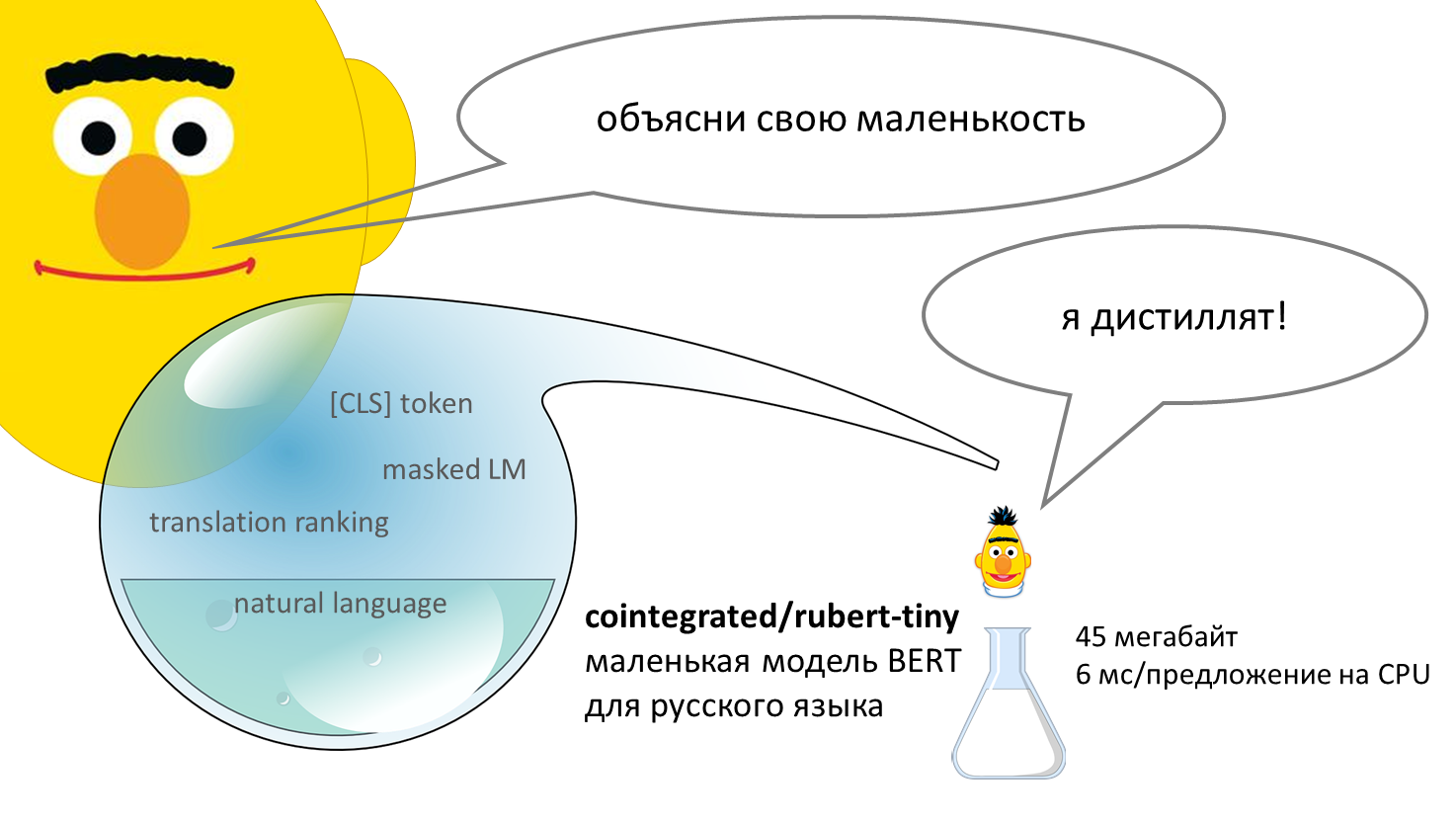
BERT – нейросеть, способная неплохо понимать смысл текстов на человеческом языке. Впервые появившись в 2018 году, эта модель совершила переворот в компьютерной лингвистике. Базовая версия модели долго предобучается, читая миллионы текстов и постепенно осваивая язык, а потом её можно дообучить на собственной прикладной задаче, например, классификации комментариев или выделении в тексте имён, названий и адресов. Стандартная версия BERT довольно толстая: весит больше 600 мегабайт, обрабатывает предложение около 120 миллисекунд (на CPU). В этом посте я предлагаю уменьшенную версию BERT для русского языка – 45 мегабайт, 6 миллисекунд на предложение. Она была получена в результате дистилляции нескольких больших моделей. Уже есть tinybert для английского от Хуавея, есть моя уменьшалка FastText'а, а вот маленький (англо-)русский BERT, кажется, появился впервые. Но насколько он хорош?

В этой статье я расскажу о реализации моего бесшовного модуля мультиязычности. Технологии, способной преодолевать языковые барьеры.
Виртуальный ассистент поддерживает 109 языков, понимает на каком языке к нему обратились и генерирует ответ уже на этом языке. И все это благодаря пайплайну на основе языковой модели LaBSE (Language-agnostic BERT Sentence Embedding) и фреймворка RASA.

Уже много времени прошло с момента публикации наших последних языковых моделей ruT5, ruRoBERTa, ruGPT-3. За это время много что изменилось в NLP. Наши модели легли в основу множества русскоязычных NLP-сервисов. Многие коллеги на базе наших моделей выпустили свои доменно-адаптированные решения и поделились ими с сообществом. Надеемся, что наша новая модель поможет вам поднять метрики качества, и ее возможности вдохновят вас на создание новых интересных продуктов и сервисов.
Появление ChatGPT и, как следствие, возросший интерес к методам обучения с подкреплением обратной связью от человека (Reinforcement Learning with Human Feedback, RLHF), привели к росту потребности в эффективных архитектурах для reward-сетей. Именно от «интеллекта» и продуктопригодности reward-модели зависит то, насколько эффективно модель для инструктивной диалоговой генерации будет дообучаться, взаимодействуя с экспертами. Разрабатывая FRED-T5, мы имели в виду и эту задачу, поскольку от качества её решения будет во многом зависеть успех в конкуренции с продуктами OpenAI. Так что если ваша команда строит в гараже свой собственный ChatGPT, то, возможно, вам следует присмотреться и к FRED’у. Мы уже ранее рассказывали в общих чертах об этой модели, а сейчас, вместе с публичным релизом, настало время раскрытия некоторых технических подробностей.
Появление новых, более производительных GPU и TPU открывает возможности для использования в массовых продуктах и сервисах всё более емких моделей машинного обучения. Выбирая архитектуру своей модели, мы целились именно в ее пригодность к массовому realtime-инференсу, поскольку время выполнения и доступное оборудование — это основные факторы, лимитирующие возможность создания массовых решений на основе нейросетевых моделей. Если вы уже используете в своем решении модель ruT5, то подменив ее на FRED-T5 вы, вероятно, получите заметное улучшение значений ваших целевых метрик. Конечно, в скором будущем мы обучим еще более емкие варианты модели FRED-T5 и проверим их возможности — мы планируем и дальнейшее развитие линейки энкодер-декодерных моделей для обработки русского языка.

Хабр, привет! Это снова Антон Разжигаев, аспирант Сколтеха и научный сотрудник лаборатории Fusion Brain в Институте AIRI, где мы продолжаем углубляться в изучение языковых моделей. В прошлый раз мы выяснили, что эмбеддинги трансформеров-декодеров сильно анизотропны. На этот раз я бы хотел рассказать об их удивительной линейности, ведь нашу статью про обнаруженный эффект («Your Transformer is Secretly Linear») несколько дней назад приняли на международную конференцию ACL!

Недавно аспиранты из MIT выпустили очень интересную статью про концептуально новый подход к проектированию наверное самого базового "кирпичика" нейронок - полносвязного слоя.
Постараюсь дать небольшое описание того, что происходит под каптом кана, при этом не превращая публикацию в учебник по матанализу