
На глаза попалась не особо позитивное сравнение Java vs GO. Тестирование большим числом пользователей.
Решил проверить, действительно ли так все не радужно с Go.
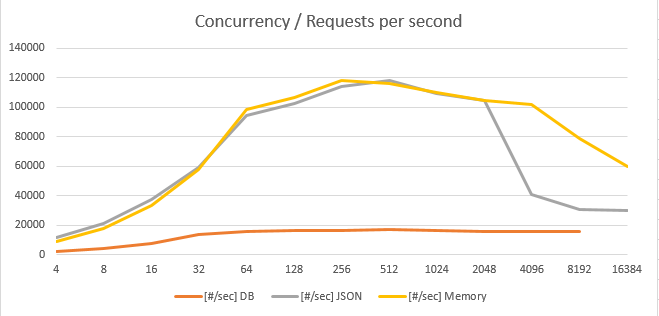
Забегая вперед скажу, что при кэшировании в памяти и формировании JSON "на лету" удалось получить до 120 000 [#/sec] на 8 физических ядра.
Базовый сценарий GET запроса:
- Если данные найдены в in memory кэше и они валидные, то формируем JSON из структуры
- Если данных в кэше нет, то ищем их в Bolt DB, если находим, то считываем готовый JSON
- Если данных нет в Bolt DB, то запрашиваем их из БД, сохраняем их в in memory кэше
- Данные в in memory кэше накапливаются в буферном канале, после накопления около 10000 элементов они сбрасываются единым save в Bolt DB
- Если данные в БД менялись (update / insert) то через pg_notify передается уведомление и данные в кэше помечаются как невалидные, при следующем обращении они считываются заново из БД
Под катом результаты тестирования, и код тестового стенда GitHub
Update 06.05.2020
Повилась возможность протестировать в облаке Oracle.
- стенд собран на 3 серверах — 8 Core Intel (16 virtual core), 120 Memory (GB), Oracle Linux 7.7
- локальные NVMe диски — 6.4 TB NVMe SSD Storage min 250k IOPS (4k block)
- локальная сеть между серверами — 8.2 Network Bandwidth (Gbps)
- в режиме прямого чтения из PostgreSQL — до 16 000 [get/sec], сoncurrency 1024, медиана 60 [ms]. Кажды Get запрашивает данные из двух таблиц общим размером 360 000 000 строк. Размер JSON 1800 байт.
- в режиме кэширования — до 100 000 — 120 000 [get/sec], сoncurrency 1024, медиана 2 [ms].
- на вставку в PostgreSQL — около 10 000 [insert/sec].
- при масштабировании с 2 до 4 и 8 Core, рост производительности практически линейный.









{kind=link}