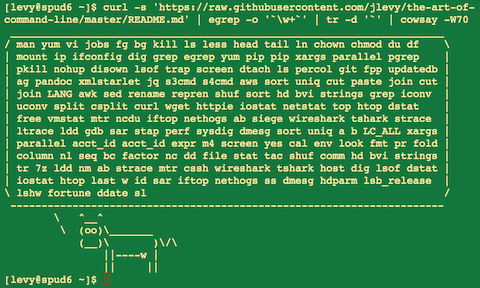
Если вы интересуетесь искусственным интеллектом и прочим распознаванием, то наверняка уже видели эту картинку:
 А если не видели, то это результаты Хинтона и Крижевского по классификации ImageNet-2010 глубокой сверточной сетью
А если не видели, то это результаты Хинтона и Крижевского по классификации ImageNet-2010 глубокой сверточной сетью
Давайте взглянем на ее правый угол, где алгоритм опознал леопарда с достаточной уверенностью, разместив с большим отрывом на втором и третьем месте ягуара и гепарда.
Это вообще довольно любопытный результат, если задуматься. Потому что… скажем,
вы знаете, как отличить одного большого пятнистого котика от другого большого пятнистого котика? Я, например, нет. Наверняка есть какие-то зоологические, достаточно тонкие различия, типа общей стройности/массивности и пропорций тела, но мы же все-таки говорим о компьютерном алгоритме, которые до сих пор допускают какие-то
вот такие достаточно глупые с человеческой точки зрения ошибки. Как он это делает, черт возьми? Может, тут что-то связанное с контекстом и фоном (леопарда вероятнее обнаружить на дереве или в кустах, а гепарда в саванне)? В общем, когда я впервые задумался над конкретно этим результатом, мне показалось, что это очень круто и мощно, разумные машины где-то за углом и поджидают нас, да здравствует deep learning и все такое.
Так вот, на самом деле все совершенно не так.

 ,
,  или даже
или даже



 Здравствуйте! Прочитав недавно статью
Здравствуйте! Прочитав недавно статью 

 Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.
Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.


{kind=link}