Когда-то мы
публиковали на Хабре курс по машинному обучению от Константина Воронцова из Школы анализа данных. Нам тогда
предлагали сделать из этого полноценный курс с домашними заданиями и разместить его на Курсере.
И сегодня мы хотим сказать, что наконец можем выполнить все эти пожелания. В январе на Курсере пройдёт курс, организованный совместно Яндексом (Школой анализа данных) и ВШЭ. Записаться на него можно уже сейчас:
www.coursera.org/learn/introduction-machine-learning.
 Сооснователь Coursera Дафна Коллер в офисе Яндекса
Сооснователь Coursera Дафна Коллер в офисе Яндекса
Курс продлится семь недель. Это означает, что по сравнению с ШАДовским двухсеместровым курсом он будет заметно упрощен. Однако в эти семь недель мы попытались вместить только то, что точно пригодится на практике, и какие-то базовые вещи, которые нельзя не знать. В итоге получился идеальный русскоязычный курс для первого знакомства с машинным обучением.
Кроме того, мы верим, что после прохождения курса у человека должна остаться не только теория в голове, но и скилл «в пальцах». Поэтому все практические задания построены вокруг использования библиотеки
scikit-learn (Python). Получается, что после прохождения нашего курса человек сможет сам решать задачи анализа данных, и ему будет проще развиваться дальше.
Под катом можно прочитать подробнее обо всех авторах курса и узнать его примерное содержание.

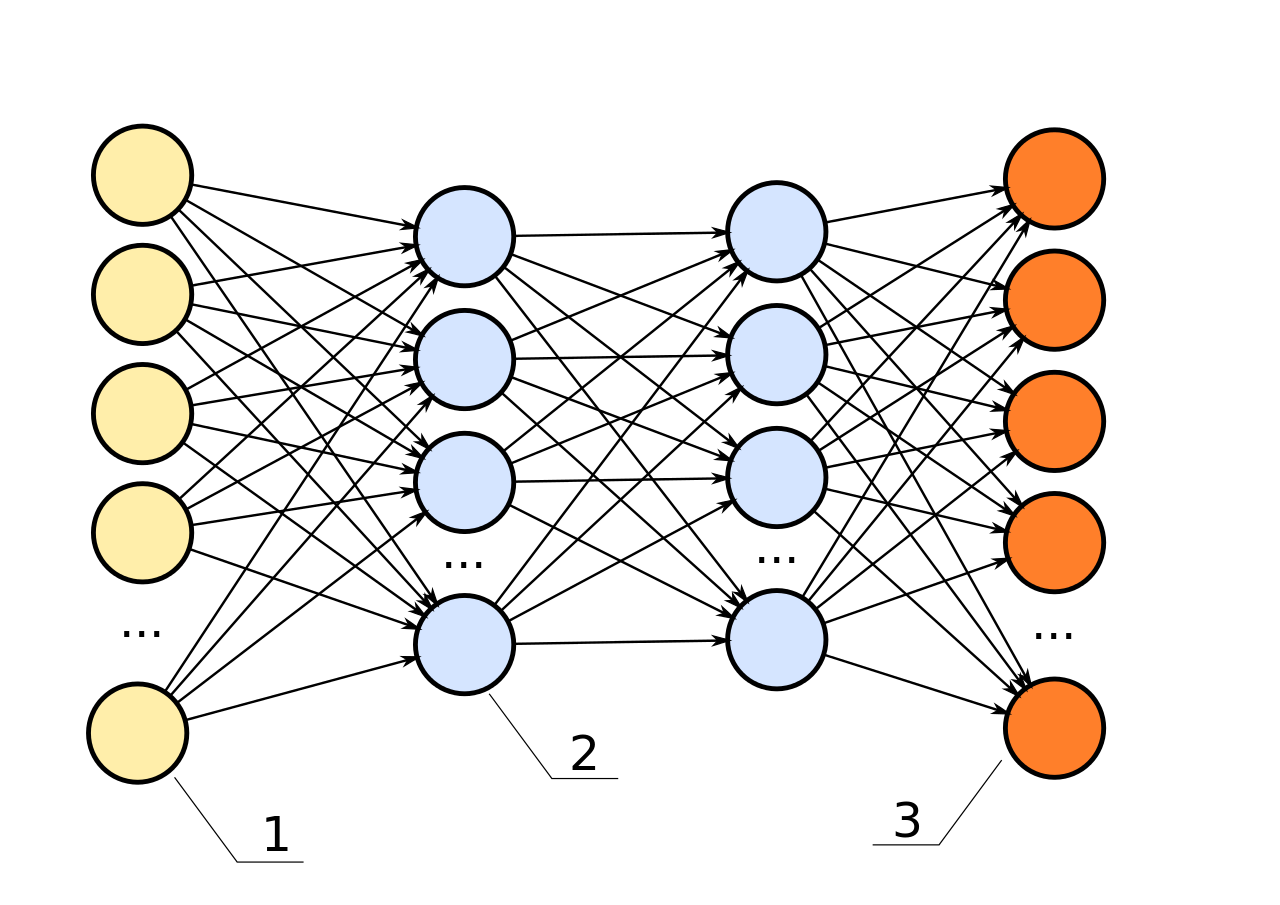
В первой (достаточно капитанской) части этой серии мы рассказали про базовые концепции MapReduce почему это плохо, почему это неизбежно, и как с этим жить в других средах разработки (если вы не про Си++ или Java). Во второй части мы-таки начали рассказывать про базовые классы реализации MapReduce на Caché ObjectScript, введя абстрактные интерфейсы и их первичные реализации.








 Добрый пятничный вечер, уважаемые читатели Хабра!
Добрый пятничный вечер, уважаемые читатели Хабра!
{kind=link}