
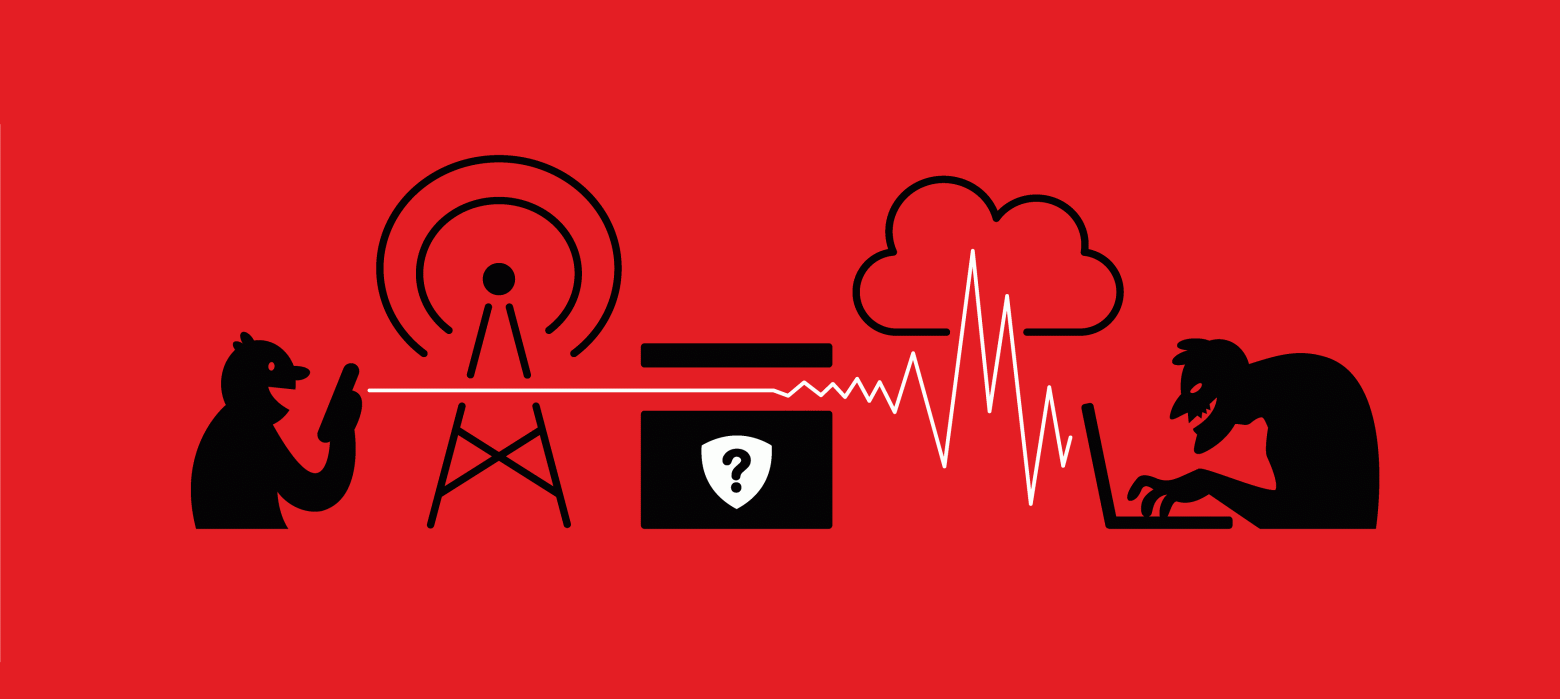
В статьях о SS7 и Diameter улавливаются панические нотки: протоколы сотовой связи похожи на решето, от них нельзя взять и отказаться, их не исправить. И все же, телеком-апокалипсис до сих пор не случился. Сотовые сети работают, но каким образом?
Мы проверили, как и насколько эффективно сотовые операторы защищают сигнальные сети от хакеров. Один из мобильных операторов, работающих на территории СНГ, заказал две серии атак на свою сеть. Мы провели пентест до и после внедрения некой продвинутой защиты и готовы поделиться инсайдами.
Думаю, широкой публике будет интересно узнать, какие атаки возможны на практике, и что делать для защиты личных данных. Специалисты увидят в этом посте рассказ об одном из первых black-box тестов сигнальных сетей в СНГ.





 Single responsibility principle, он же принцип единой ответственности,
Single responsibility principle, он же принцип единой ответственности,


