Я уже написал здесь много статей на тему прокси-протоколов и прокси-клиентов, которые очень сложно детектировать и заблокировать, и которые используют пользователи в Китае, Иране, Ираке, Туркменистане, и теперь вот в России (мы здесь в отличной компании, правда?). Но довольно часто мне в комментариях писали, мол, это все отлично, но мне нужен именно VPN для целей именно VPN - доступа в частные локальные сети, либо для соединения клиентов между собой, и желательно так, чтобы его не заблокировали обезьяны с гранатой. Поэтому сегодня мы поговорим именно о VPN.
Классические OpenVPN, Wireguard и IPSec отметаем сразу - их уже давно умеют блокировать и блокировали не раз. Модифицированный Wireguard от проекта Amnezia под названием AmneziaWG — отличная задумка, но есть одно но...





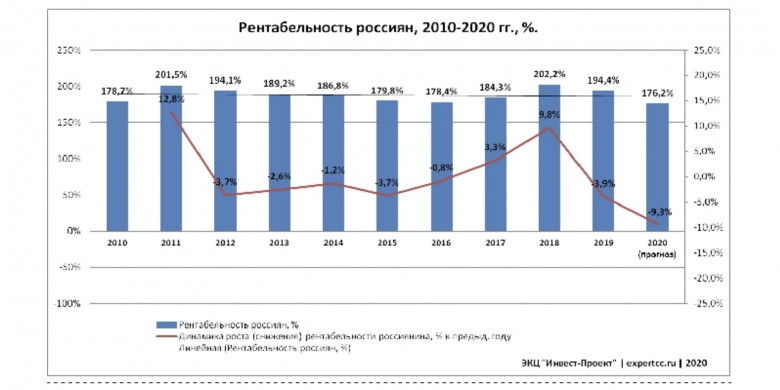
 Проблемы контроля версий баз данных и миграций между версиями уже не раз поднимались как на Хабре (
Проблемы контроля версий баз данных и миграций между версиями уже не раз поднимались как на Хабре (


 Иллюстрация David Parkins из статьи Nature 561, 167-169 (2018).
Иллюстрация David Parkins из статьи Nature 561, 167-169 (2018).