Вы говорите про явление Grokking. Да, похоже, что это явление и компрессия репрезентаций очень плотно связаны. Схожая интуиция была в статье про OmniGrok. Было бы очень интересно посмотреть что происходит с внутренней размерностью при переходе от оверфита к генерализации, предположу что там будет "ступенька" на графике внутренней размерности.
исследуя связь между обучаемостью и «сжатием», которое включает в себя поиск способа отображения характерных признаков большого набора данных на меньший набор...
Когда завели речь о сжатии, то вспомнилась проблема невычислимости Колмогоровской сложности и связанный с ней принцип Минимальный длины сообщения (… который, «в статистическом и индуктивном выводе и машинном обучении был разработан Уоллесом (англ. C. S. Wallace) и Болтоном (англ. D. M. Boulton) в 1968 году.»)
«Эта связь между сжатием и обобщением действительно фундаментальна в вопросе понимания процесса обучения.» — говорит Иегудаев
И и как справедливо указано выше,
нерешенная ≠ неразрешимая
то и невычислимая ≠ «невозможно вычислять»
т.е. просто невозможно в общем случае дать ответ на вопрос «а есть ли какой-то самый компактный способ представить информацию», что не исключает возможности какие-то способы находить.
Эта проблема, действительно, очень неплохо коррелирует с обучением: даже когда, казалось бы, нам известно «всё» про изучаемый предмет — не лишним будет всегда оставлять допущение, что «что-то про явление мы всё ещё не знаем». И это какое-то фундаментальное свойство природы, если нам заведомо неизвесна полная аксиоматика теории, которая это явление описывает.
Ещё из больших плюсов ScriptableObject можно назвать Addressable Assets — SO c данными (и ссылками) очень легко можно хранить и изменять удалённо (Unity сама загрузит их в Runtime), при этом не нужно писать свои серверные скрипты, самому проверять версию данных и так далее — Unity всё сделает за Вас.
Все эти Message/Signal Bus это, конечно, замечательно decoupling, тестируемость и так далее по списку, но есть одно большое НО. Я поддерживал два проекта с подобной архитектурой и видел ещё несколько подобных. У них есть одна большая проблема, в них абсолютно невозможно разобраться (по крайней мере эта проблема была на всех проектах, с которыми я работал, возможно, кто-то готовит это лучше):
Cигналы летят чёрти куда и чёрти когда, слишком высокая когнитивная нагрузка на работу с таким кодом, особенно, если его писал не ты (тем кто это писал, конечно же, всё нравится)
Невозможно понять что нужно слушать/триггерить, документация далеко не всегда есть на проекте, опять же нужно идти и смотреть по коду. С интерфейсом для View, у которой есть понятный интерфейс с обычными событиями работать в разы проще.
Сигналы вообще ничего не гарантируют — не гарантирует, что View точно триггерит такой сигнал, не гарантирует что он значит то, что ты ждёшь.
Невозможно управлять порядком, в котором отрабатывают подписчики (если их несколько). В местах, где это необходимо приложение начинает обрастать костылями, что опять-таки увеличивает когнитивную нагрузку.
Разработчики слишком увлекаются сигналами и вместо того, чтобы вернуть какой-то результат триггерят сигнал (апофеоз такого подхода кода вида 'void Login()', а как получить результат — лезь в код и ищи сам)
Как продолжение двух предыдущих пунктов, возникают ситуации, когда код настолько завязываются на сигналы, что вся гибкость подхода испаряется.
Меня тоже сначала привлекал такой подход, но поработав с парой проектов в подобном стиле я понял, что оно того не стоит. Может квалифицированные разработчики и могут приготовить это всё хорошо, но то, что видел я, вгоняет исключительно в депрессию.
Скорее всего они использую похожий на метод k-quant, который есть в llama.cpp. Можно почитать здесь, что это https://github.com/ggerganov/llama.cpp/pull/1684 Если коротко, - то это лоботомия модели, чтобы ускорить её и уменьшить потребление ресурсов, а точнее иметь возможность полностью поместить её в VRAM, чтобы использовать на 100% GPU.
UPD: И вероятно так и есть, я тоже заметил одну странность, иногда ChatGPT очень быстро пишет текст, но который буквально просто набор слов без какого-то связного смысла, а вот если нажать перегенерировать он начинает уже долго выдавать ответ, но на порядок лучше. Как раз таки k-quant в этом схожи, если сравнить Q2 и Q6 методы.
В Питоне есть незаслуженно забытый TypedDict, позволяющий фиксировать по типам содержимое словаря. Хорош, чтобы вернуть из функции 3-4 разных значения, но при этом dataclass делать не хочется, так как больше нигде они пачкой не идут.
Попробовал — унылая моделька с фильтрами и цензурой. Тогда уж чатгпт лучше. А вот в альпаке вообще никакой цензуры нет, она ответит абсолютно на что угодно
Автору оригинальной статьи хорошо бы освоить технику инверсии проверок, когда не if (...) { <что-то важное> }, а if !(...) return; <что-то важное>. Очень помогает бороться с цикломатической сложностью.
Проблема с JPA в том, что он может внезапно накинуть 2-3 запроса сверху, в зависимости от графа сущностей. Там, где кажется, что должен быть один запрос, легко может быть пять.
Есть неплохая библиотека, чтобы защититься от такого, она позволяет убедиться, что такой-то запрос выполняет 2 селекта, а не 10 https://github.com/quick-perf/quickperf
зачем vba? эти самые ип сейчас активно осваивают noops инструменты. Берут условный zapier - и связывают эксель таблицу, почту, слак и гугл док в цепочку. Да, это стоит денег. Но зато позволяет быстро тяп-ляп автоматизировать бизнес процессы и решить свои задачи. И отложить вопрос "сделать идеально" на потом.
Просто напомню, если вдруг есть те, кто готов/вынужден за такие цены покупать или просто нужна видеокарта. На www.computeruniverse.net/ru, сейчас скидки 5-7% и цены, например, такие:
RX 6500 XT (чуть слабее 3050, но памяти 4гб) стоит 20к + доставка и растаможка (~2.5к)
RX 6600 (мощнее 3050, на уровне 3060, но памяти 8гб) стоит 39к + доставка и растаможка (~6.5к)
Даже с учетом доставки и растаможки (сейчас это просто оплата онлайн, либо прямо на почте, всё что выше 200 евро дополнительные 15%) это будет дешевле.
Я честно стараюсь поменьше без приглашений врываться и евангелировать за раст) Но, если уж на то пошло, Amethyst как движок давно уже не сильно живой был, а недавно совсем помер. Я бы из претендующих на масштабность чисто растовых движков советовал смотреть на Bevy или rg3d - только сразу предупреждаю, что это все еще штуки в первую очередь для энтузиастов, слишком все сырое.
Проблема с медленной вставкой решается заданием ограничений (документация Neo4j).
Например, если для узлов типа :Person указать, что поле name является ключевым, то запросы на запись будут выполняться быстрее на несколько порядков. У меня при добавлении ограничений скорость записи увеличивалась более чем в 200 раз.
Например, можно задавать такие ограничения:
1) если единственное свойство (name) определяет уникальность узлов, то: CREATE CONSTRAINT ON (p:Person) ASSERT p.name IS UNIQUE
2) если таких свойств несколько (name и fam), то: CREATE CONSTRAINT ON (n:Person) ASSERT (n.name, n.fam) IS NODE KEY

Вы говорите про явление Grokking. Да, похоже, что это явление и компрессия репрезентаций очень плотно связаны. Схожая интуиция была в статье про OmniGrok. Было бы очень интересно посмотреть что происходит с внутренней размерностью при переходе от оверфита к генерализации, предположу что там будет "ступенька" на графике внутренней размерности.
Нет, вызывать явно ничего не нужно
Код выше сам сгенерирует то, что на тамошней терминологии называется backed field. И сгенерирует геттер и сеттер. Либо можно в явном виде:
Использовать можно так:
Когда завели речь о сжатии, то вспомнилась проблема невычислимости Колмогоровской сложности и связанный с ней принцип Минимальный длины сообщения (… который, «в статистическом и индуктивном выводе и машинном обучении был разработан Уоллесом (англ. C. S. Wallace) и Болтоном (англ. D. M. Boulton) в 1968 году.»)
И и как справедливо указано выше,
то и невычислимая ≠ «невозможно вычислять»
т.е. просто невозможно в общем случае дать ответ на вопрос «а есть ли какой-то самый компактный способ представить информацию», что не исключает возможности какие-то способы находить.
Эта проблема, действительно, очень неплохо коррелирует с обучением: даже когда, казалось бы, нам известно «всё» про изучаемый предмет — не лишним будет всегда оставлять допущение, что «что-то про явление мы всё ещё не знаем». И это какое-то фундаментальное свойство природы, если нам заведомо неизвесна полная аксиоматика теории, которая это явление описывает.
Я ничего не понял из того что вы сейчас сказали, но просто сравните с каноническими диаграммами:
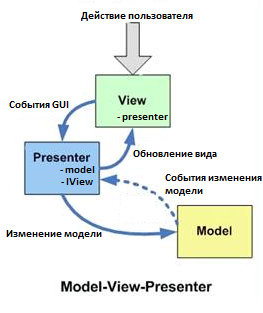
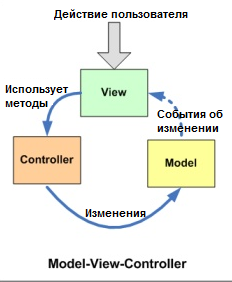
и
У вас не три равноправных компонента как в MVC, у вас два компонента + тонкая прослойка между ними, то есть MVP.
Все эти Message/Signal Bus это, конечно, замечательно decoupling, тестируемость и так далее по списку, но есть одно большое НО. Я поддерживал два проекта с подобной архитектурой и видел ещё несколько подобных. У них есть одна большая проблема, в них абсолютно невозможно разобраться (по крайней мере эта проблема была на всех проектах, с которыми я работал, возможно, кто-то готовит это лучше):
Меня тоже сначала привлекал такой подход, но поработав с парой проектов в подобном стиле я понял, что оно того не стоит. Может квалифицированные разработчики и могут приготовить это всё хорошо, но то, что видел я, вгоняет исключительно в депрессию.
Скорее всего они использую похожий на метод k-quant, который есть в llama.cpp. Можно почитать здесь, что это https://github.com/ggerganov/llama.cpp/pull/1684
Если коротко, - то это лоботомия модели, чтобы ускорить её и уменьшить потребление ресурсов, а точнее иметь возможность полностью поместить её в VRAM, чтобы использовать на 100% GPU.
UPD: И вероятно так и есть, я тоже заметил одну странность, иногда ChatGPT очень быстро пишет текст, но который буквально просто набор слов без какого-то связного смысла, а вот если нажать перегенерировать он начинает уже долго выдавать ответ, но на порядок лучше. Как раз таки k-quant в этом схожи, если сравнить Q2 и Q6 методы.
В Питоне есть незаслуженно забытый TypedDict, позволяющий фиксировать по типам содержимое словаря. Хорош, чтобы вернуть из функции 3-4 разных значения, но при этом dataclass делать не хочется, так как больше нигде они пачкой не идут.
Попробовал — унылая моделька с фильтрами и цензурой. Тогда уж чатгпт лучше. А вот в альпаке вообще никакой цензуры нет, она ответит абсолютно на что угодно
Сделал аналогичное решение для личного использования, но на tts Silero. Взгляните в его сторону, некоторые голоса потрясающи.
А как же https://github.com/go-kratos/kratos ?
Автору оригинальной статьи хорошо бы освоить технику инверсии проверок, когда не
if (...) { <что-то важное> }, аif !(...) return; <что-то важное>. Очень помогает бороться с цикломатической сложностью.Проблема с JPA в том, что он может внезапно накинуть 2-3 запроса сверху, в зависимости от графа сущностей. Там, где кажется, что должен быть один запрос, легко может быть пять.
Есть неплохая библиотека, чтобы защититься от такого, она позволяет убедиться, что такой-то запрос выполняет 2 селекта, а не 10 https://github.com/quick-perf/quickperf
зачем vba? эти самые ип сейчас активно осваивают noops инструменты. Берут условный zapier - и связывают эксель таблицу, почту, слак и гугл док в цепочку. Да, это стоит денег. Но зато позволяет быстро тяп-ляп автоматизировать бизнес процессы и решить свои задачи. И отложить вопрос "сделать идеально" на потом.
RX 6500 XT (чуть слабее 3050, но памяти 4гб) стоит 20к + доставка и растаможка (~2.5к)
RX 6600 (мощнее 3050, на уровне 3060, но памяти 8гб) стоит 39к + доставка и растаможка (~6.5к)
Даже с учетом доставки и растаможки (сейчас это просто оплата онлайн, либо прямо на почте, всё что выше 200 евро дополнительные 15%) это будет дешевле.
Я честно стараюсь поменьше без приглашений врываться и евангелировать за раст)
Но, если уж на то пошло, Amethyst как движок давно уже не сильно живой был, а недавно совсем помер. Я бы из претендующих на масштабность чисто растовых движков советовал смотреть на Bevy или rg3d - только сразу предупреждаю, что это все еще штуки в первую очередь для энтузиастов, слишком все сырое.
Например, если для узлов типа
:Personуказать, что поле name является ключевым, то запросы на запись будут выполняться быстрее на несколько порядков. У меня при добавлении ограничений скорость записи увеличивалась более чем в 200 раз.Например, можно задавать такие ограничения:
1) если единственное свойство (
name) определяет уникальность узлов, то:CREATE CONSTRAINT ON (p:Person) ASSERT p.name IS UNIQUE2) если таких свойств несколько (
nameиfam), то:CREATE CONSTRAINT ON (n:Person) ASSERT (n.name, n.fam) IS NODE KEY