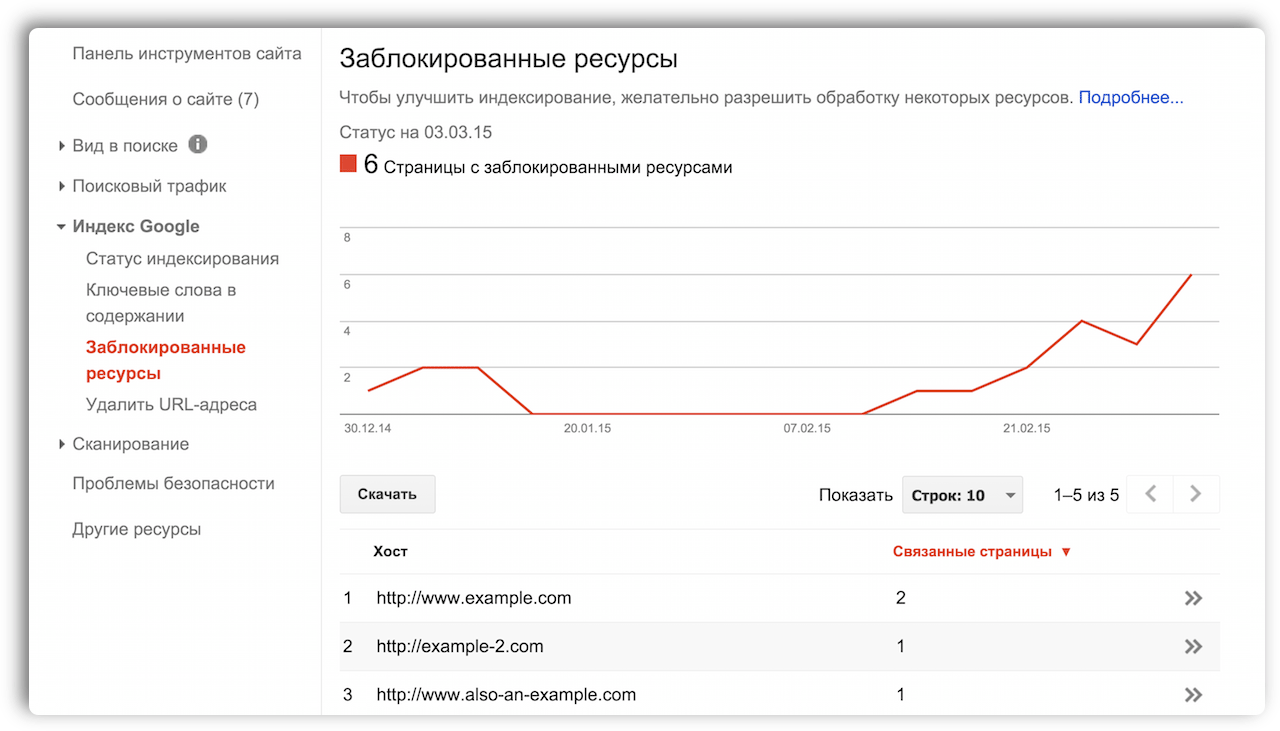
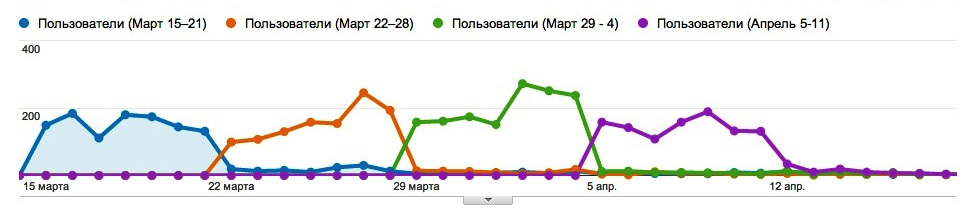
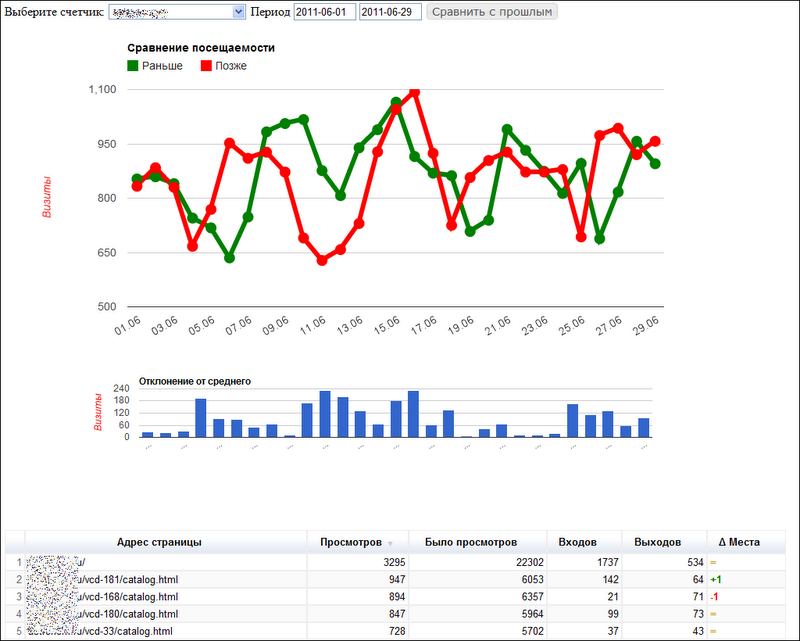
Прошлой осенью, вернувшись из отпуска, я обнаружил, что Дехана, наш Product Manager в
UserVoice, заменила мой любимый «Roadmap» в Google Docs на доску
Trello.
Моя первоначальная реакция на такие перемены была отнюдь не положительной. Проблема заключалась не в самом Trello, а в том, как мы им пользовались. Trello – это ОЧЕНЬ открытый проект. Не существует единственного “правильного” способа работы в Trello, поэтому, чтобы чувствовать себя в нем как дома, вам потребуется время для настройки «под себя».
Итак, после долгих экспериментов, нам, кажется, удалось получить полностью устраивающую нас систему работы, и мы решили, что стоит поделиться ею со всеми. Этот пост будет длиннее, чем обычно, и если вы далеки от темы веб-разработки, он может показаться вам немного скучным. Если вы решите сразу перейти к части поста, посвящённой полученным урокам, я, несомненно, расстроюсь, но обижаться не стану.


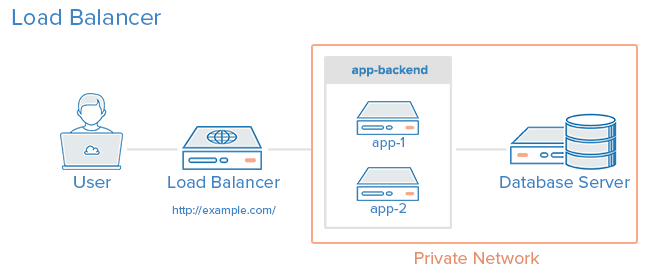
 Кевин Поулсен, редактор журнала WIRED, а в детстве blackhat хакер Dark Dante, написал книгу про «
Кевин Поулсен, редактор журнала WIRED, а в детстве blackhat хакер Dark Dante, написал книгу про «![[Аристотель]](https://habrastorage.org/getpro/habr/post_images/101/328/cf0/101328cf0c1248b20ec5b675fc43a677.jpg) «Начало — более чем половина всего».
«Начало — более чем половина всего».