Coвсем недавно Google сделал доступной для всех свою библиотеку для машинного обучения, под названием TensorFlow. Для нас это оказалось интересно еще и тем, что в состав входят самые современные нейросетевые модели для обработки текста, в частности, обучения типа “последовательность-в-последовательность” (sequence-to-sequence learning). Поскольку у нас есть несколько проектов, связанных с этой технологией, то мы решили, что это отличная возможность перестать изобретать велосипед (наверное пора уже) и быстро улучшить результаты. Представив себе довольные лица клиентов, мы приступили к работе. И вот что из этого получилось…

@klimrodread-only
User
FizzBuzz на TensorFlow
4 min
Translation
интервьюер: Приветствую, хотите кофе или что-нибудь еще? Нужен перерыв?
я: Нет, кажется я уже выпил достаточно кофе!
интервьюер: Отлично, отлично. Как вы относитесь к написанию кода на доске?
я: Я только так код и пишу!
интервьюер: ...
я: Это была шутка.
интервьюер: OK, итак, вам знакома задача "fizz buzz"?
я: ...
интервьюер: Это было да или нет?
я: Это что-то вроде "Не могу поверить, что вы меня об этом спрашиваете."
интервьюер: OK, значит, нужно напечатать числа от 1 до 100, только если число делится нацело на 3, напечатать слово "fizz", если на 5 — "buzz", а если делится на 15, то — "fizzbuzz".
я: Я знаю эту задачу.
интервьюер: Отлично, кандидаты, которые не могут пройти эту задачу, у нас не сильно уживаются.
я: ...
интервьюер: Вот маркер и губка.
я: [задумался на пару минут]
интервьюер: Вам нужна помощь, чтобы начать?
я: Нет, нет, все в порядке. Итак, начнем с пары стандартных импортов:
import numpy as np
import tensorflow as tfинтервьюер: Эм, вы же правильно поняли проблему в fizzbuzz, верно?
я: Так точно. Давайте обсудим модели. Я думаю тут подойдет простой многослойный перцептрон с одним скрытым слоем.
Spark Summit 2016: обзор и впечатления
10 min

В июне прошло одно из самых крупных мероприятий мира в сфере big data и data science — Spark Summit 2016 в Сан-Франциско. Конференция собрала две с половиной тысячи человек, включая представителей крупнейших компаний (IBM, Intel, Apple, Netflix, Amazon, Baidu, Yahoo, Cloudera и так далее). Многие из них используют Apache Spark, включая контрибьюторов в open source и вендоров собственных разработок в big data/data science на базе Apache Spark.
Мы в Wrike активно используем Spark для задач аналитики, поэтому не могли упустить возможности из первых рук узнать, что происходит нового на этом рынке. С удовольствием делимся своими наблюдениями.
Deep Learning — что же делать, кого бить
3 min
Нигде, наверно, нет такой насущной необходимости в синергии знаний разных областей науки — как в области машинного обучения и Deep Learning. Достаточно открыть капот TensorFlow и ужаснуться — огромное количество кода на python, работающее с тензорами внутри… C++, вперемешку с numpy, для выкладки в продакшн требующее чуток покодить «на плюсах», вприкуску с bazel (это так волнует, всю жизнь мечтал об этом!). И другая крайность — ребята из Deeplearning4j прокляли python к чертовой матери и вращают тензоры на старой и доброй java. Но дальше всех ушли, похоже, студенты из университета Нью-Йорка — люди, причем не только студенты, причем давно и серьезно жгут на Luajit + nginx (аминь по католически). Ситуация осложняется недавним демаршем Google DeepMind в отношении «дедушки torch»: все проекты переводят на свой внутренний движок, родившийся из DistBelief.
Полнейший хаос и бардак.
Полнейший хаос и бардак.
MapReduce или подсчеты за пределами возможностей памяти и процессора (попробую без зауми)
8 min
Давно хотел рассказать про MapReduce, а то как ни взгляшешь на подобное — такая заумь, что просто ужас берет, а на самом деле очень простой и полезный подход для многих целей. И реализовать самому — не так уж и сложно.
Сразу скажу — топик — для тех, кто не разобрался что такое MapReduce. Для тех, кто разобрался — полезного тут ничего не будет.
Начнем с того как собственно родилась лично у меня идея MapReduce (хотя я и не знал, что он так называется, и, разумеется, пришла она мне куда позже чем Гугловсцам).
Сначала опишу как она рождалась (подход был неправильный), а потом как надо правильно делать.
А родилась она, как и, наверное, везде — для подсчета частоты слов, когда обычной памяти не хватает (подсчет частоты всех слов в Википедии). Вместо слова «частота» тут скорее должно быть «количество вхождений», но для простоты оставлю «частота».
В самом простом случае мы можем завести хеш (dict, map, hash, ассоциативный массив, array() в PHP) и считать в нем слова.
Но что делать когда память под хеш кончится, а мы посчитали только одну сотую всех слов?
Сразу скажу — топик — для тех, кто не разобрался что такое MapReduce. Для тех, кто разобрался — полезного тут ничего не будет.
Начнем с того как собственно родилась лично у меня идея MapReduce (хотя я и не знал, что он так называется, и, разумеется, пришла она мне куда позже чем Гугловсцам).
Сначала опишу как она рождалась (подход был неправильный), а потом как надо правильно делать.
Как посчитать все слова в Википедии (неправильный подход)
А родилась она, как и, наверное, везде — для подсчета частоты слов, когда обычной памяти не хватает (подсчет частоты всех слов в Википедии). Вместо слова «частота» тут скорее должно быть «количество вхождений», но для простоты оставлю «частота».
В самом простом случае мы можем завести хеш (dict, map, hash, ассоциативный массив, array() в PHP) и считать в нем слова.
$dict['word1'] += 1Но что делать когда память под хеш кончится, а мы посчитали только одну сотую всех слов?
Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce
6 min
Tutorial

Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
Создание собственного приложения для обработки графов в Giraph
7 min

Be my friend by oosDesign
Перед крупными интернет-компаниями часто встают такие сложные задачи, как обработка больших данных и анализ графов социальных сетей. Помогают в их решении фреймворки, но сперва необходимо проанализировать возможные варианты и выбрать подходящий. В лаборатории при Техносфере Mail.Ru мы изучаем эти вопросы на реальных примерах из проектов Mail.Ru Group (myTarget, Поиск Mail.Ru, Антиспам). Задачи могут быть как сугубо практические, так и с исследовательской составляющей. По мотивам одной из таких задач и появилась эта статья.
Во время сборки и запуска своего первого проекта на Giraph сотрудники лаборатории анализа данных Техносферы Mail.Ru столкнулись с рядом проблем, в связи с чем родилась идея написать краткий туториал, как же собрать и запустить свой первый Giraph-проект.
В этой статье мы расскажем, как создавать свои приложения под фреймворк Giraph, который является надстройкой над популярной системой обработки данных Hadoop.
Сообщество экспертов, совместная работа над проектами и другие обновления платформы FlyElephant
2 min

Команда FlyElephant рада анонсировать релиз платформы FlyElephant 2.0, в который вошли следующие обновления: внутреннее сообщество экспертов, совместная работа над проектами, публичные задачи, поддержка Docker и Jupyter, новое хранилище данных и работа с HPC кластерами.
FlyElephant — платформа для исследователей данных, инженеров и ученых, которая предоставляет готовую вычислительную инфраструктуру для проведения высокопроизводительных вычислений и рендеринга, помогает находить партнеров и совместно работать над проектами, а также управлять всеми ресурсами из одного места. Платформа состоит из 3 основных компонентов:
- Compute. Быстрый доступ к вычислительному кластеру в облаке с нужным программным обеспечением или HPC кластеру, а также автоматизация проведения расчетов.
- Collaborate. Совместная работа над проектами и сообщество экспертов, где можно найти партнеров, чтобы вместе решить сложную задачу или получить квалифицированную консультацию.
- Manage. Управление лицензиями, программным обеспечением, вычислительными ресурсами, шаблонами, алгоритмами, данными и результаты в одном месте.
Среди нововведений отметим следующие:
Яндекс открывает ClickHouse
14 min
Сегодня внутренняя разработка компании Яндекс — аналитическая СУБД ClickHouse, стала доступна каждому. Исходники опубликованы на GitHub под лицензией Apache 2.0.

ClickHouse позволяет выполнять аналитические запросы в интерактивном режиме по данным, обновляемым в реальном времени. Система способна масштабироваться до десятков триллионов записей и петабайт хранимых данных. Использование ClickHouse открывает возможности, которые раньше было даже трудно представить: вы можете сохранять весь поток данных без предварительной агрегации и быстро получать отчёты в любых разрезах. ClickHouse разработан в Яндексе для задач Яндекс.Метрики — второй по величине системы веб-аналитики в мире.
В этой статье мы расскажем, как и для чего ClickHouse появился в Яндексе и что он умеет; сравним его с другими системами и покажем, как его поднять у себя с минимальными усилиями.
ClickHouse позволяет выполнять аналитические запросы в интерактивном режиме по данным, обновляемым в реальном времени. Система способна масштабироваться до десятков триллионов записей и петабайт хранимых данных. Использование ClickHouse открывает возможности, которые раньше было даже трудно представить: вы можете сохранять весь поток данных без предварительной агрегации и быстро получать отчёты в любых разрезах. ClickHouse разработан в Яндексе для задач Яндекс.Метрики — второй по величине системы веб-аналитики в мире.
В этой статье мы расскажем, как и для чего ClickHouse появился в Яндексе и что он умеет; сравним его с другими системами и покажем, как его поднять у себя с минимальными усилиями.
Особенности распределения фонда оплаты труда в больших предприятиях РФ
33 min
Оказывается, в свободном доступе есть интересная информация от HeadHunter о повышении фонда оплаты труда (ФОТ) в 2015 году. Со страницы проекта "Банк данных заработных плат" идет ссылка "Сравнивайте зарплаты вашей компании с рынком".
Прямая ссылка на pdf: Зарплаты в России. Итоги 2015 года.

Как видите, между топ-менеджментом, который смог повысить себе зарплату на уровень выше официальной инфляции, и остальными сотрудниками, существует четкая граница.
Вы скажете – что же удивительного в том, что топ-менеджмент имеет возможность управлять своей зарплатой, а остальные нет.
И вообще, многим придут на ум уже затертые шаблоны:
Но эти выводы и советы слишком уж лежат на поверхности.
We need to go deeper.
Давайте посмотрим, насколько же глубока эта не кроличья нора…
Прямая ссылка на pdf: Зарплаты в России. Итоги 2015 года.
Как видите, между топ-менеджментом, который смог повысить себе зарплату на уровень выше официальной инфляции, и остальными сотрудниками, существует четкая граница.
Вы скажете – что же удивительного в том, что топ-менеджмент имеет возможность управлять своей зарплатой, а остальные нет.
И вообще, многим придут на ум уже затертые шаблоны:
- Надо не завидовать, а больше работать, и станешь таким же высокооплачиваемым топ-менеджером.
- Не нравится – уходи и работай на себя / аутсорсь за валюту на западные компании / переезжай в другие страны.
Но эти выводы и советы слишком уж лежат на поверхности.
We need to go deeper.
Давайте посмотрим, насколько же глубока эта не кроличья нора…
Эксперимент: Что гипотеза случайного блуждания говорит о прогнозировании финансовых рынков
9 min
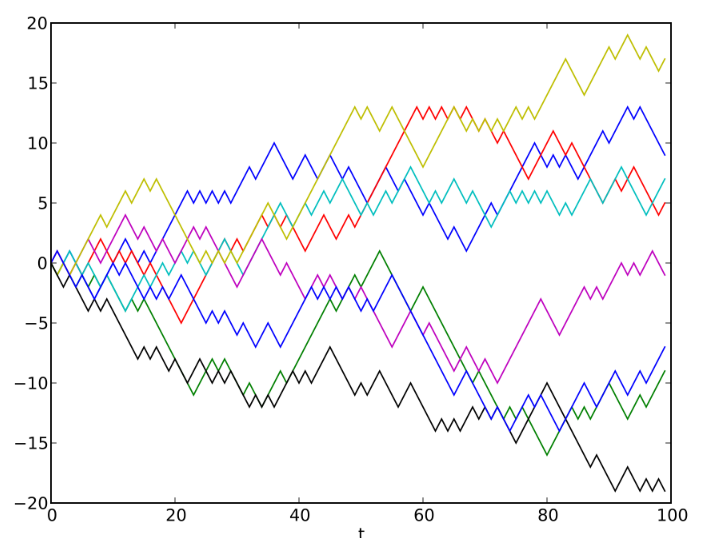
В блоге на Хабре и аналитическом разделе нашего сайта мы много пишем об алгоритмах и инструментах прогнозирования движения на финансовы рынках. При этом многие наблюдатели считают, что подобные занятия сродни игре в казино — на бирже все случайно, а значит ничего нельзя спрогнозировать. Количественный аналитик хедж-фонда NMRQL Стюарт Рид опубликовал на сайте Turing Finance результаты исследования, в ходе которого использовал гипотезу случайного блуждания, пытаясь подтвердить или опровергнуть тезис о случайности финансовых рынков. Мы представляем вашему вниманию основные мысли этого материала.
Лекции Технопарка: мастер-класс Алексея Рыбака «Про то, что я бы хотел, чтобы мне рассказали, пока я учился»
25 min
Сегодня мы начинаем серию публикаций новых мастер-классов Технопарка. И первая из них — мастер-класс Алексея Рыбака на свободную тему, в котором он поделился со студентами соображениями о том, чем работа в реальной жизни отличается от учебы. Видео смотрите на нашем сайте, а адаптированную расшифровку — ниже.
Я работаю в компании Badoo достаточно долго, и на моих глазах этот проект из маленького стартапа превратился в большую компанию с сотнями инженеров и тысячным парком серверов, распределенных по нескольким дата-центрам. Сейчас я хотел бы рассказать о том, что считаю достаточно интересным для студентов, выбравших профессию программиста.
Не буду рассказывать о современных трендах и о том сегодня важно и нужно — об этом вам многие могут рассказать. Вместо этого поговорим о некой общечеловеческой адаптации бывших студентов к работе, которую каждый человек проходит в течение одного, а порой и нескольких лет. Процесс этот достаточно болезненный, и далеко не все «правильно» проходят эту адаптацию. Именно эта тема должна больше интересовать студентов и выпускников, чем какие-то модные технологические фишки. Хотя о них мы тоже поговорим, когда коснемся темы самообразования.

Я работаю в компании Badoo достаточно долго, и на моих глазах этот проект из маленького стартапа превратился в большую компанию с сотнями инженеров и тысячным парком серверов, распределенных по нескольким дата-центрам. Сейчас я хотел бы рассказать о том, что считаю достаточно интересным для студентов, выбравших профессию программиста.
Не буду рассказывать о современных трендах и о том сегодня важно и нужно — об этом вам многие могут рассказать. Вместо этого поговорим о некой общечеловеческой адаптации бывших студентов к работе, которую каждый человек проходит в течение одного, а порой и нескольких лет. Процесс этот достаточно болезненный, и далеко не все «правильно» проходят эту адаптацию. Именно эта тема должна больше интересовать студентов и выпускников, чем какие-то модные технологические фишки. Хотя о них мы тоже поговорим, когда коснемся темы самообразования.
Джефф Дин из компании Google — это Чак Норрис нашего времени
4 min
 «Джефф Дин компилирует и запускает свой код перед коммитом, но только чтобы проверить на баги компилятор и CPU», — вот один из множества шуточных фактов о Джеффе Дине.
«Джефф Дин компилирует и запускает свой код перед коммитом, но только чтобы проверить на баги компилятор и CPU», — вот один из множества шуточных фактов о Джеффе Дине.Джефф Дин считается кем-то вроде Чака Норриса. Отличие только в том, что он вовсе не герой боевиков, а инженер-программист компании Google.
Шутки о нём впервые появились на 1 апреля шесть лет назад. Один из коллег Дина по имени Кентон Варда открыл страничку, куда каждый мог добавлять факты о Джеффе Дине. Идею с энтузиазмом подхватили другие разработчики — и вскоре наполнили страничку множеством таких «фактов».
19 советов по повседневной работе с Git
14 min
Tutorial
Translation

Если вы регулярно используете Git, то вам могут быть полезны практические советы из этой статьи. Если вы в этом пока новичок, то для начала вам лучше ознакомиться с Git Cheat Sheet. Скажем так, данная статья предназначена для тех, у кого есть опыт использования Git от трёх месяцев. Осторожно: траффик, большие картинки!
Содержание:
- Параметры для удобного просмотра лога
- Вывод актуальных изменений в файл
- Просмотр изменений в определённых строках файла
- Просмотр ещё не влитых в родительскую ветку изменений
- Извлечение файла из другой ветки
- Пара слов о ребейзе
- Сохранение структуры ветки после локального мержа
- Исправление последнего коммита вместо создания нового
- Три состояния в Git и переключение между ними
- Мягкая отмена коммитов
- Просмотр диффов для всего проекта (а не по одному файлу за раз) с помощью сторонних инструментов
- Игнорирование пробелов
- Добавление определённых изменений из файла
- Поиск и удаление старых веток
- Откладывание изменений определённых файлов
- Хорошие примечания к коммиту
- Автодополнения команд Git
- Создание алиасов для часто используемых команд
- Быстрый поиск плохого коммита
Как я стал программистом. Путь от питерского бездомного до Senior Developer-а за 6 лет
6 min
Всем привет! Меня зовут Андрей, я работаю в отделе разработки продуктов Veeam Software.
В этом году исполняется 6 лет с того дня, как я «пришел» в программирование. К слову, случилось это стихийно, и на момент написания своего первого кода, у меня за плечами не было ни профильного образования, ни малейшего опыта. Сегодня же, я создаю продукт, признанный и уважаемый во всем мире.

Сегодня я хочу рассказать свою историю.
Итак, начну с момента, когда мне исполнился 21 год, я уволился из рядов доблестной российской армии и оказался на серых и холодных улицах Санкт-Петербурга. Осень, отсутствие жилья и денег активировали все клетки головного мозга для ответа на вопрос: «Что делать?».
В этом году исполняется 6 лет с того дня, как я «пришел» в программирование. К слову, случилось это стихийно, и на момент написания своего первого кода, у меня за плечами не было ни профильного образования, ни малейшего опыта. Сегодня же, я создаю продукт, признанный и уважаемый во всем мире.
Сегодня я хочу рассказать свою историю.
Итак, начну с момента, когда мне исполнился 21 год, я уволился из рядов доблестной российской армии и оказался на серых и холодных улицах Санкт-Петербурга. Осень, отсутствие жилья и денег активировали все клетки головного мозга для ответа на вопрос: «Что делать?».
Применение Теории вероятностей в IT
1 min
Так сложилось, что я преподаю студентам IT-шных специальностей в Сибирском Федеральном Университете (СФУ) такой предмет, как «Теория вероятностей и математическая статистика». Из года в год я сталкиваюсь с таким явлением, что студенты не понимают, зачем и почему им учить эту дисциплину. Конечно, можно сказать, что математика тренирует мозг и развивает абстрактное мышление (которое весьма необходимо программистам). Но я считаю, что если подкрепить преподавание ТВ и МС яркими примерами (особенно применительно к IT), это даст необходимую мотивацию для изучения этого предмета.
Дайджест статей по анализу данных и big data
2 min
 Частенько читаю Хабр и заметил что в последнее время появились Дайджесты новостей по многим тематикам, таким как веб-разработка на php, разработка на Python, мобильные приложения, но не встретил ни одного подборки по популярному сейчас направлению, а именно анализу данных и big data.
Частенько читаю Хабр и заметил что в последнее время появились Дайджесты новостей по многим тематикам, таким как веб-разработка на php, разработка на Python, мобильные приложения, но не встретил ни одного подборки по популярному сейчас направлению, а именно анализу данных и big data. Ниже я решил собрать небольшую подборку материалов по данной теме. Т.к. на русском материалов не так много, в данный дайджест попали в основном англоязычные статьи.
Кого заинтересовала данная тема прошу подкат. А также жду замечаний, пожеланий и дополнений, буду очень рад обратной связи.
Почему Ваза утонул, а С++ всё ещё на плаву
6 min
Tutorial
Эта статья — краткий пересказ невероятно интересного доклада Скотта Майерса для тех, у кого нет 70 минут на весь доклад, но есть 7 минут на основные тезисы.
Некоторые люди, которые не пишут на С++, а лишь слышали об этом языке, задаются вопросом: «Почему вообще кто-то пишет на C++?». Но есть люди, которые используют С++ каждый день, и вот эти люди задаются вопросом: «А действительно, почему я пишу на этом языке?».
 Но ведь действительно, должна быть какая-то причина, по которой люди пишут программы на С++. Давайте вернемся в начало 90-ых, когда проходила стандартизация С++. Была предложена масса идей. Предложений было столько и они были настолько разные, что мне запомнилась цитата Джима Вальдо, который тогда работал в комитете по стандартизации: «Каждый, предлагающий добавить что-то в С++ должен приложить к заявке свою почку. Тогда никто не предложит больше двух идей, а к выбору этих двух он подойдёт невероятно ответственно.»
Но ведь действительно, должна быть какая-то причина, по которой люди пишут программы на С++. Давайте вернемся в начало 90-ых, когда проходила стандартизация С++. Была предложена масса идей. Предложений было столько и они были настолько разные, что мне запомнилась цитата Джима Вальдо, который тогда работал в комитете по стандартизации: «Каждый, предлагающий добавить что-то в С++ должен приложить к заявке свою почку. Тогда никто не предложит больше двух идей, а к выбору этих двух он подойдёт невероятно ответственно.»
Язык, который был бы получен в результате принятия всех предложений, выходил слишком сложным и тогда Бьёрн Страуструп сказал «А помните Ваза?». Никто, кроме людей из Швеции, не понял о чём речь. Ваза был огромным боевым кораблём, построенным в Швеции в 1625 году. Основным принципом постройки корабля было «А почему бы нам не добавить сюда ещё и вот такую фичу?». Многие из идей исходили непосредственно от короля, в частности он лично утверждал размеры корабля. Также на Ваза по указаниям свыше требовалось нацепить огромное количество элементов украшения, резьбы, большое количество пушек и т.д. А королю ведь не откажешь. Итог был закономерным — из-за ошибок в конструировании Ваза затонул в первом же рейсе, едва выйдя из бухты.
Некоторые люди, которые не пишут на С++, а лишь слышали об этом языке, задаются вопросом: «Почему вообще кто-то пишет на C++?». Но есть люди, которые используют С++ каждый день, и вот эти люди задаются вопросом: «А действительно, почему я пишу на этом языке?».
Но ведь действительно, должна быть какая-то причина, по которой люди пишут программы на С++. Давайте вернемся в начало 90-ых, когда проходила стандартизация С++. Была предложена масса идей. Предложений было столько и они были настолько разные, что мне запомнилась цитата Джима Вальдо, который тогда работал в комитете по стандартизации: «Каждый, предлагающий добавить что-то в С++ должен приложить к заявке свою почку. Тогда никто не предложит больше двух идей, а к выбору этих двух он подойдёт невероятно ответственно.»Язык, который был бы получен в результате принятия всех предложений, выходил слишком сложным и тогда Бьёрн Страуструп сказал «А помните Ваза?». Никто, кроме людей из Швеции, не понял о чём речь. Ваза был огромным боевым кораблём, построенным в Швеции в 1625 году. Основным принципом постройки корабля было «А почему бы нам не добавить сюда ещё и вот такую фичу?». Многие из идей исходили непосредственно от короля, в частности он лично утверждал размеры корабля. Также на Ваза по указаниям свыше требовалось нацепить огромное количество элементов украшения, резьбы, большое количество пушек и т.д. А королю ведь не откажешь. Итог был закономерным — из-за ошибок в конструировании Ваза затонул в первом же рейсе, едва выйдя из бухты.
Как работают рекомендательные системы. Лекция в Яндексе
11 min
Привет, меня зовут Михаил Ройзнер. Недавно я выступил перед студентами Малого Шада Яндекса с лекцией о том, что такое рекомендательные системы и какие методы там бывают. На основе лекции я подготовил этот пост.
План лекции:
- Виды и области применения рекомендательных систем.
- Простейшие алгоритмы.
- Введение в линейную алгебру.
- Алгоритм SVD.
- Измерение качества рекомендаций.
- Направление развития.
Гарри Каспаров проиграл суперкомпьютеру Deep Blue в шахматы из-за компьютерного сбоя
2 min

Одна из величайших шахматных партий всех времен и народов — это, вне всяких сомнений, сражение Гарри Каспарова и суперкомпьютера Deep Blue от IBM, в 1997 году. Это была уже вторая игра Каспарова с суперкомпьютером, матч-реванш машины.
Первая партия в игре была очень сложной и напряженной, у Каспарова было поначалу преимущество, но, начиная с 44 хода, он перестал понимать логику игры машины, и, в итоге, проиграл весь матч. Спустя некоторое время Каспаров даже обвинил инженеров IBM в «читерстве»: манипуляциях с ПО машины, которые и привели к поражению. Спустя 17 лет ситуация прояснилась — Каспаров проиграл из-за сбоя в алгоритме работы компьютера в самой первой партии всего сражения.