Приветствую уважаемое сообщество.
Последнее время я уделял некоторое внимание теме синтаксического анализа (с целью в том числе улучшить собственные знания и навыки), и у меня создалось впечатление, что почти все курсы по компиляторам начинают с математических формализмов, и требуют сравнительно высокого уровня подготовки от изучающего. Либо там используется в большом количестве формальная математическая запись, как в классической Dragon Book, в которой, например, написано:
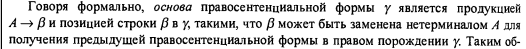
Это может с непривычки напугать. Нет, с какого-то момента формальная запись становится удобной и даже необходимой, но для “человека с улицы”, который хотел бы, чтобы ему “на пальцах” объяснили, “в чем тут дело”, это может быть сложно. А вопрос “что такое LL и LR — анализ, и в чем между ними разница” программисты задают довольно часто (потому что не все программисты имеют формальное образование в области Computer Science, как и я, и не все из них проходили там курс по компиляторам).
Мне более близок подход, когда сначала мы берем задачу, пытаемся ее решить, и в процессе решения сначала вырабатываем интуитивное понимание принципа, а потом уже для этого понимания создаем математические формализмы. Поэтому я на очень простом примере в этой статье хочу показать, какая идея лежит в основе восходящего синтаксического анализа (он же bottom-up parsing, он же LR). Будем вычислять арифметическое выражение, в котором для еще большего упрощения будем поддерживать только операторы сложения, умножения и скобки (чтобы не усложнять пример отрицательными числами и поддержкой унарного минуса).
Перед тем, как перейти непосредственно к задаче, напишу некоторые соображения вообще на тему синтаксического разбора.

