Магазин работает уже почти пол года — добро пожаловать :)
http://www.digital-mode.ru
Как это все работает.
Фронт-офис — генерирует страницы с группами и товарами, а также позволяет добавить товар в корзину и оформить заказ.
Хранилище картинок — отдает фотографии товаров в нужном размере. Все остальные картинки статические, загружаются с сервера GAE.
Бэк-офис — административная часть, позволяет редактировать товары и группы, просматривать заказы, загружать фотографии для товаров, а также загружать обновления цен, наличия и новые позиции.
Для генерации почти всех страниц используется Django templates.
В целом ничего сложного :)
Проблемы с которыми пришлось столкнутся при разработке.
На текущий момент есть проблемы с загрузкой/выгрузкой большого количества данных. На данный момент использую CSV для загрузки обновлений (цены, товары, наличие). При большом объеме данных превышается тайм-аут 30 сек на выполнение.
Кроме этого в GAE ограничение на 30 запросов на запись (put). Соответственно обновлять больше 30 товаров за один проход не получается. Этот момент можно оптимизировать и обновлять данные не поштучно, а сразу пачками т.к. в GAE запись в хранилище может производится целыми массивами.
Выгрузка данных для Яндекс.Маркета занимает почти 10 секунд (200 товаров), 90% времени это генерация HTML.
Также не решена еще проблема с фильтрами и сортировками товаров по характеристикам. Т.к. БД не реляционная, привязать характеристики к товарам тяжело. Как вариант делать для каждого типа товара вручную в коде свой фиксированный набор характеристик, это возможно пока типов товаров не больше десятка.
Преимущества GAE
Отсутствие необходимости покупки/настройки/поддержки собственного сервера.
Автоматическое масштабирование.
Одинаковое время доступа к приложению при разных нагрузках.
Удобство разработки.
Итого
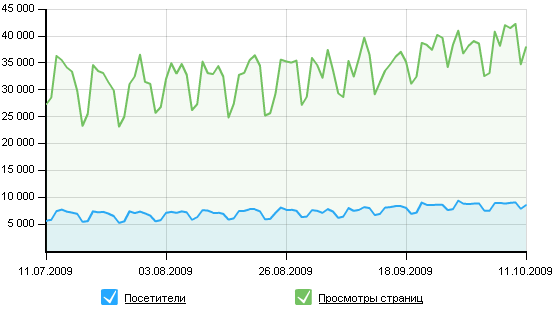
Скорость работы магазина не зависит от количества посетителей.
На данный момент при 500-600 хитов в сутки используется 0,3-0,4 часа процессорного времени из 6,5 бесплатного.
После публикации в комментариях к топику: "
Стоит ли вам использовать Google AppEngine?" ссылки на магазин было использовано ресурсов:
— 0,44 часов CPU из 6,5
— 28000 запросов из 1,3 млн
— 210 Мб из 1 Гб исходящего траффика
— 5,59 Гб из 116 Гб получено из API
— 0,22 часа из 62,11 использовано хранилищем
Всего за 12 часов — 700 хитов (180 хостов).
Это микрохаброэффект:






")
