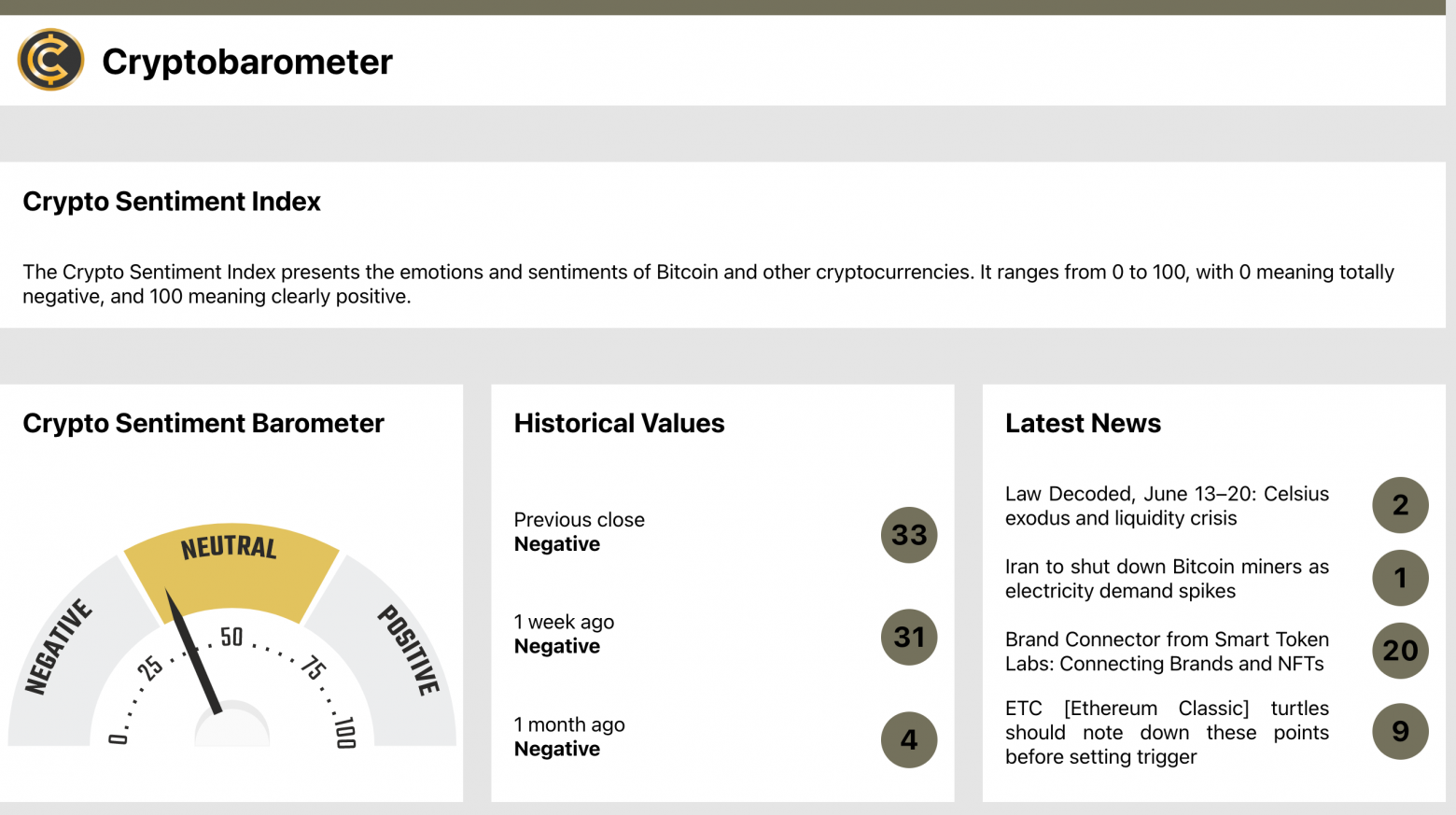
Евгений (MalDeckard) Черешнев поделился личным опытом и написал исчерпывающий гайд, который может помочь многим людям и предостеречь от последствий:
У меня на днях украли смартфон — профессиональный вор-велосипедист на скорости выхватил из рук прямо в центре города и был таков. Это может случиться с кем угодно и в любой стране мира. Я, в силу профессиональной деформации вокруг IT, данных, приватности и безопасности, к ситуации был морально готов и знал, что делать. Друзья, с которым поделился историей посоветовали написать памятку, которую может использовать каждый человек, даже далекий от айти. Этот текст — эта самая памятка. Смартфон она вам не вернет. Но, если кому-то поможет снизить ущерб и сэкономит седых волос — значит, не зря потратил время на написание, а вы — на прочтение.
Справедливости ради, большинство воров уже в курсе того, что каждый смартфон — это, по сути, радиомаяк, по которому всегда можно укравшего отследить. Поэтому они редко оставляют его включенным — практически сразу достают и выбрасывают SIM-карту, сам телефон вырубают и сдают на запчасти за копейки. Что крайне обидно — ибо шансы того, что, например, мой iPhone 12 Pro Max 512 банально разберут на экран, аккумулятор и несколько особо востребованных микросхем — стремятся к 100%. То есть, вор украл крайне дорогой девайс, а получит за него или хрен или (если он идиот) — срок. Но это не всегда так. Иногда можно получить реально грузовичок и тележку проблем. Во-первых, в ряде типов краж (как в моем случае) телефон попадает в руки плохого парня в разлоченном состоянии и есть риск, что злоумышленник девайс специально не залочит — будет держать его активированным и извлекать из него максимальную пользу, на что у него будет в теории до 24ч (после чего сработает система защиты в заводских настройках и снова попросит ввести пин-код, даже, если телефон до сих пор разлочен).