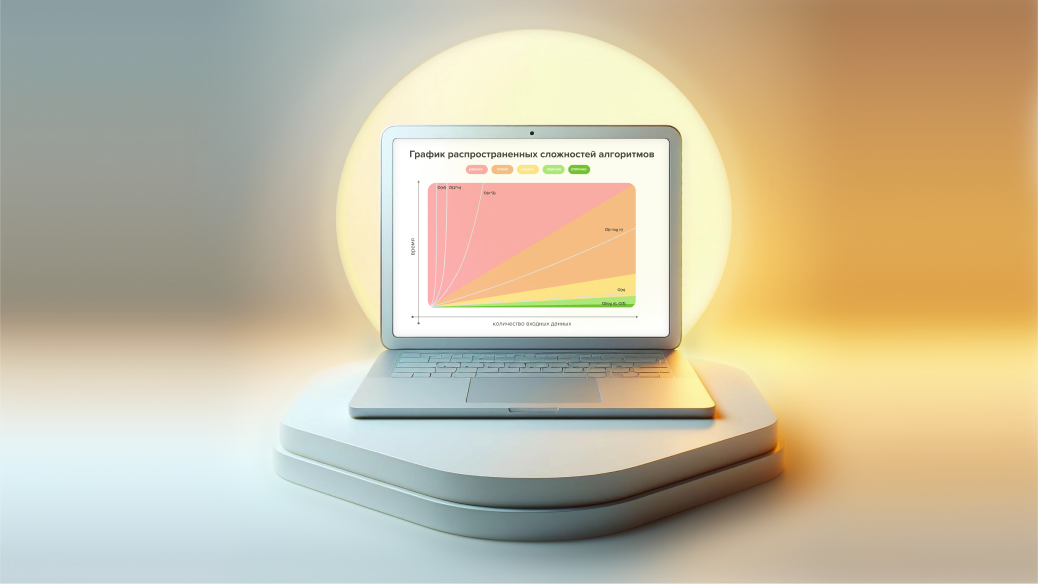
Продолжаем говорить о производительности и оптимизации кода. Сегодня поговорим о том, как и зачем оценивать сложность алгоритмов, а также наглядно покажем, как эта сложность влияет на производительность кода.

Разработчик ПО
Продолжаем говорить о производительности и оптимизации кода. Сегодня поговорим о том, как и зачем оценивать сложность алгоритмов, а также наглядно покажем, как эта сложность влияет на производительность кода.

В этой статье мы разберем новые удивительные способности последней языковой модели из семейства GPT (от понимания мемов до программирования), немного покопаемся у нее под капотом, а также попробуем понять – насколько близко искусственный интеллект подошел к черте его безопасного применения?

В последнее время нам почти каждый день рассказывают в новостях, какие очередные вершины покорили языковые нейросетки, и почему они уже через месяц совершенно точно оставят лично вас без работы. При этом мало кто понимает — а как вообще нейросети вроде ChatGPT работают внутри? Так вот, устраивайтесь поудобнее: в этой статье мы наконец объясним всё так, чтобы понял даже шестилетний гуманитарий!

Павел Агалецкий, ведущий разработчик юнита Platform as a Service Авито, написал, как поднять кластер Kubernetes на локальном компьютере Mac с помощью подручных инструментов, а потом задеплоить в него простейшие приложения.

...
Попробую, попытаюсь объяснить. Наверное, для кого-то это будет оправданием, но я просто объясняю.
Как быстро зафейлить новый проект Java? Просто взять и применить все, что ты услышал на последней Java конференции;) Как быстро сделать энтерпрайзный проект минимальной командой в короткие сроки? Верно — подобрать оптимальную архитектуру и правильные инструменты. Senior Developer из команды Jmix Дмитрий Черкасов рассказывает о компромиссном варианте между хайповыми (все еще) микросервисами и монолитами, который называется Self-Contained Systems. Кажется, он выпьет меньше крови и сохранит ваши нервы. Дальше — рассказ от первого лица.



Привет, хаброчеловек!
В этой статье мы обсудим путь среднестатистического обывателя в Machine Learning, а именно — как стать ML-инженером. Поговорим о специфике области, какие требуются знания и скиллы, что нужно делать и с чего начать.
Чтобы применять Domain-Driven Design, DDD Aggregate и Transactional outbox на MongoDB, наша команда создала open source — библиотеку calypso для работы с BSON.
Публикация для тех, кто стремится к современным практикам разработки и разделяет наше влечение к Scala 3.
Готовы к открытиям? Добро пожаловать в мир функционального программирования и надёжной работы с schema-on-read.

При рефакторинге монолита на микросервисы часто мы уже обладаем работающей системой. У которой миллионы, тысячи активных пользователей. Возможно их 20, но они очень важные и очень активные. Как в таком случае отрефакторить все, чтобы внешне никто ничего не заметил? И как в этом поможет тропический фикус-душитель?
Очень часто приходится слышать, что Sqoop — это серебряная пуля для загрузки данных большого объёма с реляционных БД в Hadoop, особенно с Oracle, и Spark-ом невозможно достигнуть такой производительности. При этом приводят аргументы, что sqoop — это инструмент, заточенный под загрузку, а Spark предназначен для обработки данных.
Меня зовут Максим Петров, я руководитель департамента "Чаптер инженеров данных и разработчиков", и я решил написать инструкцию о том, как правильно и быстро загружать данные Spark, основываясь на принципах загрузки Sqoop.
Первичное сравнение технологий
В нашем примере будем рассматривать загрузку данных из таблиц OracleDB.
Рассмотрим случай, когда нам необходимо полностью перегрузить таблицу/партицию на кластер Hadoop c созданием метаданных hive.

За пределами всем известного GitHub Copilot лежит огромный мир полезных приложений для программистов, и каждую неделю в нем появляется что-нибудь новенькое. В этом посте мы расскажем об этих инструментах — как полноценных конкурентах продукта GitHub, так и более специфических плагинах, а также о нашей собственной разработке в этом направлении.
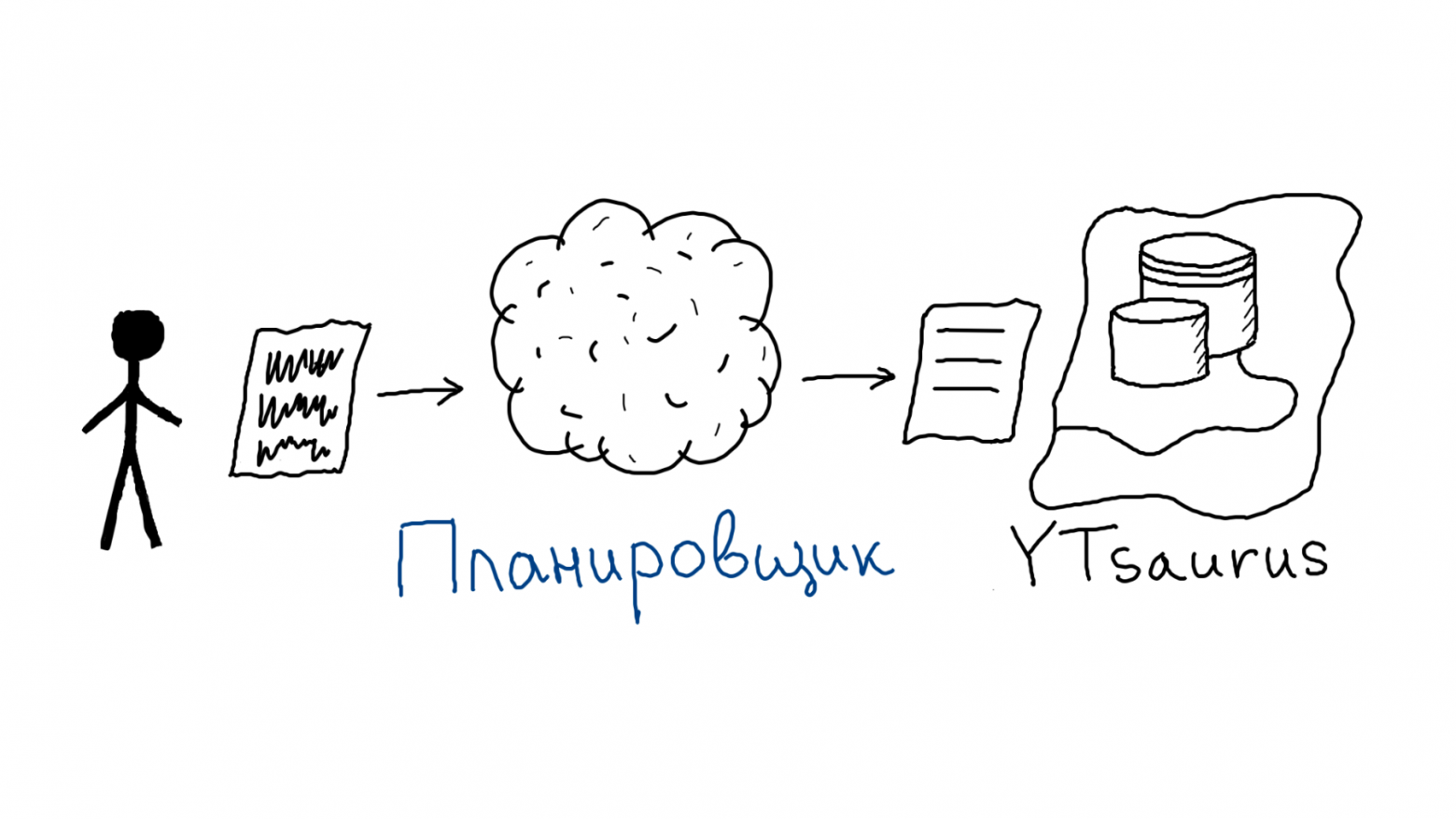
В больших распределённых системах многое зависит от эффективности запросов: если на гигабайте данных неоптимальный запрос может выполняться за миллисекунды, то при увеличении массива в тысячи раз, сервер начнёт кряхтеть, пыхтеть и жаловаться. Чтобы избежать этого, помогут знания о работе распределённых систем и их частей, а именно — планировщиков.
Ещё с университетских времён я исследую распределённые системы, а последние два года в Яндексе адаптирую Apache Spark к внутренней инфраструктуре. Эта статья посвящена Apache Spark, а именно: как мы в рамках YTsaurus делали его ещё эффективнее. Написана она по мотивам моего доклада для «Онтико».

Всем привет! Меня зовут Мурат Насиров, я Flutter-разработчик в Friflex. Мы разрабатываем мобильные приложения и специализируемся на решениях для ритейла. На одном из наших проектов мне пришлось столкнуться с внедрением кнопки оплаты через Систему Быстрых Платежей (СБП). В этой статье я хочу поделиться своим опытом и наработками в быстрой интеграции нативных компонентов SDK СБП в кроссплатформенное приложение на Flutter.
Криптохомячкам посвящается ...
Алгоритм Гровера представляет собой обобщённый, независящей от конкретной задачи поиск, функция которого представляет "чёрный ящик" f: {0,1}^n to {0,1}^n, для которой известно, что EXISTS!w:f(w)=a, где a — заданное значение.
Считаем, что для f и заданного a можно построить оракул Uf: { |w> to |1>, |x> to |0> if |x> != |w> }

Применим этот алгоритм для решения задачи нахождения ключа шифра Цезаря ...

Привет, Хабр! Меня зовут Миша, я работаю в МТС RED в команде тестирования на проникновение на позиции эксперта.
В ходе пентестов очень часто приходится бороться с антивирусами. Увы, это может отнимать много времени, что негативно сказывается на результатах проекта. Тем не менее есть парочка крутых трюков, которые позволят на время забыть про антивирус на хосте, и один из них - выполнение полезной нагрузки в памяти.
Ни для кого не секрет, что во время пентестов атакующим приходится использовать готовые инструменты, будь то нагрузка для Cobalt Strike, серверная часть от поднимаемого прокси-сервера или даже дампилка процесса lsass.exe. Что объединяет все эти файлы? То, что все они давным-давно известны антивирусам, и любой из них не оставит без внимания факт появления вредоноса на диске.
Заметили ключевой момент? Факт появления вредоноса на диске. Неужели если мы сможем научиться выполнять пейлоад в оперативной памяти, то пройдём ниже радаров антивирусов? Давайте разберёмся с техниками выполнения файлов полностью в памяти и увидим, насколько жизнь атакующих станет проще, если они научатся работать, не затрагивая диск.

Полное руководство по созданию DAG в Apache Airflow DAG, позволяющих создать конвейер данных из разных источников, запускаемый в определенные периоды времени с заданной логикой. Первая часть. Источник: DAGs: The Definitive Guide от astronomer.io
Добро пожаловать в полное руководство по Apache Airflow DAG, представленное командой Astronomer. Эта электронная книга охватывает все, что вам нужно знать для работы с DAG, от строительных блоков, из которых они состоят, до рекомендаций по их написанию, динамической генерации, тестированию, отладке и многому другому. Это руководство, написанное практикующими для практикующих.
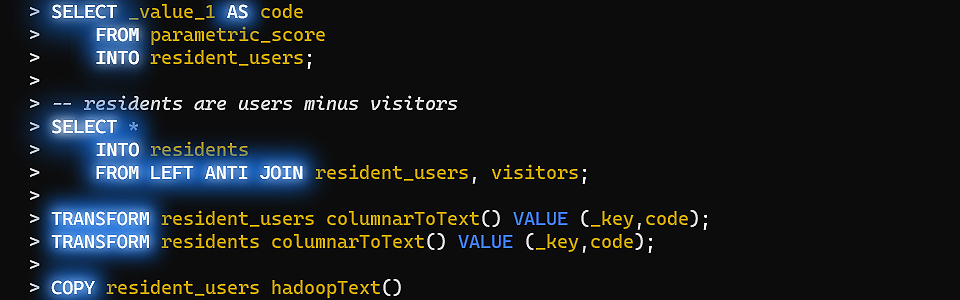
В данной серии статей я подробно расскажу о том, как написать на Java собственный интерпретатор объектно-ориентированного диалекта SQL с использованием Spark RDD API, заточенный на задачи подготовки и трансформации наборов данных.
Краткое содержание предыдущей серии:
Вступление
Постановка задачи
Проектирование языка. Операторы жизненного цикла наборов данных
Проектирование системы типов
Уровень сложности данной серии статей — высокий. Базовые понятия по ходу текста вообще не объясняются, да и продвинутые далеко не все. Поэтому, если вы не разработчик, уже знакомый с терминологией из области бигдаты и жаргоном из дата инжиниринга, данные статьи будут сложно читаться, и ещё хуже пониматься. Я предупредил.
