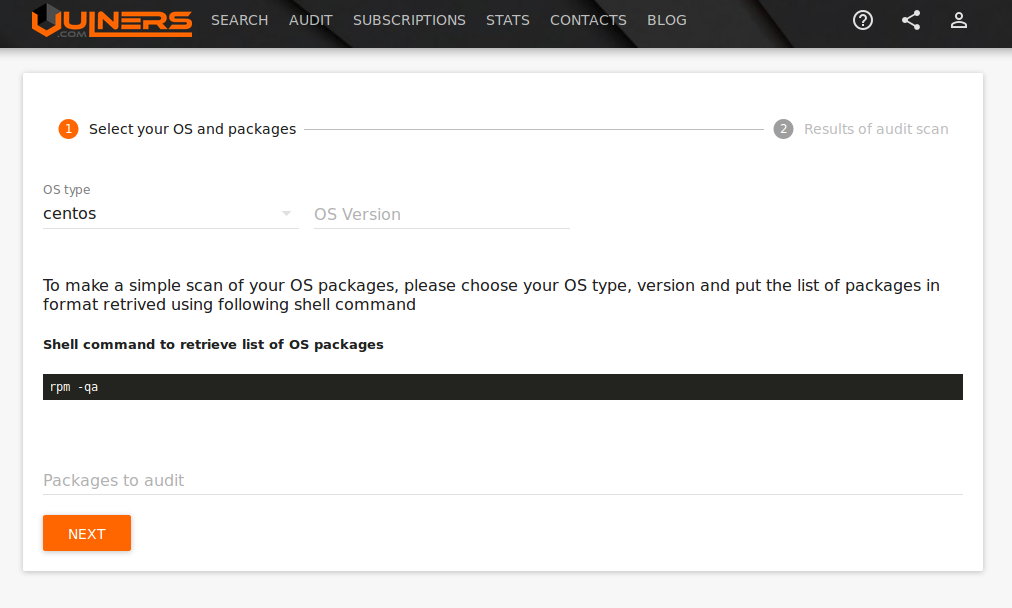
Что лучше для web-приложений - монолит или микросервисы? Многие ответят на этот вопрос, что, мол, все инструменты хороши, если их использовать по назначению. В таком случае у меня, как у человека, в силу своего возраста, довольно консервативного и неохотно воспринимающего непроверенные временем концепции, возникает другой вопрос - а чем хорош монолит? Где его ниша? Стоит ли переключаться на микросервисы или монолит ещё не изжил себя и на мой век хватит?
В фокусе моих интересов не гигантские web-приложения типа Gmail, Facebook, Twitter, а web-приложения, созданные на базе таких платформ, как Wordpress, Drupal, Joomla, Django, Magento и им подобным. Под катом мои субъективные мысли на этот счёт. Ничего нового - всё те же 33 буквы кириллицы и 26 букв латиницы вперемешку.



 В 2008 году в списке рассылки pgsql-hackers началось
В 2008 году в списке рассылки pgsql-hackers началось 

 Поиск, адаптация и работа сотрудников служб технической поддержки стала темой для встречи руководителей и специалистов технической поддержки российских ИТ-компаний. Мероприятие проходило в Санкт-Петербурге на базе офиса компании Wrike. Участниками первого support-семинара стали представители более чем 20 компаний, в их числе: Parallels, Wrike, IT Summa, Git in Sky, Virtuozzo, Yota.
Поиск, адаптация и работа сотрудников служб технической поддержки стала темой для встречи руководителей и специалистов технической поддержки российских ИТ-компаний. Мероприятие проходило в Санкт-Петербурге на базе офиса компании Wrike. Участниками первого support-семинара стали представители более чем 20 компаний, в их числе: Parallels, Wrike, IT Summa, Git in Sky, Virtuozzo, Yota. 
 Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели
Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели