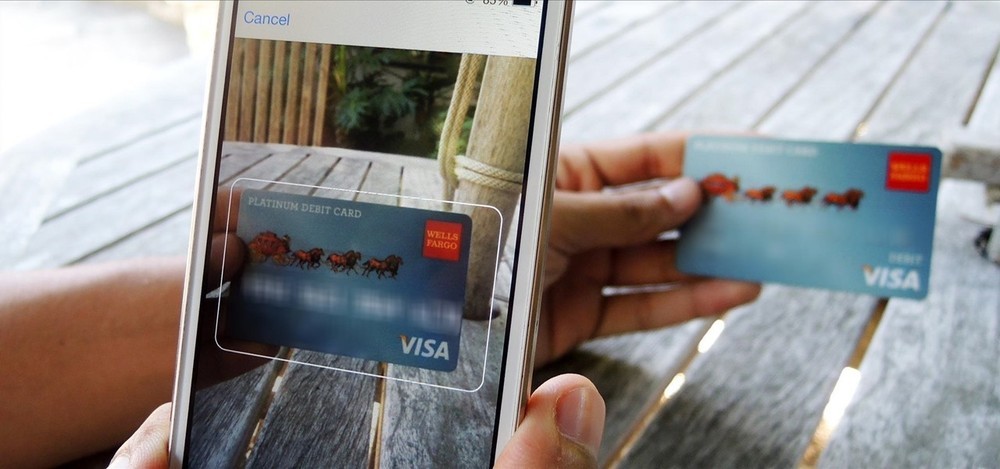
В 2017 году блокчейн стал предметом научного интереса, когда в Торонто открылся первый институт исследований блокчейна. Около 30 ведущих экспертов приступили к разработке различных проектов, связанных с этой технологией.

Блокчейн — это надёжный способ хранения данных о сделках, контрактах, транзакциях, обо всём, что необходимо записать и проверить. Сегодня блокчейн проник практически во все сферы жизнедеятельности, готов в корне изменить финансовую систему государства и в разы упростить работу среднего и крупного бизнеса. Блокчейн не секретная технология: в сети огромное количество статей о том, как он устроен и по какому принципу работает. Мы собрали самые интересные и нужные факты в одну статью, на которую можно давать ссылку, когда вас спросят: «Что же такое блокчейн?»
Блокчейн — это надёжный способ хранения данных о сделках, контрактах, транзакциях, обо всём, что необходимо записать и проверить. Сегодня блокчейн проник практически во все сферы жизнедеятельности, готов в корне изменить финансовую систему государства и в разы упростить работу среднего и крупного бизнеса. Блокчейн не секретная технология: в сети огромное количество статей о том, как он устроен и по какому принципу работает. Мы собрали самые интересные и нужные факты в одну статью, на которую можно давать ссылку, когда вас спросят: «Что же такое блокчейн?»










 Данная книга содержит исчерпывающую информацию для всех желающих научиться программировать на замечательном языке Swift и создавать собственные iOS-приложения. Вы найдете не только теоретический материал, но и большое количество практических примеров и заданий, которые позволят постичь все тонкости нового языка. Дерзайте, ведь, изучив Swift, вы сможете создавать приложения для любой платформы — iOS, OS X, tvOS или watchOS.
Данная книга содержит исчерпывающую информацию для всех желающих научиться программировать на замечательном языке Swift и создавать собственные iOS-приложения. Вы найдете не только теоретический материал, но и большое количество практических примеров и заданий, которые позволят постичь все тонкости нового языка. Дерзайте, ведь, изучив Swift, вы сможете создавать приложения для любой платформы — iOS, OS X, tvOS или watchOS. Недавно мне понадобилось написать 2-3-дерево и я начал искать информацию в русскоязычном интернете. К сожалению, ни на хабре, ни на других ресурсах я не смог найти достаточно полную информацию на русском языке. На всех ресурсах было одно и то же: свойства дерева, как вставляются ключи в дерево, поиск в дереве и иногда простой пример, как удаляется ключ из дерева; не было реализации.
Недавно мне понадобилось написать 2-3-дерево и я начал искать информацию в русскоязычном интернете. К сожалению, ни на хабре, ни на других ресурсах я не смог найти достаточно полную информацию на русском языке. На всех ресурсах было одно и то же: свойства дерева, как вставляются ключи в дерево, поиск в дереве и иногда простой пример, как удаляется ключ из дерева; не было реализации.