Введение
В предыдущих статьях, посвященных организации данных в виде рубрикатора (
Использование графа, как основы для создания рубрикатора и
Проблемы, подстерегающие любого создателя рубрикаторов) были описаны общие идеи по организации рубрикатора. В этой статье я опишу один из возможных алгоритмов автоматического определения тематики текста на основе заранее подготовленного графа-рубрикатора. При этом я сознательно избегаю сложных формул, чтобы донести идею, лежащую в основе алгоритма, максимально просто.
Подготовка данных рубрикатора
Для начала определимся с тем, в каком виде мы будем готовить данные для рубрикатора.
- 1. Рубрикатор – это граф, а не дерево
- 2. Текст, тематика которого определяется, может быть отнесен к нескольким рубрикам одновременно
- 3. Для каждого соотнесения с рубрикой указывается коэффициент точности определения рубрики
- 4. Тематика текста определяется для каждого текста отдельно, и не зависит от того как были определены рубрики других текстов ранее
Последний пункт нуждается в небольшом пояснении. Независимость определения тематики текста очень хороша, когда не требуется последующая сортировка результатов. Когда тексты просто отнесены к рубрики или нет. Но при наличии в рубрике нескольких текстов, наверняка возникнет необходимость отсортировать их по критерию наилучшего попадания в рубрику. В данной статье этот вопрос опущен для ясности.
Алгоритм определения тематики текста, кратко
Описываем рубрикатор. Извлекаем из исследуемого текста ключевые слова, описанные в рубрикаторе. В результате извлечения получаем кусочки разорванного и чаще всего несвязного графа. Используем волновой (или любой другой, по желанию) алгоритм для «дотягивания» извлеченных кусочков графа до вершины «всё». Анализируем и выводим результаты.


 Внутренний фольклор и юмор своих разработчиков есть в каждой команде, хотя не в каждой его бережно собирают и архивируют. Но мы в Parallels заботливо делали это несколько лет подряд. Не так давно мы поделились
Внутренний фольклор и юмор своих разработчиков есть в каждой команде, хотя не в каждой его бережно собирают и архивируют. Но мы в Parallels заботливо делали это несколько лет подряд. Не так давно мы поделились 
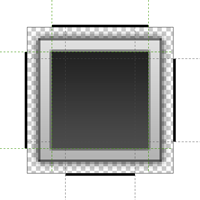 Уверен с форматом nine-patch уже все давным-давно знакомы, вероятно даже не раз пользовались им в своих Android-проектах (а может даже и где-то ещё). Также о нём чуть менее года назад
Уверен с форматом nine-patch уже все давным-давно знакомы, вероятно даже не раз пользовались им в своих Android-проектах (а может даже и где-то ещё). Также о нём чуть менее года назад  Рекомендации по созданию UI виджетов и некоторых блоков приложений для ОС Android предписывают нам использовать блоки с закруглёнными углами и/или с эффектом объема, отбрасывающие тени. Какие же инструменты нам дает SDK для реализации таких интерфейсов?
Рекомендации по созданию UI виджетов и некоторых блоков приложений для ОС Android предписывают нам использовать блоки с закруглёнными углами и/или с эффектом объема, отбрасывающие тени. Какие же инструменты нам дает SDK для реализации таких интерфейсов?