Возможно не все, кто знаком с InterSystems Caché, знают о расширениях Студии по работе с исходным кодом. На самом деле в ней можно создать свой тип исходного кода, компилировать его в интерпретируемый (INT) и объектный код, и даже в некоторых случаях обеспечить и code completion. Т.е. теоретически можно реализовать поддержку в Студии любого языка программирования, который будет исполняться СУБД не хуже Caché ObjectScript. В этой статье я опишу простой пример, как реализовать возможность писать программы на некотором подобии JavaScript в Caché Студии. Если интересно, добро пожаловать под кат.

ОЗ @multik
Разработчик
Как я фотоаппарат покупал
6 min

Не знаю, сколько владельцев магазинов никогда не пробовали купить товары у себя же. Ну и, вообще, одна из лучших иллюстраций того, как можно собирать практический опыт для своего бизнеса – это наступание на грабли при обычной попытке что-то купить. Сейчас расскажу просто фееричную историю покупки камеры, в которой прекрасно всё – начиная от хамящих операторов, доставки без документов о продаже и заканчивая курьерами, продалбывающими документы.
Итак, началось всё с обзвона условно-доступных магазинов: их нашлось около десятка.
Дыра 8-800
У нескольких магазинов стоит автоответчик на 8-800 — это хорошая дыра для атаки на переполнение бюджета. Уязвимость давно описана – конкуренты могут делать ботом четырёхсекундные звонки на номер 8-800, и, не дожидаясь живого оператора, класть трубку. За 800 платит владелец (магазин), поэтому в конце месяца при таком раскладе может приехать большой счёт. Я почти уверен, что грамотный админ отследит такие ситуации – но не уверен, он есть у маленьких магазинов. Собственно, мы сами узнали об этом из топика на Хабре и сразу закрыли дыру.
Проверьте, как у вас.
Дуальные числа в бизнесе или как оценить чувствительность решения к изменению начальных условий
4 min
 За применение в бизнесе мнимых величин уже дали премию. Теперь интересно что-нибудь поиметь с дуальных.
За применение в бизнесе мнимых величин уже дали премию. Теперь интересно что-нибудь поиметь с дуальных.Дуальное число — это расширение поля действительных чисел (или любого другого, например комплексных) вида a + εb, где a и b — числа из исходного поля. При этом полагается, что ε ε = 0.
Оказывается, у таких странных чисел есть практическое приложение.
Основным полезным свойством дуальных чисел является
f(a + εb) = f(a) + εf'(a)b.
Когда у нас есть формула для f(x), получить производную f'(x) труда не составит. Но часто f(x) доступно только в виде алгоритма — например как решение специальным образом составленной системы линейных уравнений. Запустив алгоритм с исходными данными, в которые добавлена ε мы получим результат и значение производной по одному из параметров.
Немного оптимизма под колпаком тотального контроля
4 min
 Всего несколько лет назад казалось: кому может понадобиться информация о моей частной жизни, которую я оставляю в интернете? Ведь большая часть переписки – ничего не значащая болтовня, едва ли представляющая большую ценность для собеседников, что уж говорить о спецслужбах. И кому плохо от того, что Гугл знает почти все о моих вкусах и пристрастиях? Раздражает, конечно, получать полжизни рекламу подгузников, однажды случайно зайдя на сайт про младенцев. Но жить можно.
Всего несколько лет назад казалось: кому может понадобиться информация о моей частной жизни, которую я оставляю в интернете? Ведь большая часть переписки – ничего не значащая болтовня, едва ли представляющая большую ценность для собеседников, что уж говорить о спецслужбах. И кому плохо от того, что Гугл знает почти все о моих вкусах и пристрастиях? Раздражает, конечно, получать полжизни рекламу подгузников, однажды случайно зайдя на сайт про младенцев. Но жить можно. Проблемы «маленького человека»
Но постепенно картина как-то помрачнела. Оказалось, что не только мировые лидеры не могут написать по электронной почте или сказать по телефону ничего личного. Среднестатистическому гражданину тоже стоит опасаться слишком уж провокативных высказываний – однажды его слова, фото или просто факт посещения «нежелательных» сайтов могут сыграть с ним злую шутку. Задумайтесь, обо всех ли своих подростковых интересах вам хочется рассказать начальству, партнерам по бизнесу или детям?
Как мы запрос в 100 раз ускоряли, или не все хеш-функции одинаково плохи
4 min
Мы разрабатываем базу данных. Однажны к нам обратилась компания, которая столкнулась со следующей задачей:
Есть некоторое множество объектов, и некоторое множество тегов. Каждый объект может содержать несколько тегов. Какие-то теги очень редкие, а какие-то встречаются часто. Одному объекту один тег может быть сопоставлен несколько раз.
Новые объекты, теги и связи между ними непрерывно добавляются.
Задача — очень быстро отвечать на вопросы вида: «сколько есть объектов, у которых есть тег А или B, но нету тега С» и похожие. На такие запросы хотелось бы отвечать за десятые доли секунды, при этом не останавливая загрузку данных.
Мы получили от них их данные вплоть до сегодняшнего дня, развернули тестовый кластер из четырех машин, и начали думать, как правильно распределить данные и как правильно представить задачу в виде SQL-запроса, чтобы получить максимальную производительность. В итоге решили, что запрос может иметь вид:
Чтобы такой запрос выполнялся быстро, мы разбили данные между серверами кластера по object_id, а внутри каждого сервера отсортировали их по тегам. Таким образом сервер, выполняющий запрос, может отправить запрос без изменений на все сервера с данными, а затем просто сложить их результаты. На каждом сервере с данными для выполнения запроса достаточно найти строки для тегов A, B и C (а так как данные по тегу отсортированы, это быстрая операция), после чего выполнить запрос за один проход по этим строкам. Худший тег имеет несколько десятков миллионов объектов, несколько десятков миллионов строк обработать за десятые доли секунды видится возможным.
Стоит отметить, что подзапрос содержит GROUP BY object_id. GROUP BY в данной ситуации можно выполнить несколькими способами, например, если данные после тега отсортированы по object_id, то можно выполнить что-то похожее на merge sort. В данной ситуации, однако, мы данные по object_id не отсортировали, и оптимизатор разумно решил, что для выполнения GROUP BY надо построить хеш-таблицу.
Мы загрузили все данные в кластер, и запустили запрос. Запрос занял 25 секунд.
Есть некоторое множество объектов, и некоторое множество тегов. Каждый объект может содержать несколько тегов. Какие-то теги очень редкие, а какие-то встречаются часто. Одному объекту один тег может быть сопоставлен несколько раз.
Новые объекты, теги и связи между ними непрерывно добавляются.
Задача — очень быстро отвечать на вопросы вида: «сколько есть объектов, у которых есть тег А или B, но нету тега С» и похожие. На такие запросы хотелось бы отвечать за десятые доли секунды, при этом не останавливая загрузку данных.
Мы получили от них их данные вплоть до сегодняшнего дня, развернули тестовый кластер из четырех машин, и начали думать, как правильно распределить данные и как правильно представить задачу в виде SQL-запроса, чтобы получить максимальную производительность. В итоге решили, что запрос может иметь вид:
SELECT
COUNT(*)
FROM (
SELECT
object_id,
(MAX(tag == A) OR MAX(tag == B)) AND MIN(tag != C) AS good
FROM tags
WHERE tag IN (A, B, C)
GROUP BY object_id
) WHERE good == 1;
Чтобы такой запрос выполнялся быстро, мы разбили данные между серверами кластера по object_id, а внутри каждого сервера отсортировали их по тегам. Таким образом сервер, выполняющий запрос, может отправить запрос без изменений на все сервера с данными, а затем просто сложить их результаты. На каждом сервере с данными для выполнения запроса достаточно найти строки для тегов A, B и C (а так как данные по тегу отсортированы, это быстрая операция), после чего выполнить запрос за один проход по этим строкам. Худший тег имеет несколько десятков миллионов объектов, несколько десятков миллионов строк обработать за десятые доли секунды видится возможным.
Стоит отметить, что подзапрос содержит GROUP BY object_id. GROUP BY в данной ситуации можно выполнить несколькими способами, например, если данные после тега отсортированы по object_id, то можно выполнить что-то похожее на merge sort. В данной ситуации, однако, мы данные по object_id не отсортировали, и оптимизатор разумно решил, что для выполнения GROUP BY надо построить хеш-таблицу.
Мы загрузили все данные в кластер, и запустили запрос. Запрос занял 25 секунд.
Оставьте ссылку на свой профиль — и добавьте к себе одного хабражителя
3 min
 Привет!
Привет!Всё просто. Вы берёте и пишете, кто вы, что делаете, и оставляете ссылку на свой профиль. Или на свой проект.
Причин две:
- Во-первых, меня регулярно просят посоветовать дизайнера, художника, разработчика и так далее. Я не знаю другого способа сделать это лучше.
- Во-вторых, я что-то реально опасаюсь перспектив развития Рунета, и поэтому хочу соединить друг с другом напрямую как можно больше людей. Добавляйтесь в профили к тем, кто вам близок.
Быстрое веб-приложение — трепанация сети
10 min
Психология — интересная и иногда полезная наука. Многочисленные исследования показывают, что задержка в отображении веб-страницы дольше 300 мс заставляет пользователя отвлечься от веб-ресурса и задуматься: «что за хрень?». Поэтому УСКОРИВ веб-проект до психологически невоспринимаемых значений, можно ПРОСТО удерживать пользователей дольше. И именно поэтому бизнес готов тратиться на скорость: $80М — чтобы уменьшить latenсy всего на 1 мс.
Однако, чтобы ускорить современный веб-проект, придется кровушки пустить и основательно покопаться в этой теме — поэтому базовое знание сетевых протоколов приветствуется. Зная принципы, можно без особых усилий ускорить свою веб-систему на сотни миллисекунд всего за несколько подходов. Ну что, готовы сэкономить сотни миллионов? Наливайте кофе.
Однако, чтобы ускорить современный веб-проект, придется кровушки пустить и основательно покопаться в этой теме — поэтому базовое знание сетевых протоколов приветствуется. Зная принципы, можно без особых усилий ускорить свою веб-систему на сотни миллисекунд всего за несколько подходов. Ну что, готовы сэкономить сотни миллионов? Наливайте кофе.
Автоматическое определение рубрики текста
5 min
Введение
В предыдущих статьях, посвященных организации данных в виде рубрикатора (Использование графа, как основы для создания рубрикатора и Проблемы, подстерегающие любого создателя рубрикаторов) были описаны общие идеи по организации рубрикатора. В этой статье я опишу один из возможных алгоритмов автоматического определения тематики текста на основе заранее подготовленного графа-рубрикатора. При этом я сознательно избегаю сложных формул, чтобы донести идею, лежащую в основе алгоритма, максимально просто.
Подготовка данных рубрикатора
Для начала определимся с тем, в каком виде мы будем готовить данные для рубрикатора.
- 1. Рубрикатор – это граф, а не дерево
- 2. Текст, тематика которого определяется, может быть отнесен к нескольким рубрикам одновременно
- 3. Для каждого соотнесения с рубрикой указывается коэффициент точности определения рубрики
- 4. Тематика текста определяется для каждого текста отдельно, и не зависит от того как были определены рубрики других текстов ранее
Последний пункт нуждается в небольшом пояснении. Независимость определения тематики текста очень хороша, когда не требуется последующая сортировка результатов. Когда тексты просто отнесены к рубрики или нет. Но при наличии в рубрике нескольких текстов, наверняка возникнет необходимость отсортировать их по критерию наилучшего попадания в рубрику. В данной статье этот вопрос опущен для ясности.
Алгоритм определения тематики текста, кратко
Описываем рубрикатор. Извлекаем из исследуемого текста ключевые слова, описанные в рубрикаторе. В результате извлечения получаем кусочки разорванного и чаще всего несвязного графа. Используем волновой (или любой другой, по желанию) алгоритм для «дотягивания» извлеченных кусочков графа до вершины «всё». Анализируем и выводим результаты.
Конспект по веб-безопасности
3 min
Tutorial
Простите, но накипело.
Много шишек уже набито на тему безопасности сайтов. Молодые специалисты, окончившие ВУЗы, хоть и умеют программировать, но в вопросе безопасности сайта наступают на одни и те же грабли.
Этот конспект-памятка о том, как добиться относительно высокой безопасности приложений в вебе, а также предостеречь новичков от банальных ошибок. Список составлялся без учета языка программирования, поэтому подходит для всех. А теперь позвольте, я немного побуду КО.

Итак, каким должен быть безопасный сайт?
Много шишек уже набито на тему безопасности сайтов. Молодые специалисты, окончившие ВУЗы, хоть и умеют программировать, но в вопросе безопасности сайта наступают на одни и те же грабли.
Этот конспект-памятка о том, как добиться относительно высокой безопасности приложений в вебе, а также предостеречь новичков от банальных ошибок. Список составлялся без учета языка программирования, поэтому подходит для всех. А теперь позвольте, я немного побуду КО.
Итак, каким должен быть безопасный сайт?
Интересные приемы программирования на Bash
6 min
Tutorial
Эти приемы были описаны во внутреннем проекте компании Google «Testing on the Toilet» (Тестируем в туалете — распространение листовок в туалетах, что бы напоминать разработчикам о тестах).
В данной статье они были пересмотрены и дополнены.
В данной статье они были пересмотрены и дополнены.
Настройка Apache для работы с СУБД Caché на Linux
3 min
Tutorial
Вообще говоря, в поставку InterSystems Caché входит встроенный веб-сервер Apache. Встроенный сервер предназначен для разработки и администрирования инстанса Caché и собран с некоторыми ограничениями. Существуют рецепты по устранению этих ограничений, но более общий подход — использовать для продакшена полноценный веб-сервер. В статье рассмотрена настройка Apache для работы с Caché и организация https доступа. Все действия выполнялись на Ubuntu, но настройка на других Linux дистрибутивах ничем принципиально не отличается.
Становимся лучше: тернистый путь программиста. Часть 1
5 min
Translation
Эта статья — вольный перевод статьи «The hardest and easiest way to be a better coder» портала medium.com.
В ней выражена идея, которую обычно не принято озвучивать в индустрии разработки программ.
Эта идея о том, что программисты тоже люди. Но люди, живущие в культуре, отрицающей эмоции в общении.
Автор отличненько описывает нам важный путь развития. И это совсем не вкачивание технических навыков или GTD.
В ней выражена идея, которую обычно не принято озвучивать в индустрии разработки программ.
Эта идея о том, что программисты тоже люди. Но люди, живущие в культуре, отрицающей эмоции в общении.
Автор отличненько описывает нам важный путь развития. И это совсем не вкачивание технических навыков или GTD.
СУБД InterSystems Caché 2014.1. Release Notes
4 min
25 марта 2014 вышел релиз СУБД Caché 2014.1. Что в версии твоей?
Развитие функциональности
Улучшения производительности
Подробнее об этом и многом другом под катом.
Развитие функциональности
- Поддержка REST;
- Globals C API;
- поддержка UDP;
- развитие Caché SQL;
- поддержка Enterprise Manager;
- DeepSee Cube Manager;
- единая модель триггеров для объектов и SQL.
Улучшения производительности
- Повышение производительности TROLLBACK до 40%.
- Диагностика производительности MDX.
- Улучшение производительности запросов с UNION и улучшения в Tune Tables.
- Дефрагментация и сжатие баз данных Caché.
Подробнее об этом и многом другом под катом.
История хакерских взломов информационных систем (1903-1971)
1 min
1903

Фокусник и изобретатель Невил Маскелин сорвал публичную демонстрацию, где Джон Флеминг показывал якобы безопасную беспроводную передачу данных(Маркони), послав оскорбительные сообщения морзянкой, которые высветились на экране перед публикой.
Статья в NewScientist.
Под катом еще несколько старинных «хаков».
Последствия OpenSSL HeartBleed
3 min

HeartBleed может стать, если уже не стала, самой большой информационной уязвимостью вообще.
По какой-то причине, активность дискуссии в оригинальном топике не очень высока, что вызывает у меня крайне высокую степень удивления.
Что произошло?
1 января 2012 года, Robin Seggelmann отправил, а steve проверил commit, который добавлял HeartBeat в OpenSSL. Именно этот коммит и привнес уязвимость, которую назвали HeartBleed.
Насколько она опасна?
Эта уязвимость позволяет читать оперативую память кусками размером до 64КБ. Причем уязвимость двусторонняя, это значит, что не только вы можете читать данные с уязвимого сервера, но и сервер злоумышленника может получить часть вашей оперативной памяти, если вы используете уязвимую версию OpenSSL.Злоумышленник может подключиться к, предположим, уязвимому интернет-банку, получить приватный SSL-ключ из оперативной памяти и выполнить MITM-атаку на вас, а ваш браузер будет вести себя так, будто бы ничего и не произошло, ведь сертификат-то верный. Или просто может получить ваш логин и пароль.
Каков масштаб трагедии?
По моим оценкам, примерно ⅔ вебсайтов используют OpenSSL для HTTPS-соединений, и примерно ⅓ из них были уязвимы до сегодняшнего дня.
Уязвимость была/есть, как минимум, у:
- 10 банков
- 2 платежных систем
- 8 VPN-провайдеров
- mail.yandex.ru
- mail.yahoo.com
Используя уязвимость, с mail.yandex.ru можно было получить письма пользователей вместе с HTTP-заголовками (и, подставив cookie, зайти под этим пользователем), а, например, в АльфаБанке получать незашифрованные POST-данные с логином и паролем от Альфа-Клик (интернет-банкинг).
Критическая уязвимость в OpenSSL 1.0.1 и 1.0.2-beta
2 min
Несколько часов назад сотрудники The OpenSSL Project выпустили бюллетень безопасности, в котором сообщается о критической уязвимости CVE-2014-0160 в популярной криптографической библиотеке OpenSSL.
Уязвимость связана с отсутствием необходимой проверки границ в одной из процедур расширения Heartbeat (RFC6520) для протокола TLS/DTLS. Из-за этой маленькой ошибки одного программиста кто угодно получает прямой доступ к оперативной памяти компьютеров, чьи коммуникации «защищены» уязвимой версией OpenSSL. В том числе, злоумышленник получает доступ к секретным ключам, именам и паролям пользователей и всему контенту, который должен передаваться в зашифрованном виде. При этом не остается никаких следов проникновения в систему.
Установка InterSystems Caché и GlobalsDB на Linux
9 min
Tutorial
Так как у тех, кто впервые устанавливает продукты InterSystems на Linux, часто возникают проблемы в процессе установки, я решил описать этот процесс. На данный момент из бесплатных версий Linux начиная с версии 2014.1 поддерживается CentOS 6.4, поэтому процесс установки буду описывать именно на этой ОС но установка, например, на Ubuntu ничем не отличается (хотя она и не является сейчас официально поддерживаемой InterSystems).
Для установки InterSystems Caché, нам понадобится дистрибутив, если у вас его нет, то вы можете его скачать здесь. Однопользовательская версия, для RedHat, установщик в формате tar.gz. Для установки на Ubuntu нужно брать версию для SuSE Linux. На момент написания статьи доступна версия 2014.1.
Для установки InterSystems GlobalsDB здесь качаем версию Для RedHat, на выбор предлагается Node.js или Java, но это не важно — на скачиваемый файл это не влияет.
Что потребуется
Для установки InterSystems Caché, нам понадобится дистрибутив, если у вас его нет, то вы можете его скачать здесь. Однопользовательская версия, для RedHat, установщик в формате tar.gz. Для установки на Ubuntu нужно брать версию для SuSE Linux. На момент написания статьи доступна версия 2014.1.
Для установки InterSystems GlobalsDB здесь качаем версию Для RedHat, на выбор предлагается Node.js или Java, но это не важно — на скачиваемый файл это не влияет.
Поиск в пространстве состояний
5 min
 Мы продолжаем серию постов про искусственный интеллект, написанных по мотивам выступления в «Технопарке» Mail.ru Константина Анисимовича — директора департамента разработки технологий ABBYY. Вторая статья будет посвящена алгоритмам поиска.
Мы продолжаем серию постов про искусственный интеллект, написанных по мотивам выступления в «Технопарке» Mail.ru Константина Анисимовича — директора департамента разработки технологий ABBYY. Вторая статья будет посвящена алгоритмам поиска.Навигатор по серии постов:
• Искусственный интеллект для программистов
• Применение знаний: алгоритмы поиска в пространстве состояний
• Получение знаний: инженерия знаний и машинное обучение
• Применение знаний: алгоритмы поиска в пространстве состояний
• Получение знаний: инженерия знаний и машинное обучение
В зависимости от того, какой способ представления знаний мы выбрали — декларативный или продукционный — мы определяем способ применения знаний. С продукционной системой все достаточно просто: мы непосредственно интерпретируем продукции.
Если же мы выбрали декларативное представление знаний, то все происходит несколько сложнее. Для этого нам нужно реализовать поиск в пространстве состояний. Дело в том, что структурированное представлений знаний организовано иерархически. А если мы пытаемся применить иерархическое описание к входным данным, то мы на каждом его уровне получим возможные варианты интерпретации данных — гипотезы.
Репортаж с InterSystems Global Summit 2014
2 min
 С 16 по 19 марта в Орландо, Флорида, прошел ежегодный Global Summit проводимый компанией InterSystems. На это мероприятие съезжаются сотни разработчиков и партнеров, работающих с продуктами компании. В этом году собралось более 800 человек. Много кто был со своими родными, которым думаю тоже было чем заняться, потому что в округе много разных парков аттракционов, в одном из которых мы побывали все вместе.
С 16 по 19 марта в Орландо, Флорида, прошел ежегодный Global Summit проводимый компанией InterSystems. На это мероприятие съезжаются сотни разработчиков и партнеров, работающих с продуктами компании. В этом году собралось более 800 человек. Много кто был со своими родными, которым думаю тоже было чем заняться, потому что в округе много разных парков аттракционов, в одном из которых мы побывали все вместе.Под катом небольшой фоторепортаж.
Динамические деревья
8 min
Перед прочтением статьи рекомендую посмотреть посты про splay-деревья (1) и деревья по неявному ключу (2, 3, 4)
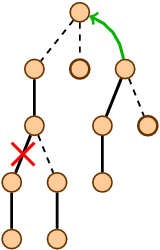 Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
В первом случае динамические деревья позволяют построить эффективные алгоритмы для задачи о поиске максимального потока. Улучшенные алгоритмы Диница и проталкивания предпотока работают за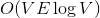 и
и 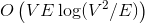 соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
Второй случай требует небольшого введения. Динамические графы — это активно развивающаяся современная область алгоритмов. Представьте, что у вас есть граф. В нем периодически происходят изменения: появляются и исчезают ребра, меняются их веса. Изменения нужно быстро обрабатывать, а еще уметь эффективно считать разные метрики, проверять связность, искать диаметр. Динамические деревья являются инструментом, который позволяет ловко манипулировать с частным случаем графов, деревьями.
Перед тем, как нырнуть под кат, попробуйте решить следующую задачу. Дан взвешенный граф в виде последовательности ребер. По последовательности можно пройти только один раз. Требуется посчитать минимальное покрывающее дерево, используя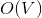 памяти и
памяти и 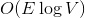 времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы. В первом случае динамические деревья позволяют построить эффективные алгоритмы для задачи о поиске максимального потока. Улучшенные алгоритмы Диница и проталкивания предпотока работают за
и соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.Второй случай требует небольшого введения. Динамические графы — это активно развивающаяся современная область алгоритмов. Представьте, что у вас есть граф. В нем периодически происходят изменения: появляются и исчезают ребра, меняются их веса. Изменения нужно быстро обрабатывать, а еще уметь эффективно считать разные метрики, проверять связность, искать диаметр. Динамические деревья являются инструментом, который позволяет ловко манипулировать с частным случаем графов, деревьями.
Перед тем, как нырнуть под кат, попробуйте решить следующую задачу. Дан взвешенный граф в виде последовательности ребер. По последовательности можно пройти только один раз. Требуется посчитать минимальное покрывающее дерево, используя
памяти и времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.