Примечание переводчика: в текущий момент я подготавливаю материалы для обещанной статьи по монадам. К сожалению, это занимает довольно много времени, не говоря о том, что я всё же должен заниматься основной работой и уделять время семье, но процесс идёт. А пока представляю вам перевод небольшой свежей заметки от замечательного товарища Mark Seemann'а, которая мне показалась любопытной.
Я часто становлюсь участником длительных и жарких дебатов на тему статической типизации против динамической. Сам я определенно отношу себя к сторонникам статической типизации, но эта статья не о достоинствах статической типизации. Цель статьи — устранить распространённое заблуждение насчет статически типизированных языков.
Церемонность
Люди, которые предпочитают динамически типизированные языки статически типизированным, часто подчеркивают тот факт, что отсутствие церемонности делает их продуктивнее. Это звучит логично, однако, это ложная дихотомия.
Церемония — это то, что вы делаете до того, как начнете делать то, что вы действительно собирались сделать.
Venkat Subramaniam
Динамически типизированные языки производят такое впечатление, что им не требуются особые церемонии, но отсюда нельзя сделать вывод что статически типизированные языки их требуют. К сожалению, все мейнстримные статически типизированные языки относятся к одной и той же семье, и они требуют церемонности. Я думаю, что люди экстраполируют то, что они о них знают, ложно заключая что все статически типизированные языки обязательно идут в комплекте с оверхедом церемонности.
Это привело меня к мысли о том, что существует злосчастная Зона Церемонности:
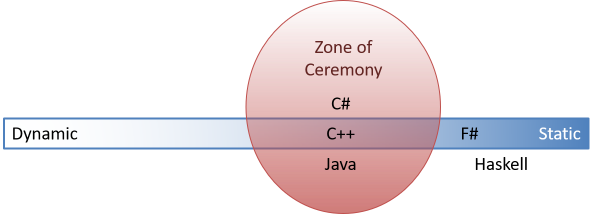
Конечно же, эта диаграмма всего лишь упрощение, но я надеюсь, что она демонстрирует суть. C++, Java и C♯ — языки, которые требуют церемонности. Справа от них находятся языки, которые мы могли бы назвать транс-церемониальными, включая F♯ и Haskell.