Я, как обычно, выступаю в роли попугая-пересмешника и отвечаю на статью длинным постом вместо короткого комментария. Дурацкий опрос в комплекте.

User
Тот же граф, только в другой руке?
Easy
14 min

В 2015 году математик Ласло Бабай представил свой более эффективный алгоритм, решающий задачу изоморфизма графов (Graph Isomorphism, GI) за квазиполиномиальное время. На Хабре даже есть статья, освещающая это событие. Однако в дальнейшем сам учёный признал некоторую ошибочность своего подхода, что всё равно не повлияло на отношение большинства математиков к его открытию, поскольку даже получившийся вариант, решающий задачу за субэкспоненциальное время, оказался эффективнее существующих алгоритмов. Тем не менее учёный не остановился на этом и обнаружил ошибку. Опубликованные исправления алгоритма всё-таки привели к решению задачи изоморфизма за квазиполиномиальное время.
Проблема изоморфизма графов требует алгоритмов, которые могут определить, являются ли два графа структурно идентичными. На протяжении десятилетий эта задача занимала особый статус как одна из немногих естественно возникающих задач, уровень сложности которых трудно определить. Многие годы исследователи пытались выяснить, к чему она относится. Даже сейчас неизвестно, к какому классу относится задача, а абстрактно задачу рассматривают как нечто среднее — сложнее, чем P, но легче NP. Задачу из теории графов можно обобщить до общей проблемы изоморфизма, в смежных областях математики существуют идентичные задачи, например изоморфизм конечных групп.
Исправляем интерфейс диспетчеризации минимальными усилиями
Easy
4 min
Tutorial
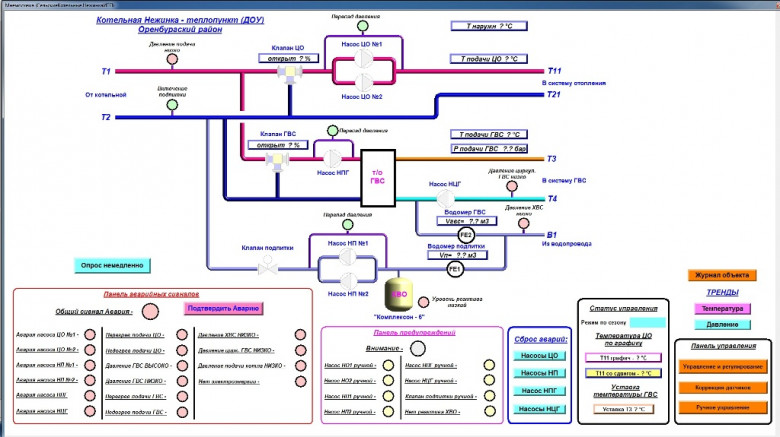
Интерфейсы разные нужны, интерфейсы разные важны. Я довольно давно уже топлю за качественные интерфейсы и за то, что им нужно уделять время и их нужно прорабатывать. Конечно, нужно делать все по сетке, подбирать цвета, отступы, иконки, кнопки и лампы. Очень здорово делать сразу два интерфейса темный и светлый и делать автоматический переход между ними по времени суток. Но еще я прекрасно понимаю, что времени на это очень часто просто нет, да и бюджет не резиновый, чтобы каждый раз привлекать дизайнера. Но что-то делать с этим нужно.
Я возьму рандомную мнемосхему из интернета и пошагово покажу, как минимальными усилиями можно привести в порядок интерфейс, чтобы он стал приятнее для глаз и удобнее для эксплуатации.
Тестировщики тоже продакты: как убедить команду разработки пилить непродуктовую фичу
Easy
10 min
Case

Всем привет! Меня зовут Максим, я работаю тестировщиком в команде Pandora в hh.ru. Наша команда занимается доставкой сообщений пользователям: писем, пушей, смс, сообщений в VK и авторизационных звонков. Подробнее об этом можно почитать в другой статье. У нас была такая проблема: все инциденты, которые не смог решить саппорт, направлялись на уточнение и перепроверку мне. И вот эти 100 запросов и задач в квартал не только фатально сбивали меня, но и тормозили всю команду разработки. Так дальше продолжаться просто не могло.
В этой статье поделюсь историей о том, как я продвинул в команде идею по доработке нашего сервиса для технической поддержки — Aid. Новые фичи призваны дать саппорту возможность самостоятельно решать инциденты с уведомлениями для наших клиентов. А это в свою очередь ощутимо разгрузит меня и разработчиков от задач такого рода.
Об ошибке Н. Вирта и вреде операторов цикла
7 min

На рис. 1 приведена блок-схема алгоритма нахождения наибольшего общего делителя двух натуральных чисел из книги Н. Вирта[1]. С таких алгоритмов, да и с подобных книг, начинается или должно начинаться знакомство с программированием. И, кстати, книга Н.Вирта была одной из первых, с которой в свое время познакомился и я. Так что здесь присутствует и некий личный мотив.
Каково расстояние между «Будапештом» и «Бухарестом» или об отождествлении слов с помощью расстояния Левенштейна
Medium
6 min

Каждый из нас из школы помнит определение Евклидова расстояния между двумя точками на плоскости. С помощью расстояния Евклида можно вычислить расстояние между двумя точками на карте, например, между вашим местоположением и станцией метро. Но для пешехода в Нью-Йорке расстояние между двумя точками в городе будет отличаться от расстояния Евклида между двумя точками из-за невозможности передвигаться иначе, как по проезжим улицам, пересекающимся под прямыми углами. Такое расстояние так и называется: "расстояние городских кварталов" или манхэттенское расстояние. При любом способе расстояние характеризует меру близости точек. В сегодняшней статье мы расскажем о способах вычисления расстояния между двумя словами.
Выбор структур данных для самописного текстового редактора
Medium
13 min
Tutorial
Translation

Программирование текстовых редакторов может быть очень интересной и сложной задачей. Типы задач, которые должны решать текстовые редакторы, варьируются от тривиальных до невероятно трудных. Недавно я занимался переработкой внутренних структур данных редактора, над которым я работаю. В частности, самой фундаментальной для любого текстового редактора структуры данных: текста.
Ресурсы
Прежде чем мы приступим к разбору того, что я сделал, важно упомянуть очень полезные ресурсы для создания собственного текстового редактора:
- Build Your Own Text Editor — наверно, самый фундаментальный пост о создании текстового редактора с нуля, который я видел. Это превосходный туториал на случай, если вы хотите начать писать собственный текстовый редактор. Стоит заметить, что в редакторе из этого туториала в качестве внутренней структуры для текста используется, по сути, вектор строк.
- Text Editor: Data Structures — отличный обзор множества структур данных, которые можно использовать при реализации текстового редактора. (Спойлер: как минимум одна из них будет рассмотрена в моём посте)
- Плейлист Ded (Text Editor) на YouTube — это потрясающая серия, в которой @tscoding фиксирует процесс создания с нуля текстового редактора. Эти видео стали для меня источником вдохновения.
Зачем?
Если в сети есть так много хороших ресурсов о создании собственного текстового редактора (не говоря уже о том, что уже существует множество феноменальных текстовых редакторов), то зачем я это пишу? На то есть несколько причин:
- Я хотел заняться проектом, непохожим ни на один свой прошлый.
- Я хотел создать инструмент, которым смогу пользоваться.
- Мне всегда хотелось глубже разобраться с созданием собственных структур данных.
Архитектура и реактивное программирование
Medium
9 min
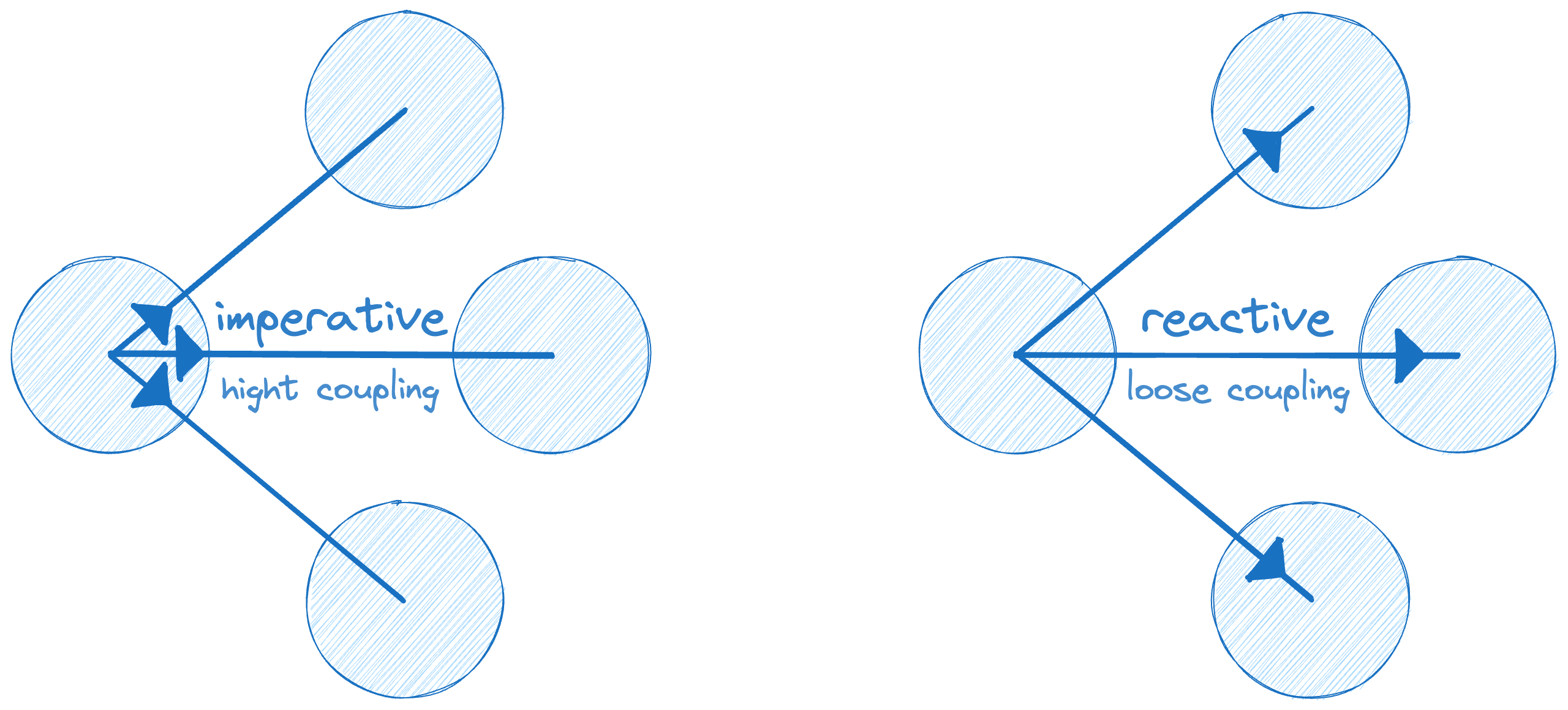
Что такое реактивное программирование? Не Rx. И даже не Excel. Это архитектурный паттерн, позволяющий абсолютно иначе писать код. В статье мы устаканим фундаментальные знания, утвердимся в том, что React.js всё же является реактивным, и подумаем о том, как и когда нужно, а когда не нужно применять паттерны реактивного программирования.
Книга «Рекурсивная книга о рекурсии»
10 min
 Привет, Хаброжители!
Привет, Хаброжители!Книга «Рекурсивная книга о рекурсии» содержит примеры кода на языке Python и JavaScript, которые иллюстрируют основы рекурсии и проясняют фундаментальные принципы всех рекурсивных алгоритмов. Из книги вы узнаете о том, когда стоит использовать рекурсивные функции (и, главное, когда этого не нужно делать), как реализовывать классические рекурсивные алгоритмы, часто обсуждаемые на собеседованиях, а также о том, как рекурсивные методы помогают решать задачи, связанные с обходом дерева, комбинаторикой и другими сложными темами.
Для кого эта книга
Книга предназначена для тех, кого пугают или завораживают рекурсивные алгоритмы. Для большинства новичков понимание рекурсии сродни искусству владения черной магией. В примерах рекурсии далеко не всегда легко разобраться, из-за чего сам предмет вызывает недоумение и даже страх. Я надеюсь, что четкие объяснения и многочисленные примеры, приведенные в книге, помогут читателям наконец освоить эту тему.
Единственным минимальным условием для изучения книги является наличие базового опыта программирования на языке Python или JavaScript, на которых написан код в листингах. Код в книге сведен к самой сути: если вы умеете вызывать и создавать функции, а также различать глобальные и локальные переменные — вы знаете достаточно, чтобы разобраться в этих примерах.
Единственным минимальным условием для изучения книги является наличие базового опыта программирования на языке Python или JavaScript, на которых написан код в листингах. Код в книге сведен к самой сути: если вы умеете вызывать и создавать функции, а также различать глобальные и локальные переменные — вы знаете достаточно, чтобы разобраться в этих примерах.
Шаблон проектирования: Composite
Easy
9 min
Review
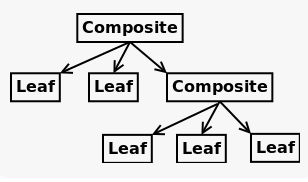
Всем привет! В данной статье рассмотрим паттерн проектирования Composite («Компоновщик»).
Начнем немного с теории.
Паттерн Composite, исходя уже с самого названия, позволяет скомпоновать объекты в структуры по типу «дерева», для предоставления иерархии от частного к целому, а также позволяя клиентам единообразно трактовать отдельные и составные объекты этого дерева. Данный паттерн используется для группировки мелких компонентов в более крупные, которые в свою очередь, могут стать основой для еще более крупных структур.
«Интерфейс. Новые направления в проектировании компьютерных систем» Раскина
7 min
Ключевые мысли из умной книжки книги своими словами для того, чтобы понять: не все существующие подходы правильные и не все кажущиеся удобными решения на самом деле таковы.
Почему изучать программирование так сложно?
13 min
Translation

Коля был простым «белым воротничком» в офисе и решил, что хочет научиться программировать, поэтому он поспрашивал вокруг с чего начать. Он начал с изучения Ruby, а затем пробежался по другим языкам, таким как Scala, Clojure и Go. Он изучал Emacs, затем Vim и даже раскладку клавиатуры Дворжака. Он брался за Linux, баловался Lisp и кодировал на Python, живя в командной строке более полугода.
Советы, которые получал Коля, дёргали его сначала в одну сторону, потом в другую, и так далее, как лист в торнадо, пока он, наконец, не прошёл «каждый мыслимый и немыслимый онлайн-курс». В конце концов, несмотря на то, что в итоге он получил работу в разработке, Коля:
Онлайн курсы по программированию и что они дают на самом деле
4 min
По работе я постоянно имею дело с поиском программистов под разнообразные проекты. Последние четыре года я также отсматриваю стажеров для нашей компании, так как являюсь в ней автором и основным двигателем программы IT стажировки. Здесь не будем касаться вопроса, зачем это нужно в принципе, скажу только, что стажировка вещь полезная, плюс мне нравится передавать свои знания людям.
Все то время, что я подбираю стажеров, я имею дело в основном с выходцами из других профессий. Типичный стажер – человек, который окончил ВУЗ по любому другому профилю (медики, учителя, админы, маркетологи, кого только не было), получил опыт работы по специальности и решил, что ему надо что-то другое. Мотивация перемены области деятельности, как я понимаю, обычно деньги и комфорт. Есть поверье, что средний начинающий программист – это человек, который работает из дома три часа в день, а остальное время купается в деньгах как Скрудж МакДак.
Все эти чудесные люди практически в обязательном порядке проходят некие онлайн курсы и сразу по прохождении размещают резюме на вакансию junior-программист с ценником от 50 000 рублей.
Но мы сейчас, безусловно, говорим не о деньгах и трудностях выбора профессии. Я хочу поговорить о том, чему на этих курсах можно научиться с нуля, и почему просто курсы – это недостаточно для начала работы. В конце бонусом напишу, что думаю про массовое перетекание всех специалистов в область программирования.
PowerShell: обход и визуализация HTML-дерева из файла
8 min
Tutorial
Вывод HTML-дерева из локального файла в окно программы-оболочки «Windows PowerShell» версии 5.1 (или в окно программы-оболочки «PowerShell» версии 7) с помощью скрипта на языке PowerShell в операционной системе «Windows 10». Используется библиотека «HTML Agility Pack».
В качестве упражнения в алгоритмах и структурах данных рассмотрено несколько способов обхода и вывода HTML-дерева: NLR (прямой с приоритетом обхода потомков слева направо), NRL (прямой с приоритетом обхода потомков справа налево), LRN (обратный). Примеры практической реализации.
Автоматное программирование: определение, модель, реализация
36 min

Термин «автоматное программирование» (АП) был введен в широкую практику в 90-х годах прошлого века [1, 2], хотя о применении автоматов в программировании шла речь задолго до этого. R первым упоминаниям уже начала 70-х годов можно отнести метод введения переменной состояния или, по-другому, метод преобразования неструктурированных программ Ашкрофта и Манны [3]. За прошедшее время сформировалось достаточное число его поклонников и не меньшее число критиков. Если говорить об их разногласиях, то в их основе отсутствие формального определения АП и поверхностное восприятие его возможностей. Из-за этого автоматное программирование формируется интуитивно, что и приводит к противоречивым его формам, порой, мало похожим на первоисточник – модель конечного автомата.
Эксперименты. Или как понять, удачная ли была фича?
4 min
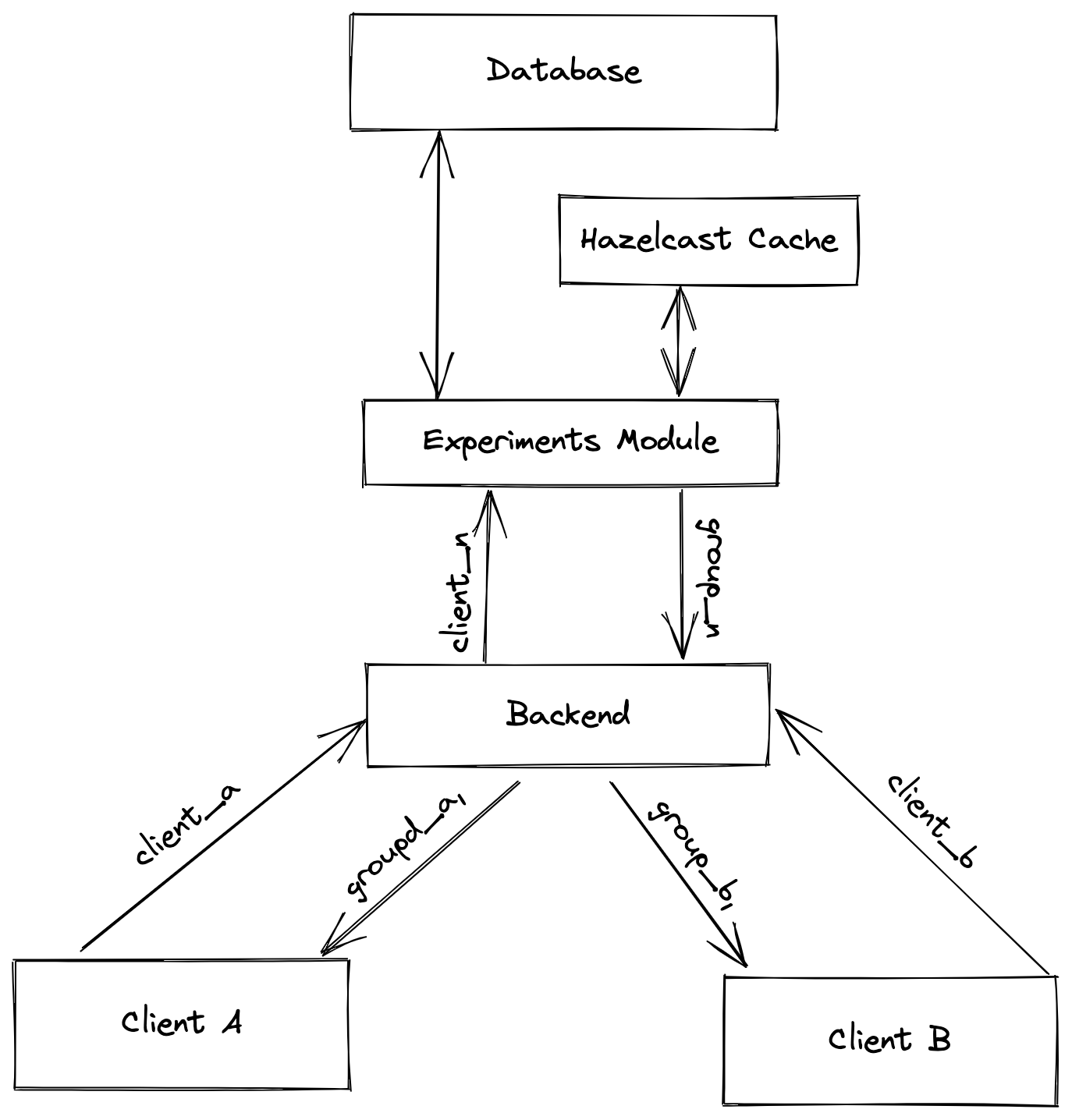
За время работы с программными продуктами в различных сферах бизнеса мне не раз приходилось участвовать в принятии решений о том, какой функционал нужно выпустить в первую очередь и как он должен выглядеть. Мы использовали совершенно разные подходы для решения такой задачи, начиная с мнения разработчиков и заканчивая анализом поведения пользователей и его влияния на прибыль компании. В этой статье я хотел бы поделиться своим опытом в этой сфере и, возможно, помочь вам избежать ошибок.
Как стажёр оптимизировал запросы и нашел баг в Django
10 min

Недавно я нашел баг в Django, создал тикет с исправлением и его приняли.
В статье расскажу подробнее — над чем работал, в чем была ошибка и почему ее сложно встретить. А также еще про один баг, который по классике оказался фичей 😊.
Устранение утечек памяти с помощью профилирования
23 min
Translation
Если система работает длительное время, объём свободной памяти может уменьшаться, что может приводить к отказу некоторых сервисов. Это типичная проблема утечки памяти, которую обычно сложно спрогнозировать и выявить. Удобными инструментами для решения подобных проблем являются профайлеры кучи. Они отслеживают распределение памяти и помогают разобраться, что находится в куче программы, а также найти утечки памяти.
В этой статье мы расскажем об использовании профайлеров кучи, а также объясним, как спроектированы и реализованы популярные профайлеры кучи, например, профайлер кучи Go, gperftools, jemalloc и Bytehound.
Сужение данных. Продолжение борьбы с переполнением
7 min

Все началось с глупой ошибки. В тексте программы вместо оператора x=20; где x – целая переменная со знаком и размером в байт, случайно написали x=200;
И компилятор, что называется не моргнув глазом, сформировал команду записи в переменную x константы 0C8H, что вообще-то соответствовало оператору x=-56; Выяснилось, что за долгие годы эксплуатации этого компилятора ни одна собака ни один пользователь (включая и нас самих) никогда не писал подобных ляпов и поэтому ошибка в компиляторе оставалась незамеченной. А виноваты оказались команды сужения данных.
В чем проблема с базами данных «ключ-значение» и как ее решают Wide-column-хранилища
2 min
Translation

Базы данных «ключ-значение» великолепные — ультрабыстрые, простые, почти линейно масштабируемые по количеству узлов. Но с ними все не так просто. Команда VK Cloud Solutions перевела статью о том, какие у таких баз есть проблемы и как их решить с помощью Wide-column-хранилищ.
Проблемы с базами данных «ключ-значение»
Основная концепция базы данных «ключ-значение» в том, что сами значения ее не беспокоят. Ее работа основана на некоторых допущениях, например, как у Redis, но на структуру данных она вообще не обращает внимания. Из-за этого могут возникнуть три проблемы.