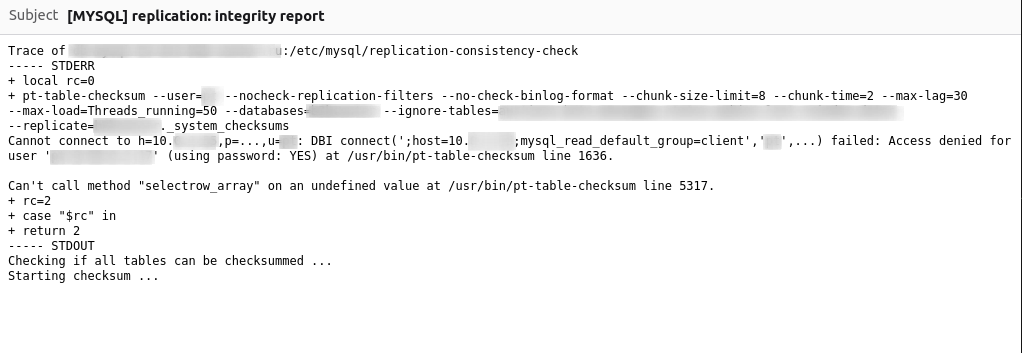
Разворачивая у нас в Туту Keycloak мы столкнулись с необходимостью создания отказоустойчивого кластера. И если с БД всё более менее понятно, то вот реализовать корректный обмен кэшами между Keycloak оказалось довольно непростой для настройки задачей.
Мы упёрлись в то, что в документации Keycloak описано как создать кластер используя UDP мультикаст. И это работает, если у вас все ноды будут находиться в пределах одного сегмента сети (например ЦОДа). Если с этим сегментом что‑то случится, то мы лишимся Keycloak. Нас это не устраивало.
Необходимо сделать так, чтобы ноды приложения были географически распределены между ЦОД, находясь в разных сегментах сети.
В этом случае в документации Keycloak довольно неочевидно предлагается создать свой собственный кастомный JGroups транспортный стэк, чтобы указать все необходимые вам параметры.
Бонусом приложу shell скрипт, написанный для Consul, который предназначен для снятия анонсов путём выключения bird и попытки восстановления приложения.