Я, исследуя устойчивость хранения данных в облачных системах, решил проверить себя, убедиться в том, что понимаю базовые вещи. Я
начал с чтения спецификации NVMe для того чтобы разобраться с тем, какие гарантии, касающиеся устойчивого хранения данных (то есть — гарантии того, что данные будут доступны после сбоя системы), дают нам NMVe-диски. Я сделал следующие основные выводы: нужно считать данные повреждёнными с того момента, как отдана команда записи данных, и до того момента, как завершится их запись на носитель информации. Однако в большинстве программ для записи данных совершенно спокойно используются системные вызовы.
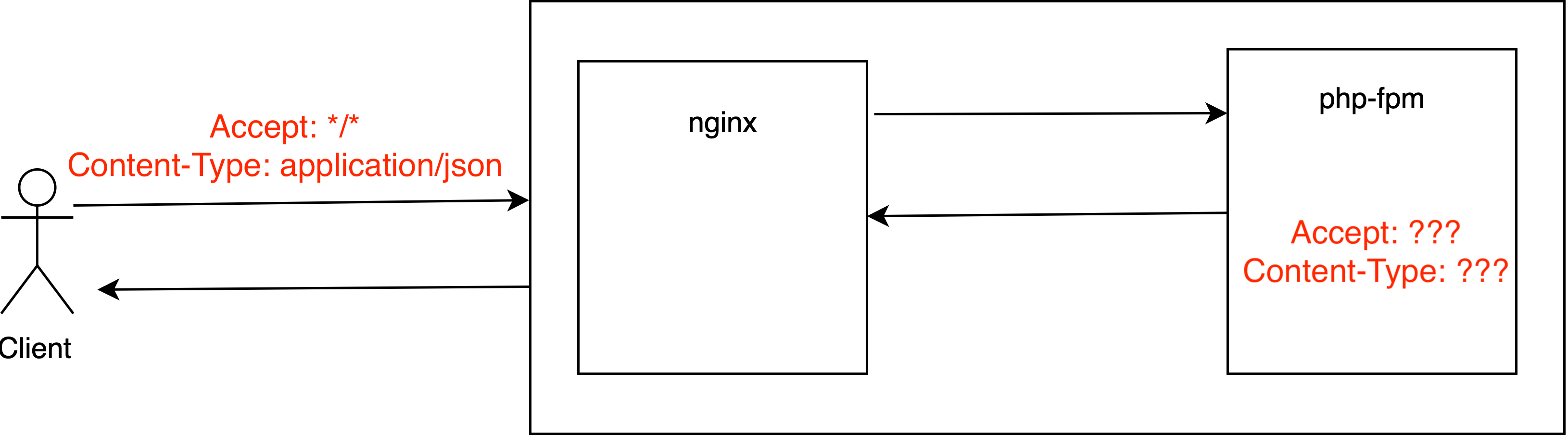
В этом материале я исследую механизмы устойчивого хранения данных, предоставляемые файловыми API Linux. Кажется, что тут всё должно быть просто: программа вызывает команду
write(), а после того, как работа этой команды завершится, данные будут надёжно сохранены на диске. Но
write() лишь копирует данные приложения в кеш ядра, расположенный в оперативной памяти. Для того чтобы принудить систему к записи данных на диск, нужно использовать некоторые дополнительные механизмы.

В целом, этот материал представляет собой набор заметок, касающихся того, что я узнал по интересующей меня теме. Если очень кратко рассказать о самом важном, то получится, что для организации устойчивого хранения данных надо пользоваться командой
fdatasync() или открывать файлы с флагом
O_DSYNC. Если вам интересно в подробностях узнать о том, что происходит с данными на пути от программного кода к диску, взгляните на
эту статью.




 Я кратко расскажу о процессе разработки
Я кратко расскажу о процессе разработки 






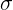 массы конфеты при производстве не превышает
массы конфеты при производстве не превышает 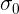 =1,2248, то данная величина не ограничена сверху.
=1,2248, то данная величина не ограничена сверху.