
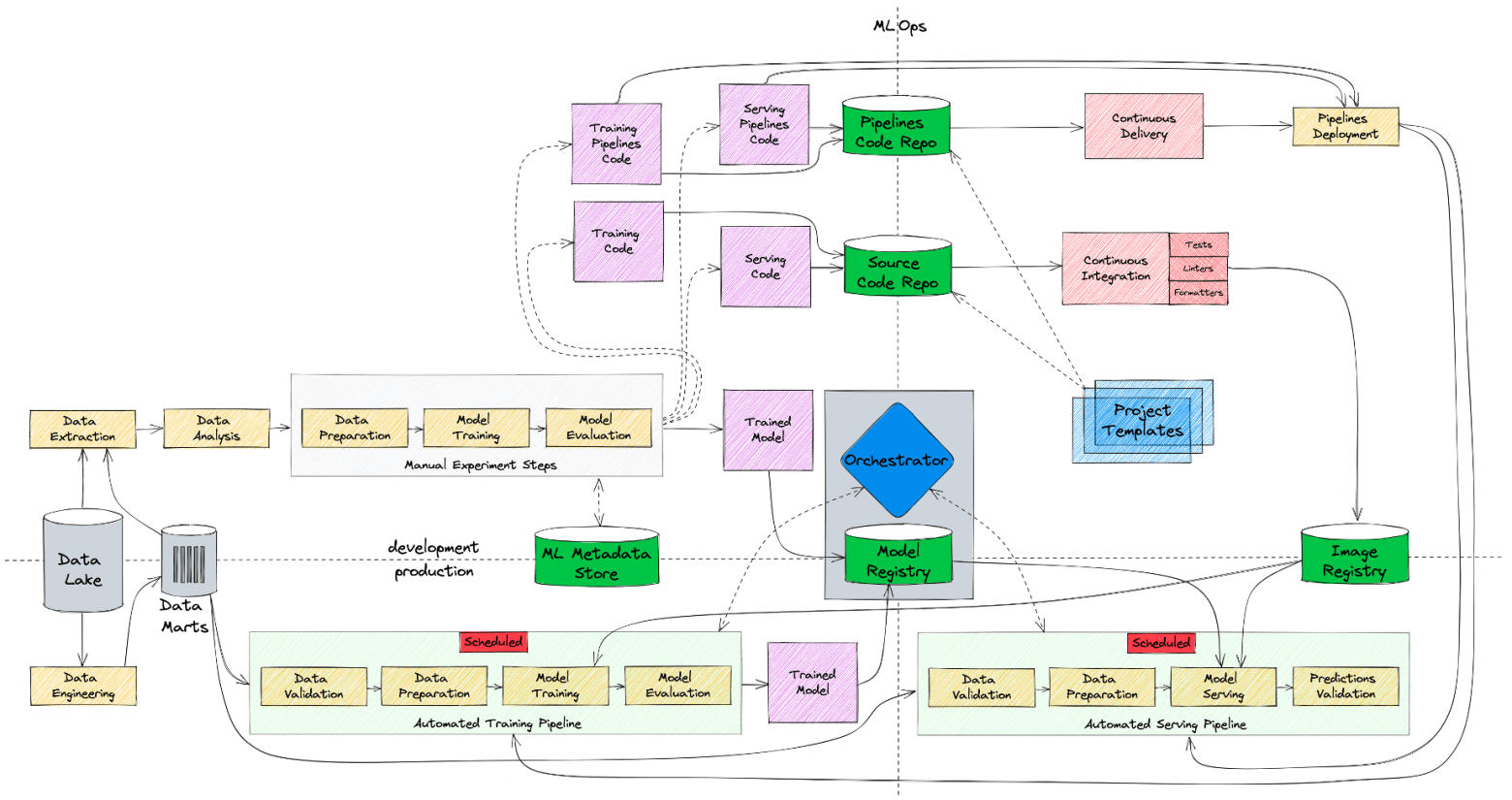
Всем привет! Меня зовут Николай Безносов, я отвечаю за применение и развитие машинного обучения и продвинутой аналитики в билайне. В одной из прошлых статей мои коллеги рассказывали о месте Seldon в ML-инфраструктуре компании, а сегодня мы поднимемся на уровень выше и поговорим о том, что из себя представляет MLOps в билайне в целом - как с точки зрения инфраструктуры, так и с точки зрения процессов.
В статье речь пойдет о нашем опыте создания ML-платформы, которая помогает дата-сайентистам самостоятельно управлять всем жизненным циклом ML-моделей - от разработки до постановки в production. Я рассчитываю, что статья будет полезна как небольшим командам, которые только начинают выстраивать у себя ML-инфраструктуру, так и корпорациям с большим количеством команд и жесткими требованиями к безопасности, которые при этом хотят эффективно масштабироваться.
Статья будет состоять из двух частей. В первой части мы посмотрим верхнеуровнево, как и по каким причинам менялись наши ML-процессы и инфраструктура в билайне - с чего мы начинали и к чему в итоге пришли. Во второй части поговорим о конкретных инструментах и технологиях, которые мы внедрили, чтобы сделать наш процесс разработки и деплоя моделей простым, воспроизводимым, автоматизируемым и наблюдаемым.





 . Поговорим также о выводах, которые можно из этого сделать.
. Поговорим также о выводах, которые можно из этого сделать.





{kind=link}