
Продолжаем публиковать материалы наших образовательных проектов. В этот раз предлагаем ознакомиться с лекциями Техносферы по курсу «Алгоритмы интеллектуальной обработки больших объемов данных». Цель курса — изучение студентами как классических, так и современных подходов к решению задач Data Mining, основанных на алгоритмах машинного обучения. Преподаватели курса: Николай Анохин (@anokhinn), Владимир Гулин (@vgulin) и Павел Нестеров (@mephistopheies).
Объемы данных, ежедневно генерируемые сервисами крупной интернет-компании, поистине огромны. Цель динамично развивающейся в последние годы дисциплины Data Mining состоит в разработке подходов, позволяющих эффективно обрабатывать такие данные для извлечения полезной для бизнеса информации. Эта информация может быть использована при создании рекомендательных и поисковых систем, оптимизации рекламных сервисов или при принятии ключевых бизнес-решений.
Объемы данных, ежедневно генерируемые сервисами крупной интернет-компании, поистине огромны. Цель динамично развивающейся в последние годы дисциплины Data Mining состоит в разработке подходов, позволяющих эффективно обрабатывать такие данные для извлечения полезной для бизнеса информации. Эта информация может быть использована при создании рекомендательных и поисковых систем, оптимизации рекламных сервисов или при принятии ключевых бизнес-решений.
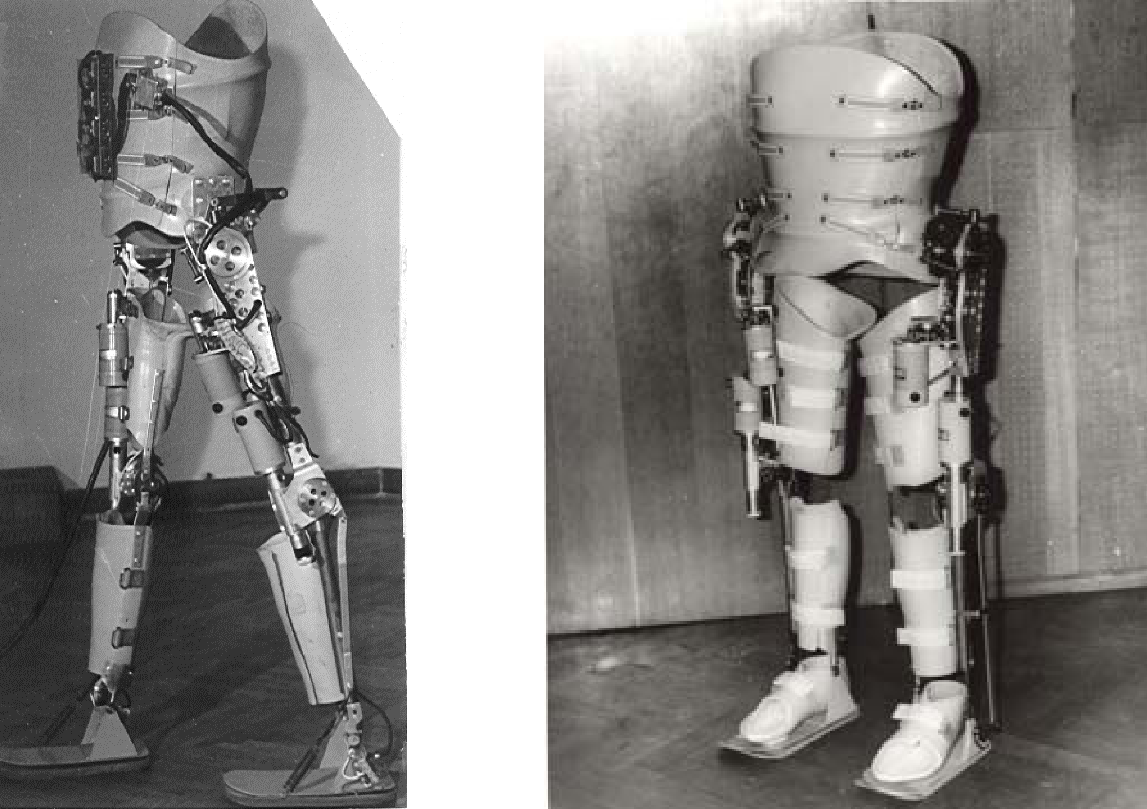


 Это перевод
Это перевод 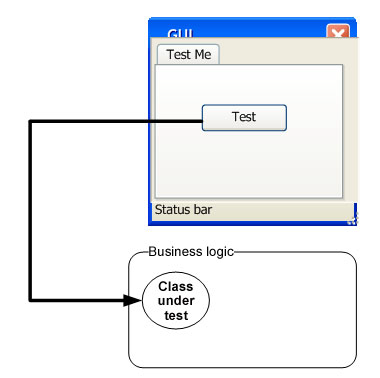

 Давным-давно, когда я был ещё наивным школьником, мне вдруг стало жутко любопытно: а каким же волшебным образом данные в архивах занимают меньше места? Оседлав свой верный диалап, я начал бороздить просторы Интернетов в поисках ответа, и нашёл множество статей с довольно подробным изложением интересующей меня информации. Но ни одна из них тогда не показалась мне простой для понимания — листинги кода казались китайской грамотой, а попытки понять необычную терминологию и разнообразные формулы не увенчивались успехом.
Давным-давно, когда я был ещё наивным школьником, мне вдруг стало жутко любопытно: а каким же волшебным образом данные в архивах занимают меньше места? Оседлав свой верный диалап, я начал бороздить просторы Интернетов в поисках ответа, и нашёл множество статей с довольно подробным изложением интересующей меня информации. Но ни одна из них тогда не показалась мне простой для понимания — листинги кода казались китайской грамотой, а попытки понять необычную терминологию и разнообразные формулы не увенчивались успехом. CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.
CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.
 Существует множество задач, для которых требуется пересборка ядра и операционной системы Android в целом. Например, создание и отладка собственных модулей, включение поддержки профилирования системы и просто тестирование своих приложений на новой версии Android.
Существует множество задач, для которых требуется пересборка ядра и операционной системы Android в целом. Например, создание и отладка собственных модулей, включение поддержки профилирования системы и просто тестирование своих приложений на новой версии Android.