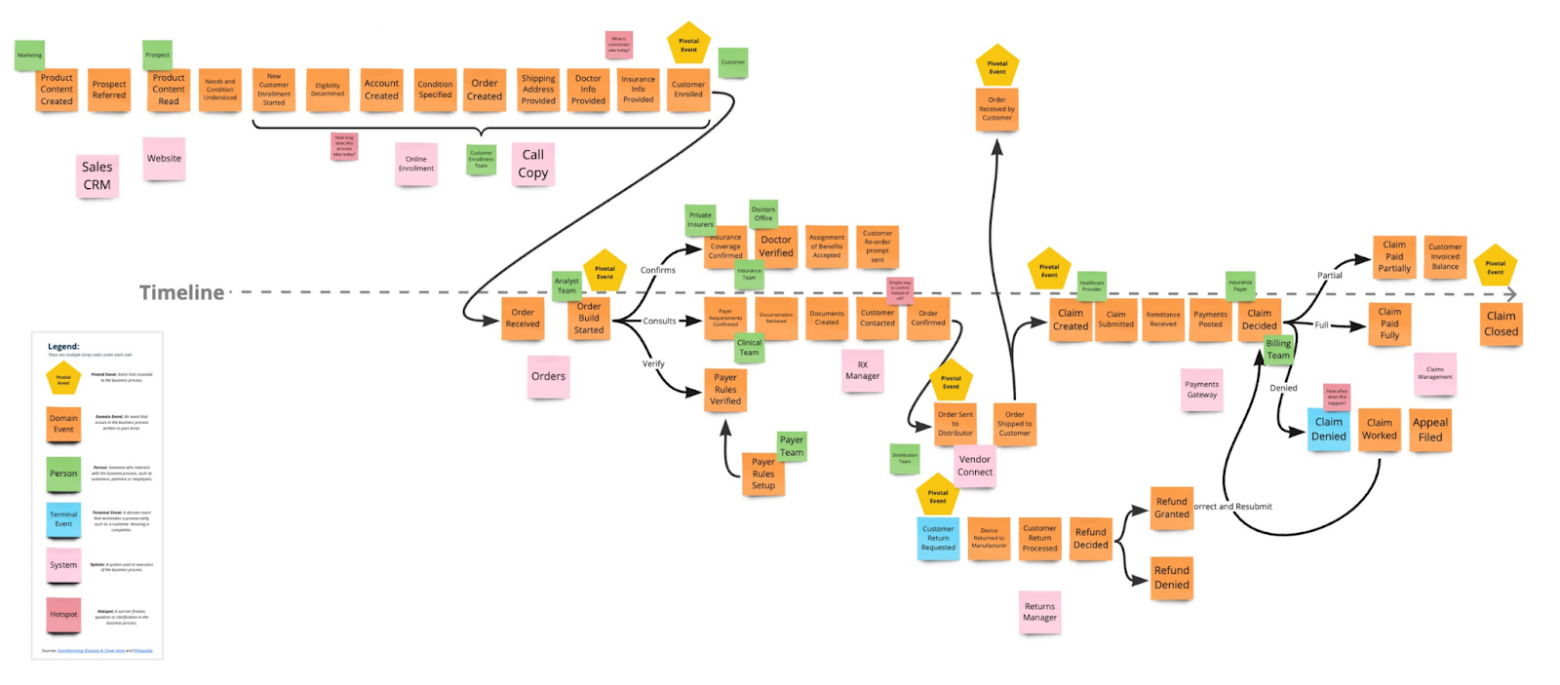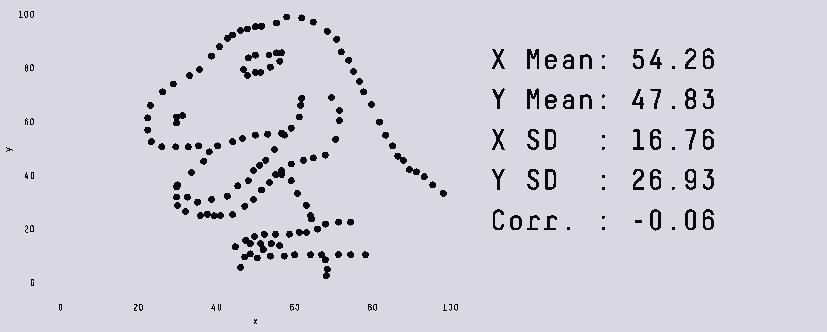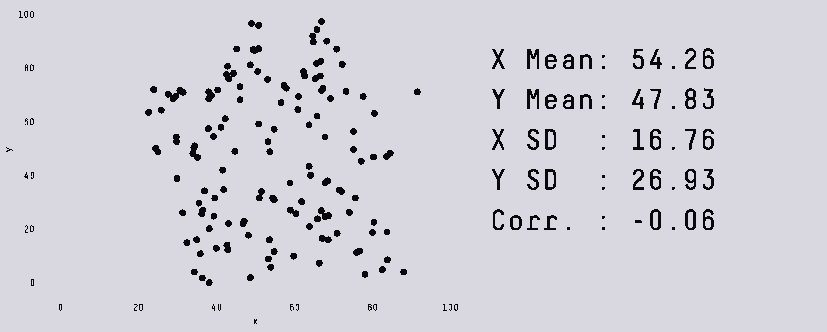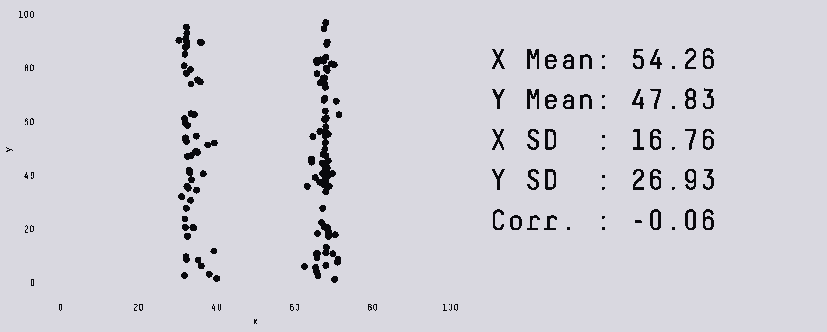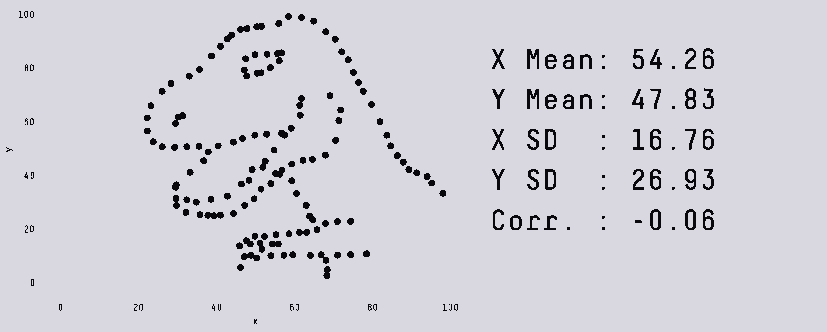
Представьте себе такую картину: близится конец цикла разработки, ваша игра едва ползает, но в профайлере вы не можете найти очевидных проблемных мест. Кто же виноват? Паттерны произвольного доступа к памяти и постоянные промахи кеша. Пытаясь повысить производительность, вы пробуете распараллелить части кода, но это стоит героических усилий, и в конечном итоге из-за всей синхронизации, которую пришлось добавить, ускорение едва заметно. К тому же код настолько сложен, что исправление багов вызывает ещё больше проблем, и мысль о добавлении новых возможностей сразу отбрасывается. Звучит знакомо?
Такое развитие событий довольно точно описывает почти каждую игру, в разработке которой я участвовал на протяжении последних десяти лет. Причины заключаются не в языках программирования и не в инструментах разработки, и даже не в отсутствии дисциплины. По моему опыту, в большой степени в этом стоит винить объектно-ориентированное программирование (ООП) и окружающую его культуру. ООП может не помогать, а мешать вашим проектам!