Сегодня расскажем о выборе CNI: что мы использовали в Calico, в каких конфигурациях и как применяем Cilium.

Инженер
Сегодня расскажем о выборе CNI: что мы использовали в Calico, в каких конфигурациях и как применяем Cilium.

Ранее я рассказывал о том, как запустить PostgreSQL в Docker. Тогда речь шла об использовании «ванильных» образов Postgres и поднятии одного хоста. В большинстве случаев этого достаточно как для тестов, так и для экспериментов, но нужно понимать, что в промышленной эксплуатации чаще всего используются высокодоступные (отказоустойчивые, кластеризованные) конфигурации PostgreSQL.
Сегодня я покажу, как запустить уже целый кластер PostgreSQL в Docker, а также в тестах через Testcontainers, и как вручную инициировать смену мастер-хоста.


Payload (данные) в ping пакете действительно есть, однако до реальной пользы им далеко - это английский алфавит (нет, я не испытываю ненависть к латинице, просто мне хотелось бы уметь редактировать это содержимое).

Mojo — это новый язык программирования, основанный на Python, который устраняет имеющиеся у него проблемы производительности и развёртывания.
Об авторе: Джереми Говард (Jeremy Howard) — Data Scientist, исследователь, разработчик, преподаватель и предприниматель. Джереми является одним из основателей исследовательского института fast.ai, занимающегося тем, чтобы сделать глубокое обучение более доступным, а также он является почётным профессором Университета Квинсленда. Ранее Джереми был выдающимся научным сотрудником в Университете Сан‑Франциско, где он был основателем Инициативы Уиклоу «Искусственный интеллект в медицинских исследованиях».
Этот пост является версией моей же англоязычной статьи "How to avoid gotchas in Go", но слово gotcha не переводится на русский, поэтому я буду использовать это слово как без перевода, так и немного непрямой вариант — "наступать на грабли".
Gotcha — корректная конструкция системы, программы или языка программирования, которая работает, как описано, но, при этом, контринтуитивна и является причиной ошибок, поскольку её легко использовать неверно.
В языке Go есть несколько таких gotchas и есть немало хороших статей, которые их подробно описывают и разъясняют. Я считаю, что эти статьи очень важны, особенно для новичков в Go, поскольку регулярно вижу людей, попадающихся на те же грабли.
Но один вопрос меня мучал долгое время — почему я сам никогда не делал этих ошибок? Серьезно, самые популярные из них, вроде путаницы с nil-интерфейсом или непонятного результата при append()-е слайса — в моей практике никогда не были проблемой. Каким-то образом мне повезло обойти эти подводные камни с первых дней своей работы с Go. Что же мне помогло?
И ответ оказался довольно прост. Я просто очень вовремя прочёл несколько хороших статей о внутреннем устройстве структур данных в Go и прочих деталях реализации. И этого, вполне поверхностного на самом деле, знания было достаточно, чтобы выработать некоторую интуицию и избегать этих подводных камней.
Можно любить Go за многое: за простоту и строгость, за горутины и каналы, за реализацию параллельного и асинхронного программирования, за продвинутый планировщик, за аллокатор с большим количеством оптимизаций, за высокую производительность.
Но, по сообщениям некоторых пользователей, у программ, написанных на Go, течёт память. Issue-трекер языка Go на github по запросам «high memory usage», «memory leak», «out of memory» выдаёт сотни и тысячи тикетов. А в самом популярном вопросе на stackoverflow по словосочетанию «golang memory» автор пытается разобраться, почему потребление оперативной памяти в рантайме в 4 раза превышает количество реально сделанных аллокаций. Обращения, в которых люди рапортуют о перерасходе оперативной памяти в Go, стали массовым явлением.
Что же это — утечки памяти, вызванные программистскими ошибками, или ожидаемое поведение рантайма языка? Мы попытаемся разобраться в причинах этого явления и сформулировать общие рекомендации, которые помогут в отладке проблем с потреблением памяти.

Мы продолжаем наш рассказ о причинах повышенного потребления памяти в языке Go. В предыдущей статье мы детально разобрали ошибки бизнес-логики приложения, которые могут привести к утечкам памяти. Сегодня же сосредоточимся на особенностях рантайма языка Go.
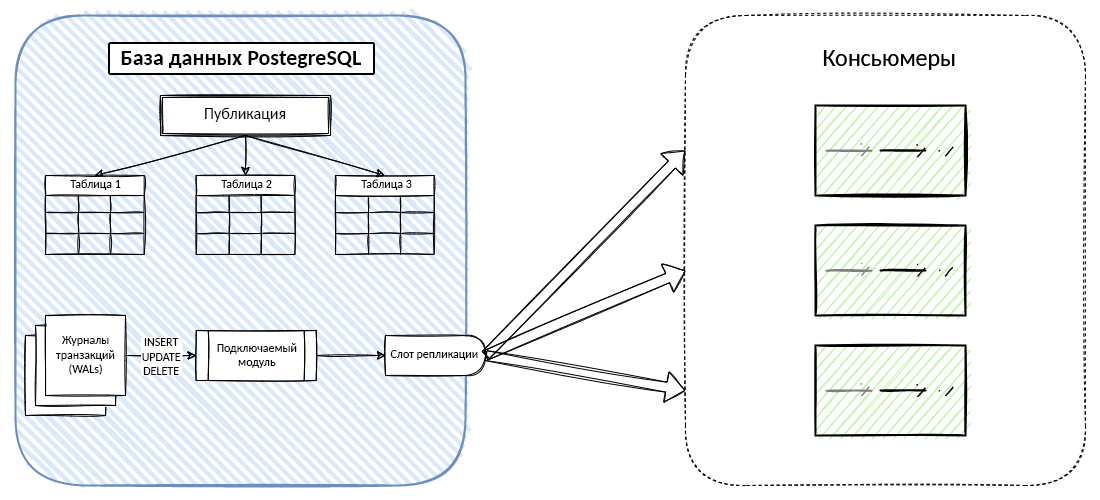
Отслеживание изменённых данных (CDC) — это метод интеграции данных для обнаружения, захвата и передачи изменений, внесённых в источники данных базы данных.Как правило, интеграция данных на основе CDC состоит из следующих шагов:

Спрос на бэкенд-разработчиков — а Go неотделим от бэкенд-программирования — стабильно растет. У самого же Golang немало плюсов: простой, строгий, статически типизированный, он обладает развитой стандартной библиотекой и славится поддержкой параллельного и асинхронного программирования. При этом в Golang нет классов и нет поддержки наследования, что значительно повышает удобство поддержки кода. Благодаря этим и другим преимуществам Go в последние годы сохраняет статус популярного и перспективного языка.
В МойОфис мы широко используем Go в качестве основного языка для разработки корпоративной почты нового поколения Mailion. При этом разрабатываем на нём не только микросервисы, но и собственное хранилище с поддержкой дедупликации (про устройство Mailion читайте здесь). В связи с этим мы постоянно следим за книжными новинками и актуальными темами современной бэкенд-разработки. Специальной литературы по теме Golang существует немало, однако с помощью наших разработчиков мы выбрали самые важные, профессионально полезные и увлекательно написанные издания.
Делимся рекомендациями книг под катом!

В процессе изучения разных алгоритмов и структур данных приходит понимание, что не все они применимы в прикладных задачах (в отличие от задач про Васю и Петю/Алису и Боба). Но тот факт, что алгоритм/структура данных не является полезной на практике не означает, что идеи в них содержащиеся не привлекают пытливые умы даже из чистого любопытства. Потому речь пойдёт о красивых (субъективно) и, что важно, простых с точки зрения концепции структурах данных.
Помните: если что-то не компилируется, это псевдокод.



Время от времени приходится слышать мнение от некоторых системных администраторов, а также некоторых 1С-разработчиков, что установка, настройка и поддержка PostgreSQL под Linux очень сложна. Что гораздо дешевле покупать лицензии Windows и Microsoft SQL Server, чем нанимать высококвалифицированных администраторов, которые будут администрировать все эти open-source системы.
На наших бизнес-приложениях, использующих в качестве СУБД PostgreSQL, работают 70% крупнейших розничных сетей в Беларуси. Во всех из них одновременно работают от 500 до 1500 пользователей. В приложениях реализованы практически все основные процессы розничных сетей (демо, чтобы оценить сложность). Размер баз данных на данный момент составляет от 2 до 4ТБ. И все они работают практически со стандартными настройками PostgreSQL на одиночных серверах без какой-либо кластеризации. При этом даже в самых загруженных серверах есть еще значительный резерв по ресурсам для дальнейшего увеличения нагрузки без потребности в кластеризации.
Да, конечно же, многое зависит от запросов к СУБД, и несколькими кривыми запросами можно положить весь сервер. Однако, точно также можно положить и Oracle, и MSSQL. Да, платформа lsFusion, на которой написаны наши приложения, делает много различных оптимизаций запросов конкретно под PostgreSQL. Но вручную SQL-запросы можно оптимизировать еще лучше.
В этой статье я полностью опишу все настройки PostgreSQL (и немножко ОС), которые мы делаем на наших системах. Кроме того, мы специально стараемся не изменять те настройки, которые не дают видимого изменения в производительности, чтобы потом не гадать, почему в одном окружении есть проблема, а в другом - нет.
[...] Не надо размышлять, почему здесь нет оператора if. Важно посмотреть на задачу с другой стороны и переписать её так, чтобы особый случай исчез и стал обычным случаем, и это хороший код. — Л. Торвальдс
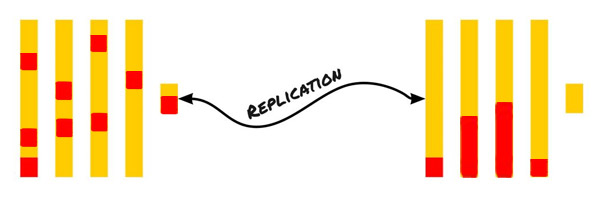
Моя команда использует ClickHouse как хранилище для 100 млрд записей с трафиком по 300 млн в сутки и поиском по таблице. Я расскажу об устройстве движка таблиц MergeTree. Рассказ буду вести, показывая физические данные, а не абстрактные схемы.