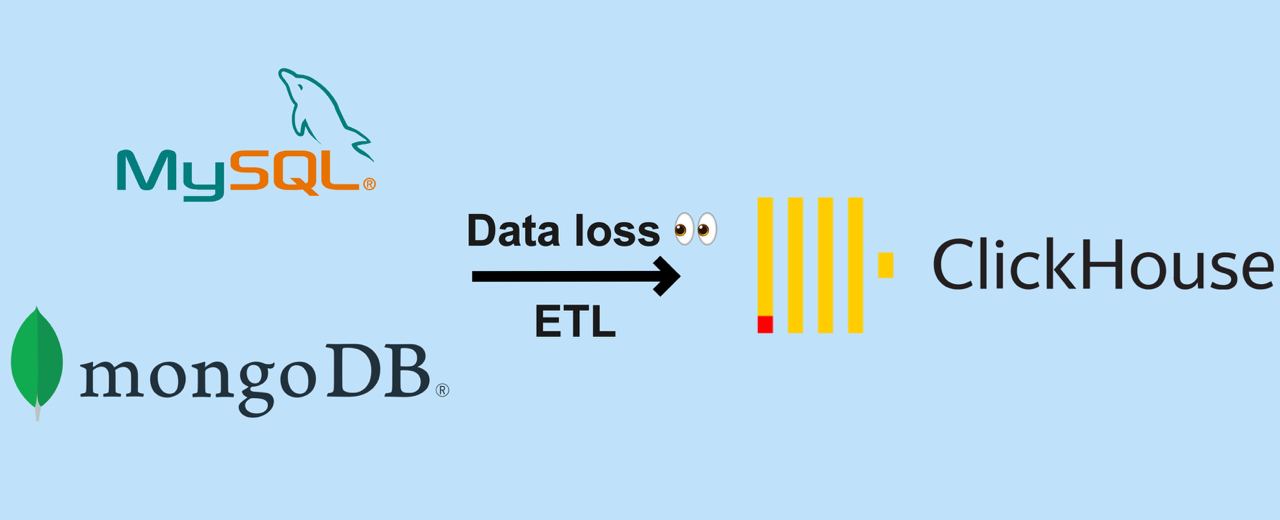
Данные из боевых баз в нашей архитектуре асинхронно попадают в аналитическое хранилище (Clickhouse), где уже аналитики создают дашборды для продуктовых команд и делают выборки. Базы здоровые и под ощутимой нагрузкой: мы в день отправляем флот самолётов средней авиакомпании, несколько поездов и кучу автобусов. Поэтому взаимодействий с продуктом много.
ETL-процесс (извлечение данных, трансформация и загрузка в хранилище) часто подразумевает сложную логику переноса данных, и изначально нет уверенности в том, что данные доставляются без потерь и ошибок. Мы используем Kafka как шину данных, промежуточные сервисы на Benthos для трансформации записей и отправки в Clickhouse. На этапе создания пайплайна нужно было убедиться в отсутствии потерь с нашей стороны и корректной логике записи в шину данных.
Проверять вручную расхождения каждый раз не хотелось, кроме того мы нуждались в сервисе, который умел бы сверять новые данные по расписанию и показывать наглядно, где и какие имеются расхождения. Поэтому мы сделали сервис сверок, о котором я и расскажу, потому что готовых решений не нашёл.