Во время собеседований на роль linux/unix администратора во многих IT-компаниях спрашивают, что такое load average, чем nginx отличается от apache httpd и что такое fork. В этой статье я постараюсь объяснить, что рассчитывают услышать в ответ на эти вопросы, и почему.
Здесь важно очень хорошо понимать основы администрирования. В идеальной ситуации при постановке задачи системному администратору выставляют ряд требований. Если же ситуация не идеальная, то, по сути, требование к администратору одно: «Хочу, чтобы всё работало». Иными словами, сервис должен быть доступен 24/7 и, если какое-то решение не удовлетворяет этим требованиям (масштабирование и отказоустойчивость относятся к доступности), то можно сказать, что администратор плохо сделал свою работу. Но если разные решения двух администраторов работают 24/7, как понять, какое из них лучше?
Хороший системный администратор при выборе решения при заданных требованиях ориентируется на два условия: минимальное потребление ресурсов и их сбалансированное распределение.
Вариант, когда одному специалисту нужно 10 серверов для выполнения задания, а второму всего 2, мы рассматривать не будем, что тут лучше – очевидно. Далее под ресурсами я буду понимать ЦПУ (cpu), ОЗУ (ram) и диск (hdd).
Давайте рассмотрим ситуацию: один администратор создал решение, которое требует 10% cpu, 5% ram и 10% hdd от всего вашего оборудования, а второй использовал для этого 1% cpu, 40% ram и 20% hdd. Какое из этих решений лучше? Тут все становится уже не так очевидно. Поэтому хороший администратор всегда должен уметь грамотно подобрать решение, исходя из имеющихся ресурсов.


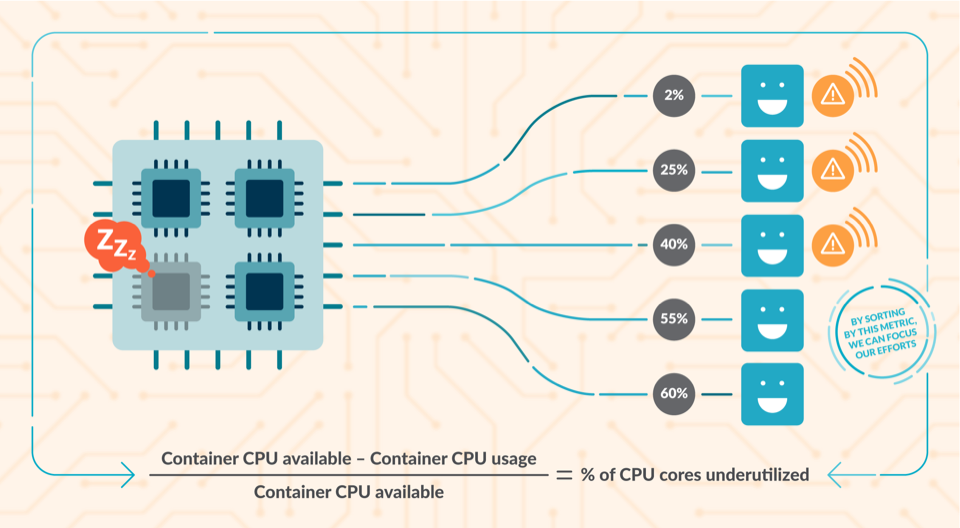








 Доброго времени суток, жителям Хабра!
Доброго времени суток, жителям Хабра!


