
 Сетевые видеокамеры постепенно вытесняют аналоговые, хоть и стоят они сейчас гораздо дороже. Сетевые обладают рядом очевидных приемуществ:
Сетевые видеокамеры постепенно вытесняют аналоговые, хоть и стоят они сейчас гораздо дороже. Сетевые обладают рядом очевидных приемуществ:- нет необходимости в отдельном регистраторе или плате захвата;
- помехоустойчивость;
- простая интеграция в существующую сеть;
- нет ограничения по расстоянию;
- наличие камер высокого разрешения;
- просмотр камеры прямо с самой камеры по http;
- наличие всевозможных настроек;
- и др.
Нас интересует способ получения изображений с таких камер, для этого надо знать а как вообще они их передают? На наше счастье камеры используют существующие стандарты, а не то, что взбредёт в голову китайскому разработчику. Подавляющее большинство камер используют один или несколько способов передачи видео, это в основном Motion JPEG по HTTP, Motion JPEG по RTSP или H264 по RTSP. Также многие камеры могут передавать звук, но он нас не интересует сейчас.
В этой статье я рассмотрю эти способы передачи изображений с сетевых камер, а также приведу пример захвата таких изображений всё на том же Python'е.
 Я являюсь рядовым линукс-пользователем и поэтому не стоит от этой статьи ожидать очень умных ходов или нестандартных программистских решений. Все по мануалам. Но раз результат достигнут, значит кому-то кроме меня это может оказаться полезным.
Я являюсь рядовым линукс-пользователем и поэтому не стоит от этой статьи ожидать очень умных ходов или нестандартных программистских решений. Все по мануалам. Но раз результат достигнут, значит кому-то кроме меня это может оказаться полезным. ). Ужасно медленно в данном случае — 2-3 секунды. Не то чтобы это было совсем фатально, но когда логин через ключ — хочется чтобы все работало мгновенно — в конце концов, у нас не 486SX.
). Ужасно медленно в данном случае — 2-3 секунды. Не то чтобы это было совсем фатально, но когда логин через ключ — хочется чтобы все работало мгновенно — в конце концов, у нас не 486SX.
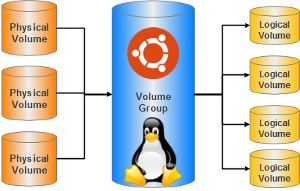 Классические разделы, на которые чаще всего разбивается жёсткий диск для установки системы и хранения данных, имею ряд существенных недостатков. Их размер очень сложно изменять, они находятся в строгой последовательности и просто взять кусочек от первого раздела и добавить к последнему не получится, если между ними есть ещё разделы. Поэтому очень часто при начальном разбиении винчестера пользователи ломают себе голову — сколько места выделить под тот или иной раздел. И почти всегда в процессе использования системы приходят к выводу, что они сделали не правильный выбор.
Классические разделы, на которые чаще всего разбивается жёсткий диск для установки системы и хранения данных, имею ряд существенных недостатков. Их размер очень сложно изменять, они находятся в строгой последовательности и просто взять кусочек от первого раздела и добавить к последнему не получится, если между ними есть ещё разделы. Поэтому очень часто при начальном разбиении винчестера пользователи ломают себе голову — сколько места выделить под тот или иной раздел. И почти всегда в процессе использования системы приходят к выводу, что они сделали не правильный выбор.

