Практически каждый день я пользуюсь почтой Gmail, но вот недавно заметил, что если сделать скриншот экрана (www.take-a-screenshot.org), то простым нажатием Ctrl + V этот скриншот можно скопировать прямо в текст письма Gmail. Это работает везде, но естественно кроме IE. Заинтересовавшись вопросом как это происходит нагуглил следующий пост на Stackoverflow. Под сильным впечатлением от возможностей HTML5 clipboardData решил сделать простенький портал, где без всяких Desktop приложений любой юзер может загрузить скриншот просто скопировав его.

User
Почему Microsoft Internet Explorer 11 — худшее, что могло случиться с нами
5 min

Я давеча написал комментарий о том, что компании Майкрософт давно пора перестать издеваться над веб-разработчиками и перейти на движок Gecko. Многие, видимо, посчитали это неуместной шуткой; тем не менее, это таки вовсе не шутка, а констатация факта. Те, кто с этим не согласен, видимо не пытались ещё разрабатывать под этот замечательный браузер.
Давайте я расскажу вам, какой это замечательный процесс.
Знай сложности алгоритмов
2 min
Translation
Эта статья рассказывает о времени выполнения и о расходе памяти большинства алгоритмов используемых в информатике. В прошлом, когда я готовился к прохождению собеседования я потратил много времени исследуя интернет для поиска информации о лучшем, среднем и худшем случае работы алгоритмов поиска и сортировки, чтобы заданный вопрос на собеседовании не поставил меня в тупик. За последние несколько лет я проходил интервью в нескольких стартапах из Силиконовой долины, а также в некоторых крупных компаниях таких как Yahoo, eBay, LinkedIn и Google и каждый раз, когда я готовился к интервью, я подумал: «Почему никто не создал хорошую шпаргалку по асимптотической сложности алгоритмов? ». Чтобы сохранить ваше время я создал такую шпаргалку. Наслаждайтесь!
Limit Theory. Новости проекта
3 min
Приветствую!
В прошлом году я поддержал на Кикстартере интересный проект Limit Theory. Это космический симулятор, но с интересной особенностью — практически все элементы игры генерируются процедурно. Описание игры выглядело многообещающе, поэтому она собрала в 3 раза больше запрашиваемой суммы.
Мне эта игра чем-то напоминает игру 1997 г. Parkan. Хроника Империи.
Вчера автор выложил ежемесячный отчет о проделанной работе, который выглядит очень впечатляюще. Посмотреть можно тут:
В прошлом году я поддержал на Кикстартере интересный проект Limit Theory. Это космический симулятор, но с интересной особенностью — практически все элементы игры генерируются процедурно. Описание игры выглядело многообещающе, поэтому она собрала в 3 раза больше запрашиваемой суммы.
Мне эта игра чем-то напоминает игру 1997 г. Parkan. Хроника Империи.
Вчера автор выложил ежемесячный отчет о проделанной работе, который выглядит очень впечатляюще. Посмотреть можно тут:
Не паникуй (перевод главы книги «Passionate Programmer» by Chad Fowler)
7 min
Translation

Почему эта книга заслуживает перевода
Хочу поделиться своим мнением с хабрасообществом о книге «Passionate Programmer», перевод одной из глав которой представлен ниже. Книга вышла в 2009 году, но среди российских программистов она не очень широко известна, тем не менее многие, кто познакомился с ней, считают её очень достойной. Чад Фаулер (автор книги) выложился очень хорошо, чтобы передать читателям свой богатый опыт (на данный момент он CTO 6Wunderkinder, имеет более 20 лет стажа разработки и в виду своего большого опыта и круга интересов он желанный гость на Ruby- и IT-конференциях). Да, уже и не помню как нашёл эту книжку, но помню, что именно предисловие от Кента Бека (идейный вдохновитель Test Driven Development и Extreme Programming) послужило причиной прочитать её.
В этой книге нет описания конкретных технологий, алгоритмов и т.п., но есть просто куча советов, касательно того, с чем порой сталкивается любой разработчик: отсутствие мотивации, выбор приоритетов, психология программирования, отношения с руководством и коллегами; по большому счёту даётся масса наставлений, о том как сделать яркую карьеру программиста. Конечно, опытные разработчики могут найти некоторые его идеи достаточно очевидными, но для тех, кто только в самом начале своей карьеры, чтение данной книги, определённо, будет хорошим вложением времени. Большой плюс, что книга читается очень легко и, если вы достаточно хорошо владеете английским, её реально прочитать всего лишь за несколько дней. Просто интересно, почему наши издательства ещё не перевели её на русский язык?
После прочтения книги я заинтересовался Чадом. Нашёл его блог в сети. Как оказалось, он начал выкладывать в нём главы из своей книги (на данный момент опубликовано 2 главы из 53). Я спросил разрешения на перевод для хабра, он ответил, что это хорошая идея, но только сначала мне надо отправить ему письмо с тем, что конкретно я хочу переводить (видимо это пожелание было как-то связано с тем издательством, где была опубликована книга). После моего ответа неделю было молчание, я отправил повторное письмо — ответа снова не было. Потом я получил от него приглашение на Wunderlist (сервис, за который он отвечает на данный момент). В общем, я посчитал, что если явного запрета не было, а эти главы уже и так находятся в свободном доступе, и он ещё не совсем про меня забыл, то делать перевод можно. В общем, если перевод сообществу окажется полезным, я продолжу переводить другие главы. В тексте возможны ошибки (делал вычитку несколько раз, но всё же вдруг), поэтому заранее прошу прощения и прошу сообщать мне обо всех проблемах через личные сообщения.
Храним сессии на клиенте, чтобы упростить масштабирование приложения (3-я из 12 статей о Node.js от команды Mozilla Identity)
4 min
Tutorial
Translation
 От переводчика: Это третья статья из цикла о Node.js от команды Mozilla Identity, которая занимается проектом Persona. Эта статья посвящена применяемому в Persona способу хранения данных сессии на клиенте.
От переводчика: Это третья статья из цикла о Node.js от команды Mozilla Identity, которая занимается проектом Persona. Эта статья посвящена применяемому в Persona способу хранения данных сессии на клиенте. Все статьи цикла:
- "Охотимся за утечками памяти в Node.js"
- "Нагружаем Node под завязку"
- "Храним сессии на клиенте, чтобы упростить масштабирование приложения"
- "Производительность фронтэнда. Часть 1 — конкатенация, компрессия, кэширование"
- "Пишем сервер, который не падает под нагрузкой"
- "Производительность фронтэнда. Часть 2 — кешируем динамический контент с помощью etagify"
- "Приручаем конфигурации веб-приложений с помощью node-convict"
- "Производительность фронтенда. Часть 3 — оптимизация шрифтов"
- "Локализация приложений Node.js. Часть 1"
- "Локализация приложений Node.js. Часть 2: инструментарий и процесс"
- "Локализация приложений Node.js. Часть 3: локализация в действии"
- "Awsbox — PaaS-инфраструктура для развёртывания приложений Node.js в облаке Amazon"
Статические веб-сайты хорошо масштабируются. Их легко кэшировать, и не нужно постоянно синхронизировать данные на нескольких серверах.
К сожалению, большинство веб-приложений должны хранить информацию о состоянии, чтобы предлагать пользователям персонализированные страницы. Если пользователи могут регистрироваться на сайте, то нам надо хранить сессии. Самый распространенный способ — установить cookie со случайным идентификатором сессии, а детали хранить на сервере.
Масштабирование сайта с хранением состояния
Если необходимо масштабировать такой сайт, есть три варианта:
- Реплицировать данные сессии между всеми серверами.
- Использовать центральное хранилище, к которому будут обращаться все серверы.
- Закрепить за каждым пользователем определённый сервер.
У всех этих подходов есть недостатки:
- Репликация ухудшает производительность и увеличивает сложность.
- Центральное хранилище ограничивает возможность масштабирования и приводит к дополнительным задержкам.
- Привязка пользователей к конкретным серверам приводит к проблемам, когда сервер отключается.
Тем не менее, поразмыслив немного, можно придумать и четвёртый способ: хранить все данные сессии на клиенте.
Методики и принципы экстремального программирования
10 min
Recovery Mode
Экстрема́льное программи́рование (англ. Extreme Programming, XP) — одна из гибких методологий разработки программного обеспечения. Авторы методологии — Кент Бек, Уорд Каннингем, Мартин Фаулер и другие.
Наш мир слишком изменчив и непредсказуем, чтобы полагаться на постоянство ситуации. То же происходит и при разработке программного обеспечения: о редкой системе можно сказать, что ее окончательный вид был заранее известен в деталях еще в самом начале разработки. Обычно у заказчика аппетит приходит во время еды: ему постоянно хочется что-то поменять, что-то улучшить, а что-то вообще выбросить из системы. Это и есть изменчивость требований, которую все так боятся. К счастью, человеку дано умение прогнозировать возможные варианты и, таким образом, держать ситуацию под контролем.
В экстремальном программировании планирование — неотъемлемая часть разработки и то, что планы могут поменяться, учитывается с самого начала. Той точкой опоры, методикой, которая позволяет прогнозировать ситуацию и безболезненно мириться с изменениями, является игра в планирование. В ходе такой игры можно быстро собрать известные требования к системе, оценить и запланировать их разработку в соответствии с приоритетностью.
Как и любая другая игра, планирование имеет своих участников и свою цель. Ключевой фигурой является, конечно же, заказчик. Именно он сообщает о необходимости той или иной функциональности. Программисты же дают ориентировочную оценку каждой функциональности. Прелесть игры в планирование заключается в единстве цели и солидарности разработчика и заказчика: в случае победы побеждают все, в случае поражения все проигрывают. Но при этом каждый участник идет к победе своей дорогой: заказчик выбирает наиболее важные задачи в соответствии с бюджетом, а программист оценивает задачи в соответствии со своими возможностями по их реализации.
Экстремальное программирование предполагает, что разработчики в состоянии сами решить, за какой промежуток времени они справятся со своими задачами и кто из них охотнее бы решил одну задачу, а кто другую.
В идеальной ситуации игра в планирование с привлечением заказчика и программиста должна проводиться каждые 3-6 недель, до начала следующей итерации разработки. Это позволяет довольно просто внести коррективы в соответствии с успехами и неудачами предыдущей итерации.
Игра в планирование
Наш мир слишком изменчив и непредсказуем, чтобы полагаться на постоянство ситуации. То же происходит и при разработке программного обеспечения: о редкой системе можно сказать, что ее окончательный вид был заранее известен в деталях еще в самом начале разработки. Обычно у заказчика аппетит приходит во время еды: ему постоянно хочется что-то поменять, что-то улучшить, а что-то вообще выбросить из системы. Это и есть изменчивость требований, которую все так боятся. К счастью, человеку дано умение прогнозировать возможные варианты и, таким образом, держать ситуацию под контролем.
В экстремальном программировании планирование — неотъемлемая часть разработки и то, что планы могут поменяться, учитывается с самого начала. Той точкой опоры, методикой, которая позволяет прогнозировать ситуацию и безболезненно мириться с изменениями, является игра в планирование. В ходе такой игры можно быстро собрать известные требования к системе, оценить и запланировать их разработку в соответствии с приоритетностью.
Как и любая другая игра, планирование имеет своих участников и свою цель. Ключевой фигурой является, конечно же, заказчик. Именно он сообщает о необходимости той или иной функциональности. Программисты же дают ориентировочную оценку каждой функциональности. Прелесть игры в планирование заключается в единстве цели и солидарности разработчика и заказчика: в случае победы побеждают все, в случае поражения все проигрывают. Но при этом каждый участник идет к победе своей дорогой: заказчик выбирает наиболее важные задачи в соответствии с бюджетом, а программист оценивает задачи в соответствии со своими возможностями по их реализации.
Экстремальное программирование предполагает, что разработчики в состоянии сами решить, за какой промежуток времени они справятся со своими задачами и кто из них охотнее бы решил одну задачу, а кто другую.
В идеальной ситуации игра в планирование с привлечением заказчика и программиста должна проводиться каждые 3-6 недель, до начала следующей итерации разработки. Это позволяет довольно просто внести коррективы в соответствии с успехами и неудачами предыдущей итерации.
Выступление Павла Дурова на конференции GMIC в Сан-Франциско — первое публичное выступление основателя VK и Telegram в Кремниевой Долине
3 min

22 октября на конференции GMIC состоялось первое публичное появление Павла Дурова, основателя ВКонтакте и Telegram, в Сан-Франциско, что в районе Кремниевой Долины. Задавала вопросы Павлу Alexia Tsotsis, редактор TechCrunch — одного из самых популярных ресурсов про технологии и стартапы.
Вопреки расхожему мнению, Павел считает примером для подражания совсем не Марка Закерберга, а Эдварда Сноудена, который «проявил смелость и пожертвовал большой частью своей жизни ради того, чтобы люди узнали правду о том, что за ними шпионят».
Классический подход к управлению зависимостями в сравнении с RequireJS
5 min
Hello World,
Helios Kernel — это библиотека для управления зависимостями между javascript-модуями, реализующая «классический» подход, часто встречаемый в других языках и средах — с помощью функции include().
Такой способ отличается от других подходов своей простотой: зависимости перечисляются в начале модуля по точному пути к файлу, тело модуля содержит код, который выполняется после загрузки зависимостей модуля.
Helios Kernel придерживается принципа KISS, поэтому здесь отсутствуют некоторые возможности, которые сегодня принято ожидать от библиотеки по управлению зависимостями. При использовании Helios Kernel не нужно описывать конфиг с правилами поиска путей для разных модулей, или экспортировать библиотечные функци через специальный объект. Но эта библиотека была написана как раз потому, что хотелось просто подключать нужные модули и писать код, не натыкаясь на крутые возможности при указании каждой новой зависимости.
Helios Kernel поддерживает динамическую загрузку (и выгрузку) зависимостей в рантайме, а сама библиотека и формат модулей являются совместимыми между nodejs и броузерной средой — то есть модули можно использовать без изменений или трансляции.
В этой статье классический подход реализованный в Helios Kernel сравнивается с управлением зависимостями с помощью RequireJS и показывается, каким образом подход Helios Kernel позволяет избежать некоторых сложностей.
Helios Kernel — это библиотека для управления зависимостями между javascript-модуями, реализующая «классический» подход, часто встречаемый в других языках и средах — с помощью функции include().
Такой способ отличается от других подходов своей простотой: зависимости перечисляются в начале модуля по точному пути к файлу, тело модуля содержит код, который выполняется после загрузки зависимостей модуля.
Helios Kernel придерживается принципа KISS, поэтому здесь отсутствуют некоторые возможности, которые сегодня принято ожидать от библиотеки по управлению зависимостями. При использовании Helios Kernel не нужно описывать конфиг с правилами поиска путей для разных модулей, или экспортировать библиотечные функци через специальный объект. Но эта библиотека была написана как раз потому, что хотелось просто подключать нужные модули и писать код, не натыкаясь на крутые возможности при указании каждой новой зависимости.
Helios Kernel поддерживает динамическую загрузку (и выгрузку) зависимостей в рантайме, а сама библиотека и формат модулей являются совместимыми между nodejs и броузерной средой — то есть модули можно использовать без изменений или трансляции.
В этой статье классический подход реализованный в Helios Kernel сравнивается с управлением зависимостями с помощью RequireJS и показывается, каким образом подход Helios Kernel позволяет избежать некоторых сложностей.
Обзор ECMAScript 6, следующей версии JavaScript
6 min
Для начала, ликбез и несколько фактов:
Итак, что же нас ждет в новой версии JavaScript?
- ECMAScript — это официальный стандарт языка JavaScript (Слово JavaScript не могло быть использовано, потому что слово Java являлось торговой маркой компании Sun) Т.е. JavaScript — это имплементация стандарта ECMAScript.
- TC39 — комитет, развивающий стандарт ECMAScript и принимающий решения по включению фич в него.
- ECMAScript стандартов много. Самый популярный из них — ECMA-262.
- ECMAScript 5 — последняя редакция стандарта ECMA-262 (утвержден в 2009 году).
- Предыдущие версии стандарта ECMA-262 были (совсем старые не упоминаю):
- ECMAScript 3 — поддерживается большинством браузеров (утвержден в 1999 году).
- ECMAScript 4 — не принят в виду слишком радикальных изменений в стандарте. Позднее в июле 2008 году в урезанном варианте (но все же намного богаче, чем ECMAScript 3) вылился в новый проект ECMAScript Harmony.
- ECMAScript 6 (кодовое имя ECMAScript.next) должен утвердиться до конца 2013 года.
Итак, что же нас ждет в новой версии JavaScript?
Проектируем вместе защищенное приложение для обмена сообщениями
2 min
Большинству из нас известно, что «защищённые» приложения для обмена сообщениями, которые мы используем каждый день (SMS, WhatsApp, Viber, Skype и тд) на самом деле изобилуют возможностями перехвата переписки. Они используют промежуточные сервера для передачи сообщений и сохраняют копию каждого сообщения. Автоматически копия каждого сообщения дублируется на государственных серверах и оттуда уже никогда не удаляется. Также автоматически логируется информация о том, какой IP в какое время с кем общался.
Пару месяцев я задумался о том, как реализовать по-настоящему безопасное приложение для обмена сообщениями, которые невозможно перехватить никаким способом.
Пару месяцев я задумался о том, как реализовать по-настоящему безопасное приложение для обмена сообщениями, которые невозможно перехватить никаким способом.
Разработка проекта AppJS прекращена, в дальнейшем пользуйтеся node-webkit
2 min
 Чуть больше года назад (1 октября 2012 года) я выложил на Хабрахабре блогозапись «
Чуть больше года назад (1 октября 2012 года) я выложил на Хабрахабре блогозапись «На следующий же день (2 октября 2012 года) во блогозаписи «
![[скриншот Twitter]](https://habrastorage.org/getpro/habr/post_images/b7d/a1e/dd0/b7da1edd02145a22fe534dd9903e8e42.png)
Motorola Ara — проект по созданию модульных смартфонов
1 min

Компания Motorola заявила о старте проекта Ara, в рамках которого планируется разработать модульные смартфоны, состоящие из заменяемых элементов. Владея таким устройством, пользователь сможет при желании заменить, например, экран, процессор, фотомодуль и т. д.
Motorola поддерживает Phonebloks и создает свой модульный смартфон Project Ara
1 min
В сентябре мы писали про проект Phonebloks – модульный смартфон, который можно будет собирать из разных блоков. Тогда в комментариях многие назвали это утопией. Сегодня о проекте Ara – новой, открытой железной платформе для создания модульных смартфонов, объявила Motorola.

Работаем с API вконтакте из расширения для Google Chrome
6 min
Tutorial
 В этом топике я постараюсь рассказать о работе с API вконтакте из расширения для Google Chrome.
В этом топике я постараюсь рассказать о работе с API вконтакте из расширения для Google Chrome. По сути, самая сложная часть это получение токена для доступа к API вконтакте, но обо всём по порядку. Для пущей наглядности я приведу пример минимально полезного расширения (что бы оно хоть что-то полезное делало, а вообще оно было сделано для удобного рехостинга гифок). И так расширение будет простое, но рабочее.
Приложения для Firefox OS запустятся на Android, Windows, Mac OS X и Linux
1 min
Инженеры Firefox OS в своём блоге сообщили о том, что приложения для их операционной системы, выполненные по технологии Open Web Apps (другими словами, просто на HTML+JS+CSS) станут, условно говоря, «кросс-платформенными» и будут работать на целом ряде сторонних ОС без изменений исходного кода («like a native apps»). Правда, приложение всё-таки должно уметь приспосабливаться к размерам экрана и аппаратной части устройства.
На демо-видео показан процесс запуска некоторого приложения Short Clock, которое, как можно понять, не требует никаких пользовательских привилегий. Видно, что на Android, Windows, Mac OS и Linux происходит примерно следующее: приложение устанавливается из Firefox Marketplace из браузера в соответствующей операционной системе (при этом оно автоматически адаптируется к ней — происходит «repackage») и запускается «как нативное приложение». При этом подчёркивается, что «изменений исходного кода — ноль».
Примечательно то, что JavaScript в OWA-приложении может работать не только в пределах своего HTML, а и обращаться к существующим hardware API на каждой из перечисленных платформ. На видео видно, как в Android устанавливается приложение, требующее ряда привилегий — доступа к GPS и Vibration API, к примеру.
На демо-видео показан процесс запуска некоторого приложения Short Clock, которое, как можно понять, не требует никаких пользовательских привилегий. Видно, что на Android, Windows, Mac OS и Linux происходит примерно следующее: приложение устанавливается из Firefox Marketplace из браузера в соответствующей операционной системе (при этом оно автоматически адаптируется к ней — происходит «repackage») и запускается «как нативное приложение». При этом подчёркивается, что «изменений исходного кода — ноль».
Примечательно то, что JavaScript в OWA-приложении может работать не только в пределах своего HTML, а и обращаться к существующим hardware API на каждой из перечисленных платформ. На видео видно, как в Android устанавливается приложение, требующее ряда привилегий — доступа к GPS и Vibration API, к примеру.
Lifehack для Same-Origin-Policy; Google Chrome и другие
5 min
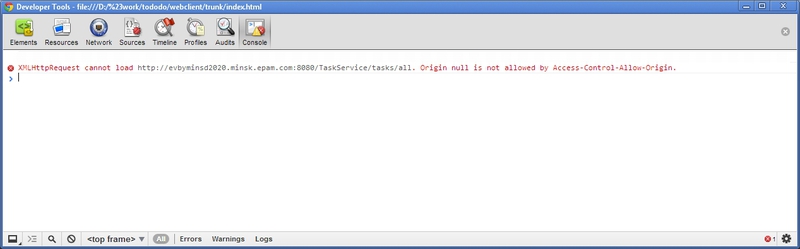
Задача:
— есть REST-сервер
— есть одностраничное приложение (HTML/CSS/Javascript) которое берет данные с сервера через XMLHttpRequest
— нужно разработать новую фичу
Делаем «mindmap» на Javascript с локальным хранением в базе данных браузера
25 min

Это небольшой учебный пример редактора карты памяти. За счёт очень подробных комментариев и простого кода, понять его не составит проблем. Статья предназначена для знающих и изучающих Javascript.
Я опишу особенности создания редактора карты памяти, который использует базу данных браузера. Причём, это будет не LocalStorage, который не может превышать 5 мегабайт. Объём данных сможет превысить 100-200 мегабайт, так как используется IndexedDB или webSQL, смотря что доступно в конкретном браузере.
Исходники выложены в открытый доступ на Github.
Мы уложимся в 520 строк кода, при этом в нашей карте можно будет перетаскивать узлы между собой, удалять, переименовывать и создавать новые. А также можно будет назначать одну из 120 иконок через контекстное меню.
Секрет минимализма в том, что мы будем использовать проверенные в бою плагины:
- Ydn.db — хранение информации в базе данных браузера с автоматическим выбором лучшего метода и единым API
- jQuery context menu — контекстное меню, которое можно наполнять динамически при помощи Javascript
- jsPlumb — расширение позволяющее рисовать линии между HTML элементами
- jQuery UI — Drag&drop — перетаскивание элементов между собой
PS: Также мы научимся создавать «синглтон», облегчать себе асинхронное программирование при помощи jQuery и встроенного объекта $.Deferred(), а также при помощи плагина LiveReload, сохраним краску на клавише F5 при изменении свойств CSS и кода в HTML и Javascript.
Application Cache API — новые возможности и проблемы
15 min
 Постепенно концепция стандарта HTML5 становиться реальностью. Браузеры начинают поддерживать новые возможности, которых так не хватало. Но с новыми возможностями появляются и новые проблемы.
Постепенно концепция стандарта HTML5 становиться реальностью. Браузеры начинают поддерживать новые возможности, которых так не хватало. Но с новыми возможностями появляются и новые проблемы. В данной статье рассматривается Application Cache API — совокупность функций, обеспечивающих продвинутое кэширование ресурсов web-приложения, и с помощью которых можно просматривать загруженные ранее сайты без подключения к сети Интернет. Особое внимание я уделил практическому использованию и проблемам Application Cache.
Базы знаний. Часть 1 — введение
5 min
Одной из причин слабого использования Linked Data-баз знаний в обычных, ненаучных приложениях является то, что мы не привыкли придумывать юзкейсы, видя перед собой только данные. Трудно спорить с тем, что сейчас в России производится крайне мало взаимосвязанных данных. Однако это не значит, что разработчик, создающий приложение для русскоязычной аудитории совсем уж отрезан от мира семантического веба: кое-что всё-таки у нас есть.
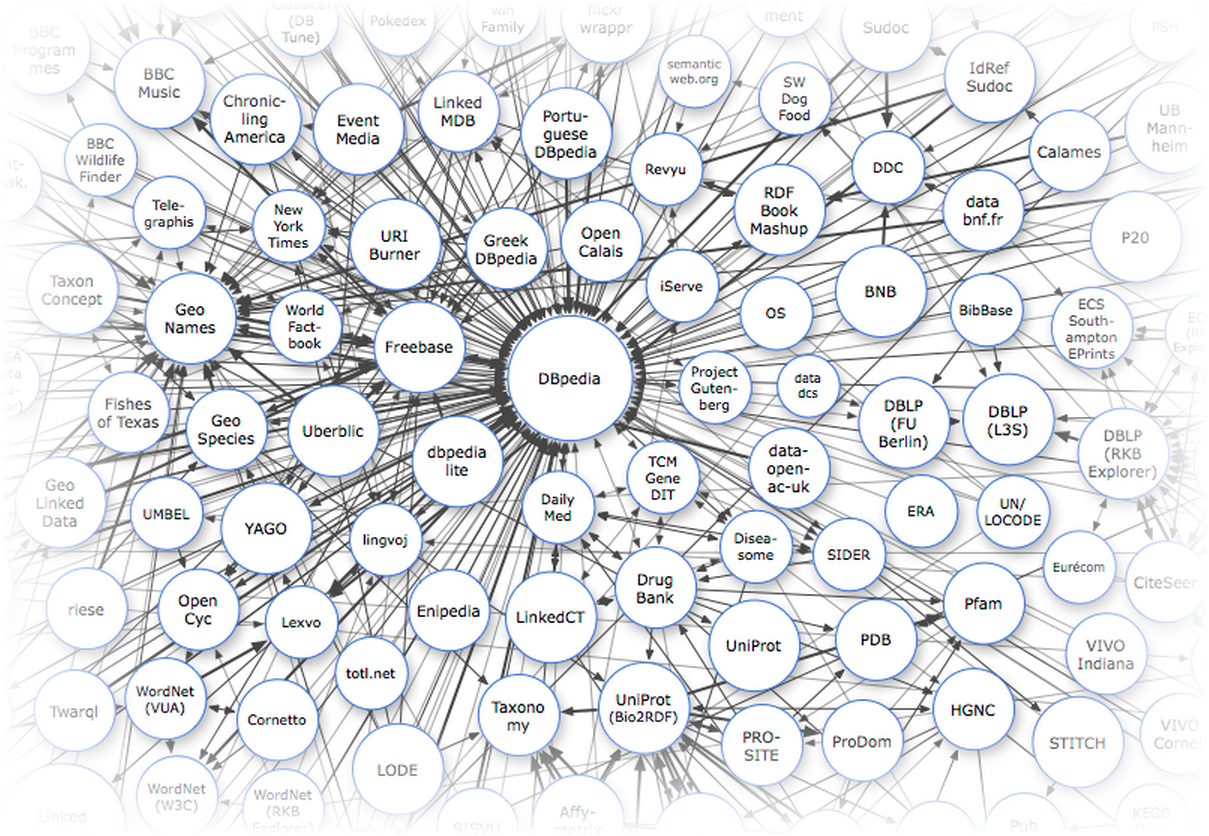
Основными источниками данных для нас являются международные базы знаний, включающие русскоязычный контент: DBpedia, Freebase и Wikidata. В первую очередь это справочные, лингвистические и энциклопедические данные. Каждый раз когда вам в голову приходит мысль распарсить кусочек википедии или викисловаря — ущипните себя как следует и вспомните о том, что всё, что хранится в категориях, инфобоксах или таблицах, уже распарсено и доступно через API с помощью SPARQL или MQL-интерфейса.
Я попробую привести несколько примеров полезных энциклопедических данных, которые вы не найдете нигде, кроме Linked Data.
Эта статья — первая из цикла Базы знаний. Следите за обновлениями.
Основными источниками данных для нас являются международные базы знаний, включающие русскоязычный контент: DBpedia, Freebase и Wikidata. В первую очередь это справочные, лингвистические и энциклопедические данные. Каждый раз когда вам в голову приходит мысль распарсить кусочек википедии или викисловаря — ущипните себя как следует и вспомните о том, что всё, что хранится в категориях, инфобоксах или таблицах, уже распарсено и доступно через API с помощью SPARQL или MQL-интерфейса.
Я попробую привести несколько примеров полезных энциклопедических данных, которые вы не найдете нигде, кроме Linked Data.
Эта статья — первая из цикла Базы знаний. Следите за обновлениями.
- Часть 1 — Введение
- Часть 2 — Freebase: делаем запросы к Google Knowledge Graph
- Часть 3 — Dbpedia — ядро мира Linked Data
- Часть 4 — Wikidata — семантическая википедия