Только что мы представили новую версию поиска Y1. Она включает в себя комплекс технологических изменений. В том числе улучшения в ранжировании за счёт более глубокого применения трансформеров. Подробнее об этом направлении мой коллега Саша Готманов уже рассказывал в нашем блоге. В новой версии модель стала мощнее: количество параметров возросло в 4 раза. Но сегодня мы поговорим о других изменениях.
Когда человек вводит запрос в поисковик, он ищет информацию или способ решения своей задачи. Наша глобальная цель — помогать находить такие ответы, причём сразу в наиболее ёмком виде, чтобы сэкономить людям время. Этот тренд на ускорение решения пользовательских задач особенно заметен в последние годы. К примеру, теперь многие пользователи задают свои вопросы не текстом в поиске, а голосовому помощнику. И тут нам на помощь пришли огромные генеративные нейросети, которые способны перерабатывать, суммаризировать и представлять в ёмком виде тексты на естественном языке. Пожалуй, самой неожиданной особенностью таких сетей стала возможность быстро обучаться на всё новые задачи без необходимости собирать большие датасеты.
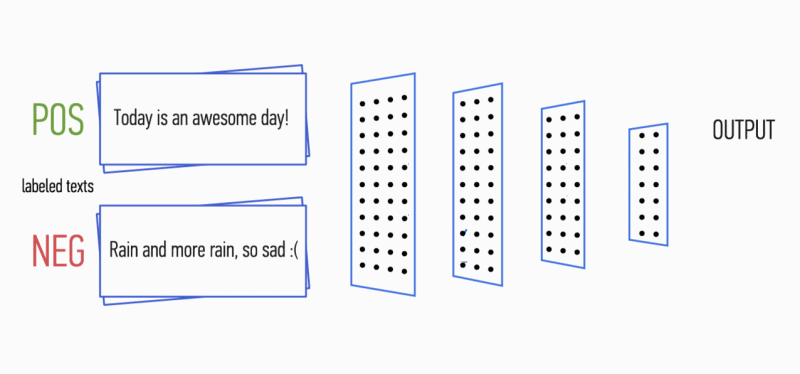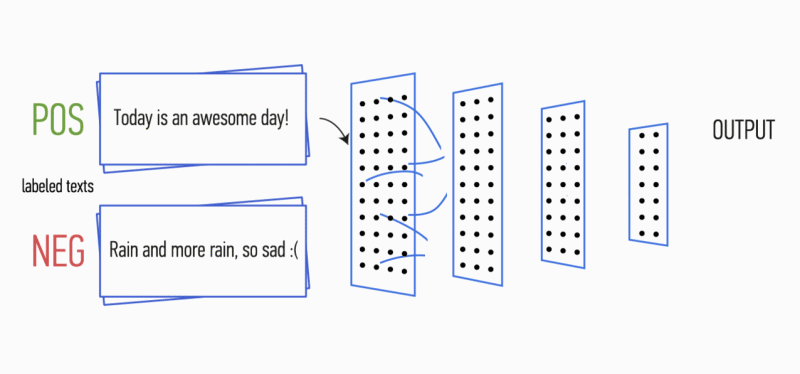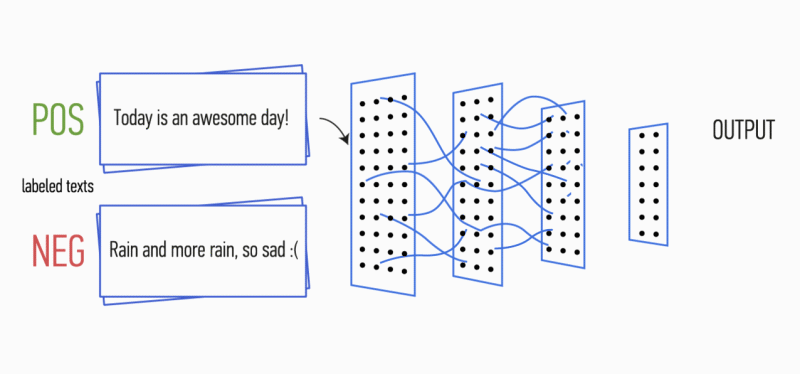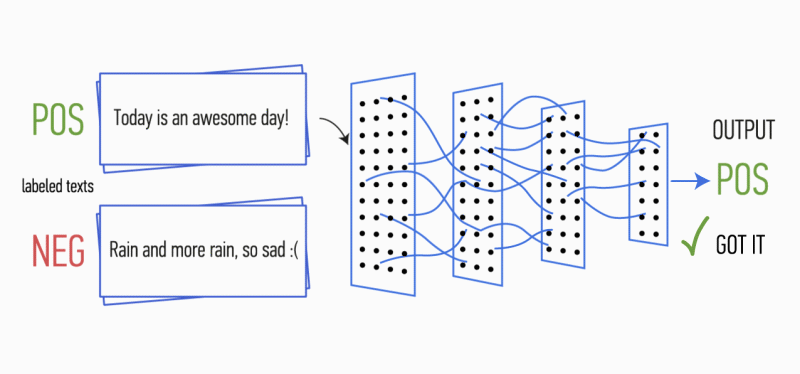
Сегодня мы поделимся опытом создания и внедрения технологии YaLM (Yet another Language Model), которая теперь готовит ответы для Поиска и Алисы. В этом мне помогут её создатели — Алексей Петров petrovlesha и Николай Зинов nzinov. Эта история основана на их докладе с Data Fest 2021 и описывает опыт внедрения модели в реальные продукты, поэтому будет полезна и другим специалистам в области NLP. Передаю слово Алексею и Николаю.