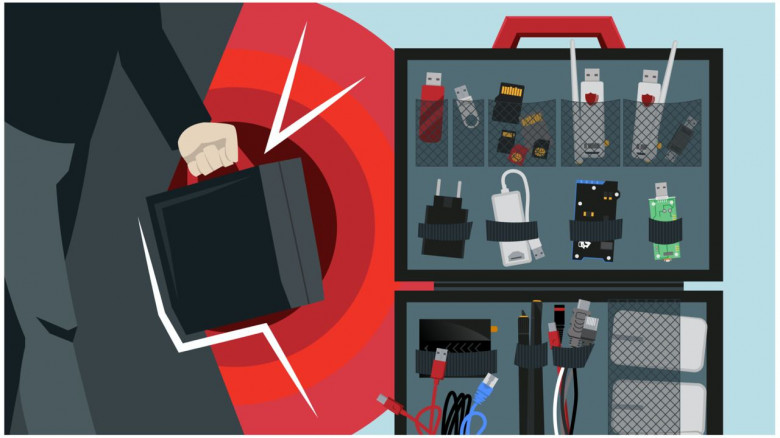
Сегодня расскажем о составе нашего типового полевого набора, который пентестеры берут с собой, выезжая для проведения анализа беспроводных сетей или проектов в формате Red Team.

Вечный студент
Сегодня расскажем о составе нашего типового полевого набора, который пентестеры берут с собой, выезжая для проведения анализа беспроводных сетей или проектов в формате Red Team.

Это - отдельное руководство, описывающее ещё один способ получить личный
прокси-сервер shadowsocks бесплатно и служащее продолжением к моей предыдущей статье. В этот раз мы воспользуемся сервисом Replit.
В этот раз всё будет намного проще: регистрация, импорт, запуск. Три шага.

Цель статьи — описать алгоритм действий поиска открытого API сайта.
Целевая аудитория статьи — программисты, которым интересен парсинг и анализ уязвимостей сайтов.
В статье рассмотрим пример поиска API сайта edadeal.ru, познакомимся с протоколом google protobuf и сравним скорость различных подходов парсинга
Привет, Хабр! Представляю вашему вниманию перевод статьи "Everything you need to know about Node.js" автора Jorge Ramón.

В наши дни платформа Node.js является одной из самых популярных платформ для построения эффективных и масштабируемых REST API's. Она так же подходит для построения гибридных мобильных приложений, десктопных программ и даже для IoT.
Я работаю с платформой Node.js более 6 лет и я на самом деле люблю её. Этот пост главным образом пытается быть путеводителем по тому, как Node.js работает на самом деле.


Обнаружение сонливости водителя продиктовано потребностью безопасности – разработка приложения для обнаружения в режиме реального времени позволит избежать серьезных происшествий в тот момент, когда водитель переутомлен. По разным оценкам, около 20% всех уличных происшествий связаны с переутомлением, а на некоторых оживленных улицах – до 50%. Таким образом, совершенствование технологий распознавания и предотвращения сна за рулем может стать серьезным вызовом в области улучшения систем предотвращения аварий. При обнаружении сонливости, необходимо в тот же момент предупредить водителя о возможных неприятностях. Подобное обнаружение достигается при помощи детектирования состояния глаз водителя.
Использование библиотек языка программирования Python позволяет выполнить программную реализацию системы обнаружения сонливости водителя, которое позволяет определять, как долго у конкретного человека (водителя) были закрыты глаза. Если глаза были закрыты в течение определенного времени, то следует предположить, что водитель начинает засыпать, и включить звуковой сигнал, чтобы разбудить водителя и привлечь его внимание.
Для успешного распознавания необходимо расположить камеру в машине, чтобы можно было легко определить лицо водителя в тот момент, когда он находится за рулем, и применить локализацию лицевых признаков для наблюдения за глазами.
Классификация состояния глаз осуществляется при помощи методов компьютерного зрения. Чтобы начать реализацию, необходимо создать новый *.py-файл, открыть его в текстовом редакторе или среде разработки для языка Python (например, в IDLE) и выполнить подключение необходимых библиотек. Исходный код функции воспроизведения приведен в листинге 1.
Поднимаем свой веб-сервер в домашней сети видимый из вне для pet проектов на старом ноутбуке с Ubuntu Server.

Пользователи iFunny ежедневно загружают в приложение около 100 000 единиц контента, среди которого не только мемы, но и расизм, насилие, порнография и другие недопустимые вещи.
Раньше мы отсматривали это вручную, а сейчас разрабатываем автоматическую модерацию на основе свёрточных нейросетей. Систему уже обучили на разделение контента по трём классам: она распознает, что пропустить в ленты пользователей, что удалить, а что скрыть из общей ленты. Чтобы сделать алгоритмы точнее, решили добавить конкретизацию причины удаления контента, у которого до этого не было подобной разметки.
Как мы это в итоге сделали — расскажу под катом на наглядном примере. Статья рассчитана на тех, кто знаком с Python (при этом необязательно разбираться в Data Science и Machine Learning).

К 2025 году искусственный интеллект заменит 85 миллионов рабочих мест, в том числе — творческих. Нейронные сети уже умеют рисовать картины, писать сценарии и создавать музыку, а их произведения продают на аукционах за огромные деньги.
В этой статье разберёмся, на что ещё способны нейросети, как у них получается так хорошо подражать людям и где они смогут заменить человека. И обязательно попробуем сгенерировать что-нибудь сами.
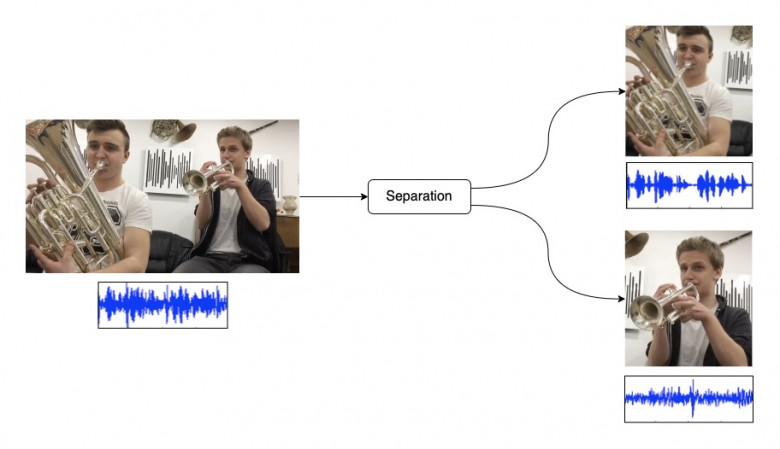
Традиционно популярными и активно исследуемыми областями в Deep Learning являются задачи обработки изображений или текстов. Тем не менее, задачи, связанные с обработкой звуков и аудиодорожек, полезны и могут найти практические приложения во многих областях. В данной статье я расскажу о решении задачи Sound Separation, но с одним отличием — в качестве входных данных используются видеозаписи. Обычно для задач разделения звука используют аудио данные с готовой разметкой (разделением на отдельные источники). В подходе, изначально предложенном в статье Sound of Pixels используются видеозаписи, а также не требуется явная разметка для источников звука.
 Задача сохранения настроек встречается в подавляющем большинстве современных устройств. Реже, но тоже очень часто, требуется хранение лог-файлов. Если речь идет о большом устройстве построенном на Линукс и содержащей как минимум SD карту, то с этими задачами не возникает проблем. Но если все устройство представляет из себя микроконтроллер, то возникает вопрос, где и в каком виде хранить подобные данные. В этом случае, обычно для настроек предлагают использовать сырые данные размещенные во внешнем eeprom. Но такой подход гораздо менее удобен чем вариант с файловой системой пусть даже с сильно ограниченными свойствами. Кроме того он плохо подходит для задач логирования. В данной статье мы расскажем как можно организовать удобное хранение файлов настроек и лог-файлов во внутренней флеш памяти микроконтроллера.
Задача сохранения настроек встречается в подавляющем большинстве современных устройств. Реже, но тоже очень часто, требуется хранение лог-файлов. Если речь идет о большом устройстве построенном на Линукс и содержащей как минимум SD карту, то с этими задачами не возникает проблем. Но если все устройство представляет из себя микроконтроллер, то возникает вопрос, где и в каком виде хранить подобные данные. В этом случае, обычно для настроек предлагают использовать сырые данные размещенные во внешнем eeprom. Но такой подход гораздо менее удобен чем вариант с файловой системой пусть даже с сильно ограниченными свойствами. Кроме того он плохо подходит для задач логирования. В данной статье мы расскажем как можно организовать удобное хранение файлов настроек и лог-файлов во внутренней флеш памяти микроконтроллера.

Привет Хабр!
Сегодня я сниму костюм аниматора и вместо развлечений расскажу вам немного за питон.
Я довольно посредственный программист, но иногда мне удаётся усыпить что-нибудь бдительность, и меня считают сеньором. И вот как-то так получилось, что я стал делать много код ревью. Просматривая файл за файлом, я вдруг увидел, что люди и проекты меняются, а вот моменты, к которым я, зануда такая, придираюсь, остаются теми же. Поэтому я решил собрать самые частые паттерны в эту сумбурную статью и надеюсь, что они помогут вам писать более чистый и эффективный питон-код.
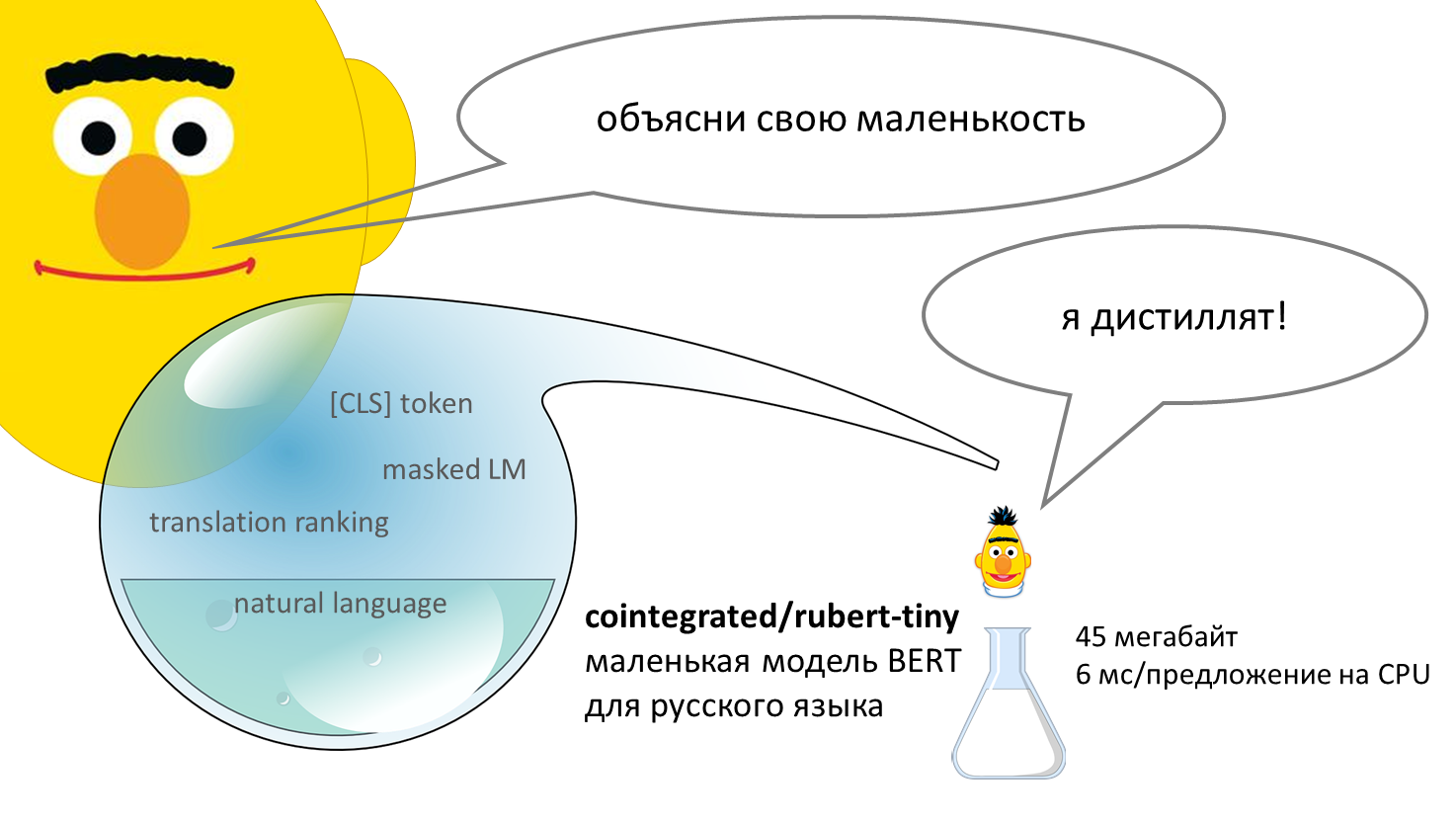
BERT – нейросеть, способная неплохо понимать смысл текстов на человеческом языке. Впервые появившись в 2018 году, эта модель совершила переворот в компьютерной лингвистике. Базовая версия модели долго предобучается, читая миллионы текстов и постепенно осваивая язык, а потом её можно дообучить на собственной прикладной задаче, например, классификации комментариев или выделении в тексте имён, названий и адресов. Стандартная версия BERT довольно толстая: весит больше 600 мегабайт, обрабатывает предложение около 120 миллисекунд (на CPU). В этом посте я предлагаю уменьшенную версию BERT для русского языка – 45 мегабайт, 6 миллисекунд на предложение. Она была получена в результате дистилляции нескольких больших моделей. Уже есть tinybert для английского от Хуавея, есть моя уменьшалка FastText'а, а вот маленький (англо-)русский BERT, кажется, появился впервые. Но насколько он хорош?
В предыдущих сериях постов для начинающих из ремикса книги Генри Гарнера «Clojure для исследования данных» (Clojure for Data Science) на языке Python мы рассмотрели методы описания выборок с точки зрения сводных статистик и методов статистического вывода из них параметров популяции. Такой анализ сообщает нам нечто о популяции в целом и о выборке в частности, но он не позволяет нам делать очень точные утверждения об их отдельных элементах. Это связано с тем, что в результате сведения данных всего к двум статистикам - среднему значению и стандартному отклонению - теряется огромный объем информации.

А вы знаете, что многофункциональный модуль Simulation может решать задачи термического исследования? Он не только позволяет увидеть, как температура распространяется по деталям, но и дает возможность узнать, за какое время деталь нагревается. Обо всем этом и многом другом – в нашей статье.
А Вы знали, что физика — это наука об алгоритмах? Нет? Тогда в стране чудес с соответствующим названием нас ждёт вдвойне неожиданное знакомство с физическим зазеркальем Алгоритма. По дороге мы выберемся из лабиринта "мыслей" физика. И всё это с помощью наших знакомых из предыдущей статьи: Алисы и близнецов Переноса и Трансляции. Под катом опять много слов и несколько детских картинок...


В предыдущей серии постов для начинающих (первый пост тут) из ремикса книги Генри Гарнера «Clojure для исследования данных» (Clojure for Data Science) на языке Python было представлено несколько численных и визуальных подходов, чтобы понять, что из себя представляет нормальное распределение. Мы обсудили несколько описательных статистик, таких как среднее значение и стандартное отклонение, и то, как они могут использоваться для краткого резюмирования больших объемов данных.
Набор данных обычно представляет собой выборку из некой более крупной популяции, или генеральной совокупности. Иногда эта популяция слишком большая, чтобы быть измеренной полностью. Иногда она неизмерима по своей природе, потому что она бесконечна по размеру либо потому что к ней нельзя получить непосредственный доступ. В любом случае мы вынуждены делать вывод, исходя из данных, которыми мы располагаем.
В этой серии из 4-х постов мы рассмотрим статистический вывод: каким образом можно выйти за пределы простого описания выборок и вместо этого описать популяцию, из которой они были отобраны. Мы подробно рассмотрим степени нашей уверенности в выводах, которые мы делаем из выборочных данных. Мы раскроем суть робастного подхода к решению задач в области исследования данных, каким является проверка статистических гипотез, которая как раз и привносит научность в исcледование данных.
В конце заключительного поста можно будет проголосовать за или против размещения следующей серии постов. А пока же…