
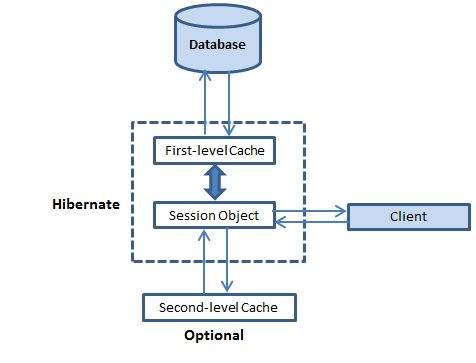
Оригинальная статья является размышления на тему почему документация в мире микросервисов критично необходима и как ее можно создавать и публиковать используя swagger. Пошаговой инструкцией по настройке она точно не является.

User
Оригинальная статья является размышления на тему почему документация в мире микросервисов критично необходима и как ее можно создавать и публиковать используя swagger. Пошаговой инструкцией по настройке она точно не является.








 Exasol — это современная высокопроизводительная проприетарная СУБД для аналитики. Ее прямые конкуренты: HP Vertica, Teradata, Redshift, BigQuery. Они широко освещены в Рунете и на Хабре, в то время как про Exasol на русском языке нет почти ни слова. Нам бы хотелось исправить эту ситуацию и поделиться опытом практического использования СУБД в компании Badoo.
Exasol — это современная высокопроизводительная проприетарная СУБД для аналитики. Ее прямые конкуренты: HP Vertica, Teradata, Redshift, BigQuery. Они широко освещены в Рунете и на Хабре, в то время как про Exasol на русском языке нет почти ни слова. Нам бы хотелось исправить эту ситуацию и поделиться опытом практического использования СУБД в компании Badoo.




— Мы забрели в зону с сильным магическим индексом-объяснил он, — Когда-то давно здесь образовалось мощное магическое поле.
– Вот именно, — ответил проходящий мимо куст.
Терри Пратчетт, Цвет волшебства


 В момент создания, 4 года назад, наша компания понимала свое предназначение: мы упрощаем малому бизнесу использование SaaS. И хотя изначальная бизнес-модель была выбрана неверно, все это время мы находились в перманентном поиске собственной ниши. Мы застали всплеск облачных сервисов в России, видели спад и видим начинающийся второй подъем. Специфика нашего бизнеса в объединении SaaS-продуктов. И мы видим, как наши передовые SaaS-компании вставляют палки в колеса собственному рынку.
В момент создания, 4 года назад, наша компания понимала свое предназначение: мы упрощаем малому бизнесу использование SaaS. И хотя изначальная бизнес-модель была выбрана неверно, все это время мы находились в перманентном поиске собственной ниши. Мы застали всплеск облачных сервисов в России, видели спад и видим начинающийся второй подъем. Специфика нашего бизнеса в объединении SaaS-продуктов. И мы видим, как наши передовые SaaS-компании вставляют палки в колеса собственному рынку.