Большинство разработчиков с разговорами о принципах архитектурного дизайна, да и принципах чистой архитектуры вообще, обычно сталкивается разве что на очередном собеседовании. А зря. Мне приходилось работать с командами, которые ничего не слышали о S.O.L.I.D, и команды эти пролетали по срокам разработки на многие месяцы. Другие же команды, которые следовали принципам дизайна и тратили очень много времени на буквоедство, соблюдение принципов чистой архитектуры, код-ревью и написание тестов, в результате значительно экономили время Заказчика, писали лёгкий, чистый, удобочитаемый код, и, самое главное, получали от этого кайф.
Сегодня мы поговорим о том, как следовать принципам S.O.L.I.D и получать от этого удовольствие.

Что такое S.O.L.I.D? Погуглите — и получите 5 принципов, которые в 90% случаев описываются очень скупо. Скупость эта потом выливается в непонимание и долгие споры. Я же предлагаю вернуться к одному из признанных источников и хотя бы на время закрыть этот вопрос.
Источником принципов S.O.L.I.D принято считать книгу Роберта Мартина «Чистая архитектура». Если у Вас есть время прочесть книгу, лучше отложите эту статью и почитайте книгу. Если времени у Вас нет, а завтра собес — велком.





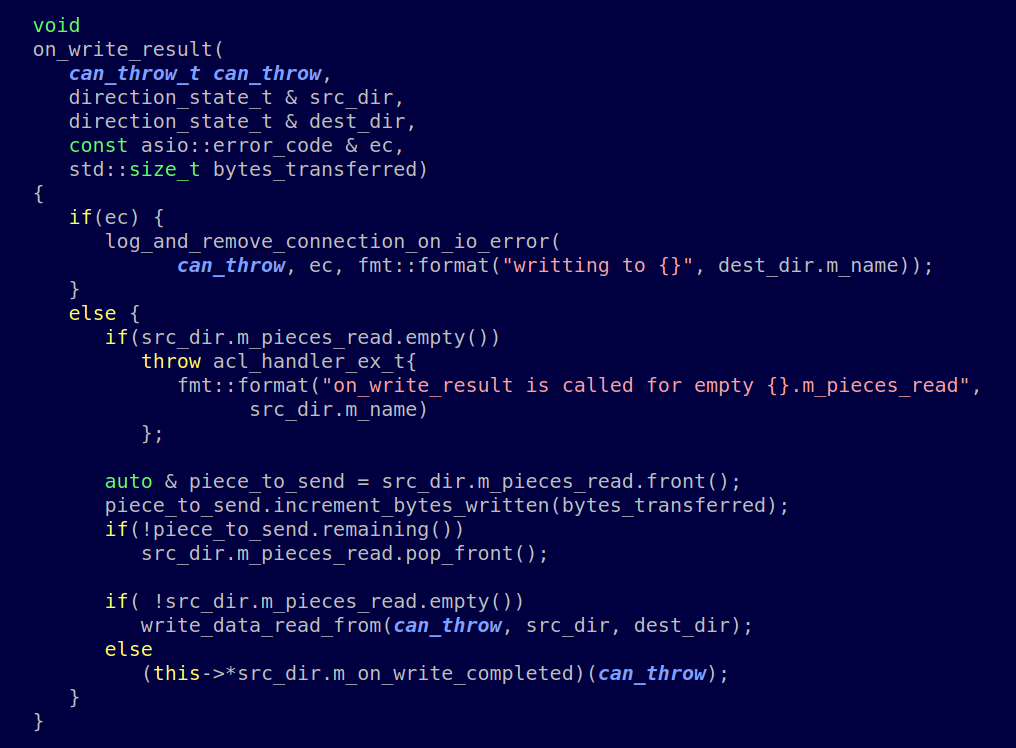






 Недавно в одном из проектов встала задача: есть набор множеств (Set), которые надо достаточно эффективно хранить в оперативной памяти. Потому что множеств много, а памяти мало. И с этим надо что-то делать.
Недавно в одном из проектов встала задача: есть набор множеств (Set), которые надо достаточно эффективно хранить в оперативной памяти. Потому что множеств много, а памяти мало. И с этим надо что-то делать.