

Рассказываю из личного опыта, что где и когда пригодилось. Обзорно и тезисно, чтобы понятно было, что и куда можно копать дальше — но тут у меня исключительно субъективный личный опыт, у вас, может быть, все совсем по-другому.
Почему важно знать и уметь обращаться с языками запросов? По своей сути в Data Science есть несколько важнейших этапов работы и самый первый и важнейший (без него уж точно ничего работать не будет!) — это получение или извлечение данных. Чаще всего данные в каком-то виде где-то сидят и их нужно оттуда «достать».
Языки запросов как раз и позволяют эти самые данные извлечь! И сегодня я расскажу, о тех языках запросов, которые мне пригодились и расскажу-покажу, где и как именно — зачем оно нужно для изучения.
Всего будет три основных блока типов запросов к данным, которые мы разберем в данной статье:
- «Стандартные» языки запросов — то, что обычно понимают, когда говорят о языке запросов, как, например, реляционная алгебра или SQL.
- Скриптовые языки запросов: например, питоновские штучки pandas, numpy или shell scripting.
- Языки запросов к графам знаний и графовым базам данных.
Все написанное здесь — это просто персональный опыт, что пригодилось, с описанием ситуаций и «зачем оно было нужно» — каждый может примерить, насколько подобные ситуации могут встретиться вам и попробовать подготовиться к ним заранее, разобравшись с этими языками до того, как придется их в (срочном порядке) применять на проекте или вообще попасть на проект, где они нужны.











 В данной статье я изложу свой взгляд на проведение онлайн курсов: какие есть игроки в Интернете, и чего, на мой взгляд, категорически не хватает в Рунете (Ау-у, разработчики!). В конце опрос.
В данной статье я изложу свой взгляд на проведение онлайн курсов: какие есть игроки в Интернете, и чего, на мой взгляд, категорически не хватает в Рунете (Ау-у, разработчики!). В конце опрос.
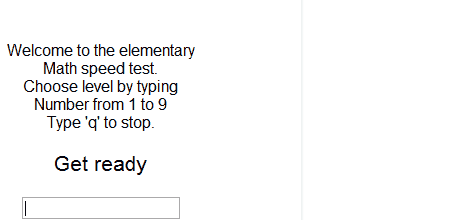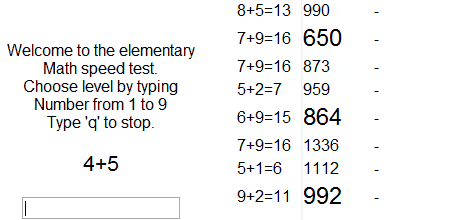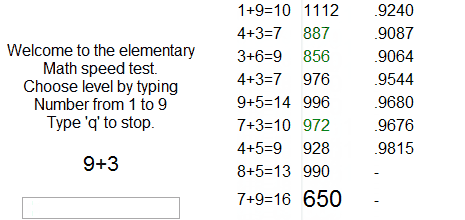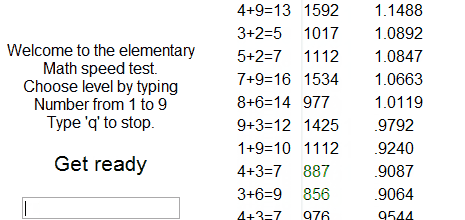



 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.