Статьи по прослушиванию оптоволокна достаточно редки в силу определенной специфики такого рода коммуникаций. По мере удешевления оборудования и стоимости организации каналов связи на основе оптоволокна, они давно применяются в коммерческой практике. Специалистам ИТ, отвечающим за вопросы безопасности коммуникаций, стоит знать об основных источниках угроз и методах противодействия. Данная статья представляет собой перевод научной работы, опубликованной в материалах конференции HONET (High Capacity Optical Networks and Enabling Technologies ) в 2012 году. В сети удалось найти полнотекстовый авторский препринт, датированный осенью 2011 года, который, хотя и содержит некоторые ошибки (авторы не являются оригинальными носителями английского языка), тем не менее достаточно хорошо описывает существующие проблемы.

sysprg @sysprg
User
Программная расстановка коэффициентов в химических уравнениях
2 min
Введение
Все, кто когда-нибудь изучал химию, знают, что это наука сложная и в многих моментах не совсем понятная. Например, у учеников средних и старших классов часто возникают проблемы с решением химических задач и уравнений. Поэтому они часто ищут ответ на задание с помощью химических калькуляторов. Но большинство программ этого класса нельзя назвать калькулятором — они не считают, а только проверяют результат в базе данных. Этот способ имеет очень большой недостаток — программа не выдаст результат, если уравнения реакции не будет в базе. Поэтому есть необходимость использовать алгоритм, который даст возможность находить коэффициенты программно. И такой алгоритм существует.
Повторяющийся зубчатый фон на CSS
2 min

Давно на хабре не было постов про CSS и я решил восполнить этот пробел. Сегодня мы учимся готовить зубчатый фон используя только средства CSS и никаких изображений!
Важные требования к такому забору:
- Никаких изображений!
- Он должен спокойно тянуться по горизонтали
- Обязательно должен поддерживать неравномерный фон у подложки
- Фон не должен требовать никакой экстра-разметки. Лучше всего будет избегать псевдо-элементов (экономия — хорошо).
Поддерживаемые браузеры: Chrome, Firefox (> 3.6), Opera (>= 12), Safari (>= 5), IE10.
Для IE 7, 8 у нас будет фоллбэк в виде обычной заливки. А вот с IE9 проблема — он не поддерживает градиенты, но при этом понимает hsla и rgba цвета. Воистину «великолепный» браузер. Что ж, его пока придётся игнорировать. Если кто–то подскажет хороший фоллбэк для IE буду только благодарен.
Рекомендательная система: достаем теги пользователей из соцсетей
5 min
Сегодня я расскажу о том, как можно использовать данные о пользователях из социальных сетей для рекомендаций веб-страниц на холодном старте. Все приведенные в статье результаты носят чисто экспериментальный характер и в настоящий момент не реализованы в продакшене. Здесь, как и в прошлой статье, будут использоваться элементы текстмайнига для анализа текстового контента веб-страниц.
Сначала немного статистики для того, чтобы показать важность настоящего исследования. Около 50% пользователей нашей системы регистрируются с привязкой аккаунтов социальных сетей vkontakte (VK) и facebook (FB). Причем из зарегистрированных через социальные сети 71% приходится на VK и 29% на FB.
API FB и API VK позволяют извлекать некоторые данные об интересах и предпочтениях пользователя. Но не все так просто, как может показаться. Для получения данных пользователя нужно получить особые права, согласие на которые дает сам пользователь при регистрации в системе. Здесь возникает тонкий момент. С одной стороны, мы ходим вытянуть как можно больше информации о пользователе. С другой стороны, просить слишком много прав — наглость, которая может отпугнуть пользователя. Нужно найти компромисс — тонкое равновесие между полезностью получаемых данных для улучшения рекомендаций и «суммой» кредита доверия от пользователя, который соглашается, чтобы мы залезли в его персональные данные.
Сначала немного статистики для того, чтобы показать важность настоящего исследования. Около 50% пользователей нашей системы регистрируются с привязкой аккаунтов социальных сетей vkontakte (VK) и facebook (FB). Причем из зарегистрированных через социальные сети 71% приходится на VK и 29% на FB.
API FB и API VK позволяют извлекать некоторые данные об интересах и предпочтениях пользователя. Но не все так просто, как может показаться. Для получения данных пользователя нужно получить особые права, согласие на которые дает сам пользователь при регистрации в системе. Здесь возникает тонкий момент. С одной стороны, мы ходим вытянуть как можно больше информации о пользователе. С другой стороны, просить слишком много прав — наглость, которая может отпугнуть пользователя. Нужно найти компромисс — тонкое равновесие между полезностью получаемых данных для улучшения рекомендаций и «суммой» кредита доверия от пользователя, который соглашается, чтобы мы залезли в его персональные данные.
Завершилось соревнование по дата-майнингу Heritage Health Prize
3 min
Крупнейшее со времен Netflix Prize соревнование в области анализа больших массивов данных подошло к концу. И хотя официальные результаты первой десятки и победитель будут объявлены через два месяца, итоги уже можно подводить.
Целью было спрогнозировать госпитализацию пациентов в течение будущего года на основании данных за предыдущие два года лечения. По замыслу спонсора это позволит больше внимания уделять именно тем пациентам, которые больше всего в нем нуждаются, за счет чего сэкономить часть из 30 млрд. $, ежегодно затрачиваемых в США на госпитализацию.
Заявленный организаторами приз в 3 000 000$ был недостижим из-за установленного предела точности в 0.4 RMSLE(меньше-лучше; лучший достигнутый результат 0.46; разница между первым и сотым местом 0.008; RMSLE — среднеквадратическое отклонение логарифмов) и предоставленных данных — в них просто не содержалось достаточного для достижения такого уровня точности количества информации. Поэтому фактически борьба шла за 500 000$, достающиеся лучшей команде, фонд промежуточных финишей и бесценный опыт.

Blind Deconvolution — автоматическое восстановление смазанных изображений
6 min
Смазанные изображения — один из самых неприятных дефектов в фотографии, наравне с расфокусированными изображениями. Ранее я писал про алгоритмы деконволюции для восстановления смазанных и расфокусированных изображений. Эти, относительно простые, подходы позволяют восстановить исходное изображение, если известна точная траектория смаза (или форма пятна размытия).
В большинстве случаев траектория смаза предполагается прямой линией, параметры которой должен задавать сам пользователь — для этого требуется достаточно кропотливая работа по подбору ядра, кроме того, в реальных фотографиях траектория смаза далека от линии и представляет собой замысловатую кривую переменной плотности/яркости, форму которой крайне сложно подобрать вручную.

В последние несколько лет интенсивно развивается новое направлении в теории восстановления изображений — слепая обратная свертка (Blind Deconvolution). Появилось достаточно много работ по этой теме, и начинается активное коммерческое использование результатов.
Многие из вас помнят конференцию Adobe MAX 2011, на которой они как раз показали работу одного из алгоритмов Blind Deconvolution: Исправление смазанных фотографий в новой версии Photoshop
В этой статье я хочу подробнее рассказать — как же работает эта удивительная технология, а также показать практическую реализацию SmartDeblur, который теперь тоже имеет в своем распоряжении этот алгоритм.
Внимание, под катом много картинок!
В большинстве случаев траектория смаза предполагается прямой линией, параметры которой должен задавать сам пользователь — для этого требуется достаточно кропотливая работа по подбору ядра, кроме того, в реальных фотографиях траектория смаза далека от линии и представляет собой замысловатую кривую переменной плотности/яркости, форму которой крайне сложно подобрать вручную.
В последние несколько лет интенсивно развивается новое направлении в теории восстановления изображений — слепая обратная свертка (Blind Deconvolution). Появилось достаточно много работ по этой теме, и начинается активное коммерческое использование результатов.
Многие из вас помнят конференцию Adobe MAX 2011, на которой они как раз показали работу одного из алгоритмов Blind Deconvolution: Исправление смазанных фотографий в новой версии Photoshop
В этой статье я хочу подробнее рассказать — как же работает эта удивительная технология, а также показать практическую реализацию SmartDeblur, который теперь тоже имеет в своем распоряжении этот алгоритм.
Внимание, под катом много картинок!
Робастные эстиматоры (Robust estimators)
6 min
Tutorial
Сразу хочу извиниться, про робастные эстиматоры я узнал из англоязычной литературы, поэтому некоторые термины являются прямой калькой с английских, вполне может быть, что в русскоязычной литературе тема о робастных оценках имеет какие то свои устойчивые обороты.
Обработка и классификация запросов. Часть первая: парсер запросов
7 min
Чем занят отдел обработки запросов в Поиске Mail.Ru? Если одним предложением, мы пытаемся «понять» запрос, то есть осуществляем подготовку запроса к поиску, приводим его в вид, пригодный для взаимодействия с нашим индексом, ранжированием, подмесами и прочими компонентами. Если же вы хотите узнать о нашей работе подробнее — добро пожаловать под кат. В этом посте я расскажу об одной из областей нашей работы — парсере запросов.
Возвращаем приватность или большой брат следит за мной на стандартных настройках. Часть 2. Блокируем следящие скрипты на сайтах и настраиваем VPN
7 min
Tutorial
Recovery Mode
В первой части мы говорили об общих настройках для всех браузеров, вскользь прошлись по паролям, шифрованию и бекапе, а также несколько усложнили жизнь «Гуглу».
Сегодня посмотрим (и избавимся) на то, сколько статистики собирают на нас даже без использования сторонних «куки»-файлов и расскажем о пользе и настройке VPN простым языком.
Хочу сказать большое спасибо всем, кто оставлял комментарии в прошлой статье (и оставит в этой) — все ваши дельные советы будут включены в этот или последующий мануалы.

Сегодня посмотрим (и избавимся) на то, сколько статистики собирают на нас даже без использования сторонних «куки»-файлов и расскажем о пользе и настройке VPN простым языком.
Хочу сказать большое спасибо всем, кто оставлял комментарии в прошлой статье (и оставит в этой) — все ваши дельные советы будут включены в этот или последующий мануалы.
Уроки рисования или как снимался фильм «Секунда свободного падения»
7 min
На киносъемках очень популярна фраза: «А, фиг с ним, на постпродашкене дорисуем!». Такой чудесной вещи, как доработке на постпродакшене съемочного «фиг с ним», и посвящена сия статья. Здесь я расскажу о личном опыте и пользе использования данного заклинания во время работы над короткометражным фильмом «Секунда свободного падения», режиссёром коего являюсь.


До начала съемок я не планировал пользоваться цифровой обработкой вообще (за исключением разве что цветокоррекции), желая добиться максимально реалистичного изображения. Ну-ну!.. Волшебное «фиг с ним» имеет невероятную мощь, всем чародеям известно это!
До начала съемок я не планировал пользоваться цифровой обработкой вообще (за исключением разве что цветокоррекции), желая добиться максимально реалистичного изображения. Ну-ну!.. Волшебное «фиг с ним» имеет невероятную мощь, всем чародеям известно это!
Компания IBM придумала транзистор с ионной жидкостью
2 min

Специалисты IBM спроектировали новый тип транзистора, который подходит для создания нового класса энергонезависимой памяти. Этот транзистор в качестве полупроводника использует не кремний, а диоксид ванадия (VO2). Под воздействием положительно заряженной ионной жидкости он совершает фазовый переход в металлическое состояние, а в отрицательном поле снова превращается в изолятор.
Видимость сквозь турбулентную атмосферу. Компьютерная коррекция изображений удаленных объектов
6 min
Авторский пересказ двух публикаций с демонстрационным фильмом.
Предлагается решение задачи улучшения видимости далеких предметов, наблюдаемых сквозь случайно-неоднородную атмосферу. Метод основан на обработке в реальном времени последовательных кадров, снятых цифровой видеокамерой с длиннофокусным объективом. В фильме показаны, как мне кажется, довольно эффектные результаты.
Предлагается решение задачи улучшения видимости далеких предметов, наблюдаемых сквозь случайно-неоднородную атмосферу. Метод основан на обработке в реальном времени последовательных кадров, снятых цифровой видеокамерой с длиннофокусным объективом. В фильме показаны, как мне кажется, довольно эффектные результаты.
Курс лекций «Стартап». Питер Тиль. Стенфорд 2012. Занятие 12
26 min
Tutorial
Translation

Весной 2012 г., Питер Тиль (Peter Thiel), один из основателей PayPal и первый инвестор FaceBook, провел курс в Стенфорде — «Стартап». Перед началом Тиль заявил: «Если я сделаю свою работу правильно, это будет последний предмет, который вам придется изучать».
Один из студентов лекции записывал и выложил транскипт. В данном хабратопике astropilot переводит двенадцатое занятие.
Занятие 1: Вызов будущего
Занятие 2: Снова как в 1999?
Занятие 3: Системы ценностей
Занятие 4: Преимущество последнего хода
Занятие 5: Механика мафии
Занятие 6: Закон Тиля
Занятие 7: Следуйте за деньгами
Занятие 8: Презентация идеи (питч)
Занятие 9: Все готово, а придут ли они?
Занятие 10: После Web 2.0
Занятие 11: Секреты
Занятие 12: Война и мир
Занятие 13: Вы — не лотерейный билет
Занятие 14: Экология как мировоззрение
Занятие 15: Назад в будущее
Занятие 16: Разбираясь в себе
Занятие 17: Глубокие мысли
Занятие 18: Основатель — жертва или бог
Занятие 19: Стагнация или сингулярность?
Действительно ли у каждого ядра есть «свой собственный» кэш первого и второго уровней?
6 min
У современных процессоров архитектуры Core i7 существует очевидный, документированный, но отчего-то не очень известный даже среди многих специалистов сценарий priority inversion. Его я опишу в этом посте. В нем есть код на С, три диаграммы, и некоторые подробности работы кэшей в процессорах архитектуры Core i7. Никаких покровов не срывается, вся информация давно общедоступна.
Priority inversion – ситуация, когда низкоприоритетный процесс может блокировать или замедлять высокоприоритетный. Обычно имеется в виду очередность доступа к исполнению на ядре для высокоприоритетного кода относительно низкоприоритетного. С этим должно неплохо справляться ядро ОС. Однако помимо вычислительных ядер, которые несложно распределять посредством affinity и MSI-X, в процессоре есть ресурсы, общие для всех задач – контроллер памяти, QPI, общий кэш третьего уровня, PCIe устройства. В вопросы PCIe я углубляться не буду, т.к. не являюсь экспертом в данной теме. Priority inversion на почве доступа к памяти и QPI я давно не наблюдал – пропускной способности современного многоканального контроллера как правило хватает и высокоприоритетным, и низкоприоритетным задачам. Остановлюсь на кэшах.
Priority inversion – ситуация, когда низкоприоритетный процесс может блокировать или замедлять высокоприоритетный. Обычно имеется в виду очередность доступа к исполнению на ядре для высокоприоритетного кода относительно низкоприоритетного. С этим должно неплохо справляться ядро ОС. Однако помимо вычислительных ядер, которые несложно распределять посредством affinity и MSI-X, в процессоре есть ресурсы, общие для всех задач – контроллер памяти, QPI, общий кэш третьего уровня, PCIe устройства. В вопросы PCIe я углубляться не буду, т.к. не являюсь экспертом в данной теме. Priority inversion на почве доступа к памяти и QPI я давно не наблюдал – пропускной способности современного многоканального контроллера как правило хватает и высокоприоритетным, и низкоприоритетным задачам. Остановлюсь на кэшах.
Уменьшение социального налога для IT-компаний с 30% до 14%
4 min
Кто про что, а мы опять про оптимизацию. На этот раз пишу про уменьшение социального налога. На хабре, начиная с 2011 года, уже много раз обсуждался закон про уменьшение налоговой ставки для IT-компаний. Действительно, с 34% (сейчас это 30%) ставку можно уменьшить сначала до 20%, а потом, если сильно постараться, то и до 14%. Согласитесь, что разница 30 и 14 уже заметная. Этот вопрос стоит проработать. Что для этого нужно и так ли это сложно?
Необычный редактор меню — Drop Down Menu Generator
4 min
Меню это самый простой, быстрый и удобный способ навигации. От того, на сколько хорошо сделано меню, зависит успех сайта. Существует множество примеров создания меню и готовых библиотек. С их помощью можно вставить выпадающее меню в страницу. Но, к сожалению, почти все они имеют следующие недостатки.
- Плохая совместимость с популярными браузерами
Это самая острая проблема. Практика показывает, что даже если пример сделан с учетом современных стандартов, то это не гарантирует, что он будет одинаково хорошо работать под современными браузерами. А более ранние, но популярные сегодня браузеры, не полностью поддерживают современные стандарты.
Чья морфология лучше? Яндекс vs Google
3 min
Бытует мнение, что русская морфология у Яндекса реализована лучше чем у Google. В этой статье я покажу, что дело обстоит ровным счетом наоборот.

Рекомендательная система: полезные задачи текстмайнинга
4 min
Я продолжаю цикл статей по применению текстмайнинг-методов для решения различных задач, возникающих в рекомендательной системе веб-страниц. Сегодня я расскажу о двух задачах: автоматическое определение категорий для страниц из RSS-лент и поиск дубликатов и плагиата среди веб-страниц. Итак, по порядку.
Обычная схема добавления веб-страниц (вернее, ссылок на них) в Surfingbird такова: при добавлении новой ссылки пользователь должен указать до трёх категорий, к которым принадлежит эта ссылка. Понятно, что в такой ситуации задача автоматического определения категорий не стоит. Однако, кроме ручного добавления, ссылки попадают в базу и из RSS-потоков, которые предоставляют многие популярные сайты. Поскольку ссылок, поступающих через RSS-потоки, очень много, зачастую модераторы (а в этом случае именно они вынуждены проставлять категории) просто не справляются с таким объёмом. Возникает задача создания интеллектуальной системы автоматической классификации по категориям. Для ряда сайтов (например, lenta.ru или sueta.ru) категории можно вытащить непосредственно из rss-xml и вручную привязать к нашим внутренним категориям:
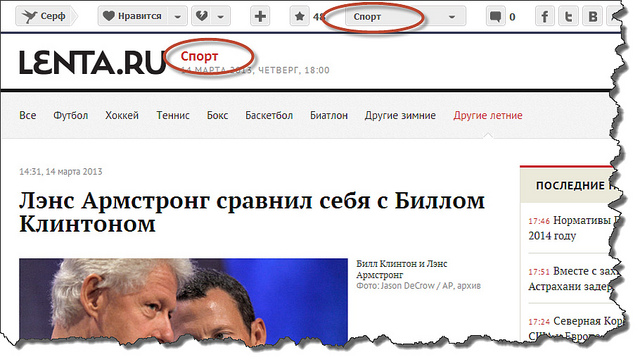
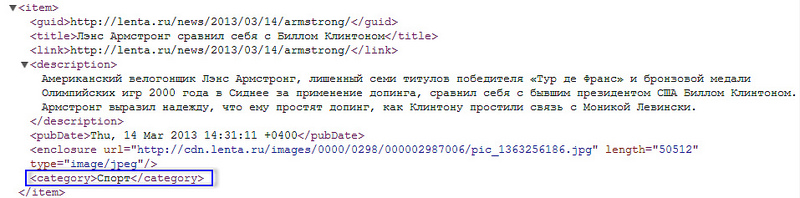
Автоматическое определение категорий для веб-страниц из RSS-лент
Обычная схема добавления веб-страниц (вернее, ссылок на них) в Surfingbird такова: при добавлении новой ссылки пользователь должен указать до трёх категорий, к которым принадлежит эта ссылка. Понятно, что в такой ситуации задача автоматического определения категорий не стоит. Однако, кроме ручного добавления, ссылки попадают в базу и из RSS-потоков, которые предоставляют многие популярные сайты. Поскольку ссылок, поступающих через RSS-потоки, очень много, зачастую модераторы (а в этом случае именно они вынуждены проставлять категории) просто не справляются с таким объёмом. Возникает задача создания интеллектуальной системы автоматической классификации по категориям. Для ряда сайтов (например, lenta.ru или sueta.ru) категории можно вытащить непосредственно из rss-xml и вручную привязать к нашим внутренним категориям:
Рекомендательная система: text mining как средство борьбы с холодным стартом
5 min
В предыдущей статье я уже обозначил основные направления решения задачи холодного старта в рекомендательной системе веб-страниц. Напомню, что проблема холодного старта делится на холодный старт для пользователей (что показывать новым пользователям) и холодный старт для сайтов (кому рекомендовать вновь добавленные сайты). Сегодня я более подробно остановлюсь на методе семантического анализа текстов (text mining) как основном подходе к решению проблемы холодного старта для новых сайтов.