❯ Часть первая: физическая память
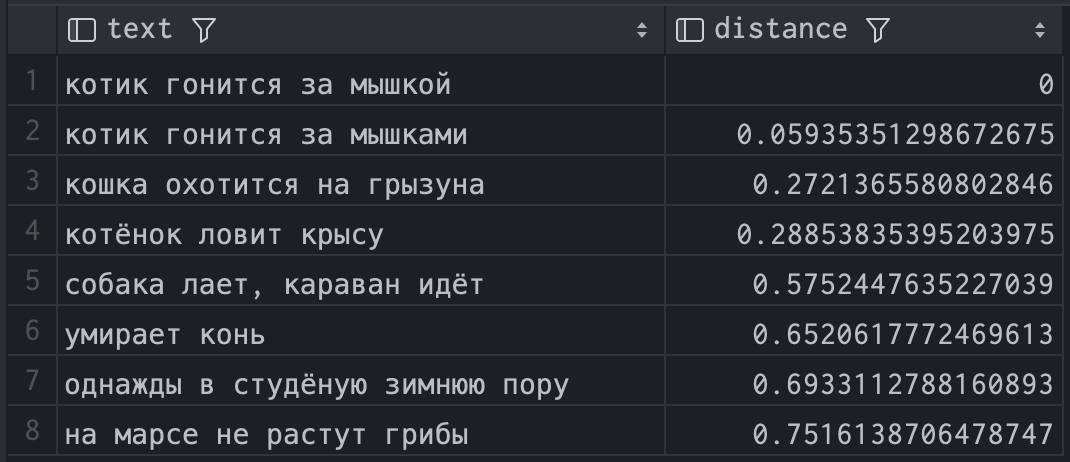
При создании операционных систем всегда уделяется внимание работе с памятью. Память — это компонент компьютера, где хранятся программы и данные, и без нее современные компьютеры не могли бы функционировать. Важной единицей хранения данных в памяти является бит, который может принимать два значения: 0 или 1. Память состоит из ячеек, каждая из которых имеет свой адрес. Ячейки могут содержать различное количество битов, и количество адресуемых ячеек зависит от количества бит в адресе.
Также память включает в себя оперативное запоминающее устройство (ОЗУ) или RAM, где можно записывать и считывать информацию. Существует статическая ОЗУ (SRAM) и динамическая ОЗУ (DRAM), различающиеся в том, как хранится информация. В SRAM информация сохраняется до выключения питания, в то время как в DRAM используются транзисторы и конденсаторы, что позволяет хранить данные, но требует их периодического обновления. Разные типы ОЗУ имеют свои преимущества и недостатки, и выбор зависит от конкретных потребностей.
Понимание работы с памятью в компьютере важно для всех, кто работает с техникой и программным обеспечением. Важно знать, как устроена память, какие ее типы существуют и как эти типы могут влиять на производительность и функционирование компьютера.
Но что такое физическая память, как она работает в Linux? Что такое сегментация, утечки памяти и некие «страницы»?
Все, что вы хотели знать, но боялись спросить о памяти пингвина — читайте здесь и сейчас!