
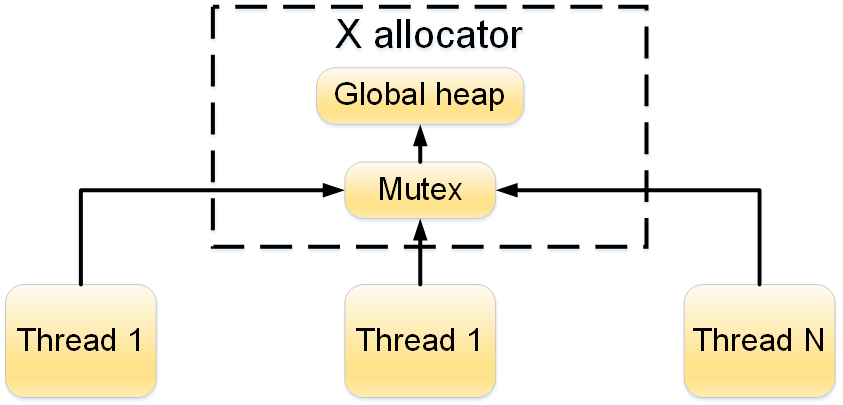
Построение lock-free структур данных зиждется на двух китах – атомарных операциях и способах упорядочения доступа к памяти. В этой статье речь пойдет об атомарности и атомарных примитивах.
Анонс. Спасибо за теплый прием
Начал! Вижу, что тема lock-free интересна хабрасообществу, это меня радует. Я планировал построить цикл по академическому принципу, плавно переходя от основ к алгоритмам, попутно иллюстрируя текст кодом из libcds. Но часть читателей требует
зрелищ не мешкая показать, как пользоваться библиотекой, особо не рассусоливая. Я согласен, в этом есть свой резон. В конечном счете, и мне не так интересно, что там внутри
boost, — опишите, как его применять! Поэтому свой эпический цикл я разделю на три части:
Основы,
Внутри и
Извне. Каждая статья эпопеи будет относится к одной из частей. В
Основах будет рассказываться о низкоуровневых вещах, вплоть до строения современных процессоров; это часть для почемучек вроде меня.
Внутри будет освещать интересные алгоритмы и подходы в мире lock-free, — это скорее теория о том, как реализовать lock-free структуру данных, libcds будет неисчерпаемым источником C++ кода. В
Извне будут статьи о практике применения libcds, — программные решения, советы и FAQ.
Извне будет питаться вашими вопросами/замечаниями/предложениями, дорогие хабражители.
А пока я судорожно готовлю начало
Извне, — первая часть
Основ. Статья во многом не о C++ (хотя и о нем тоже) и даже не о lock-free (хотя без atomic lock-free алгоритмы неработоспособны), а о реализации атомарных примитивов в современных процессорах и о базовых проблемах, возникающих при использовании таких примитивов.
Атомарность — это первый
круг ада низкий уровень из двух.

 Вторая заметка о создании Warcraft от одного из создателей серии — Патрика Вайата. В первой части он обещал нам рассказать о многих интересных деталях и сдержал обещание. Правда рассказал о совсем других деталях, но они от этого еще интереснее.
Вторая заметка о создании Warcraft от одного из создателей серии — Патрика Вайата. В первой части он обещал нам рассказать о многих интересных деталях и сдержал обещание. Правда рассказал о совсем других деталях, но они от этого еще интереснее.

 Давайте представим себе типичный, набирающий популярность стартап, использующий, например, PHP или Python. Сначала все находится на одном сервере — PHP (или Python), Apache, MySQL. Затем вы выносите MySQL на отдельный сервер, устанавливаете nginx для раздачи контента, возможно, добавляете memcached для кеширования и еще несколько серверов приложений…
Давайте представим себе типичный, набирающий популярность стартап, использующий, например, PHP или Python. Сначала все находится на одном сервере — PHP (или Python), Apache, MySQL. Затем вы выносите MySQL на отдельный сервер, устанавливаете nginx для раздачи контента, возможно, добавляете memcached для кеширования и еще несколько серверов приложений…