Один из способов доморощенной классификации служб основывается на времени их жизни: некоторые из них запускаются сразу же при старте ОС, оставаясь активными постоянно (сюда, скажем, можно отнести веб-серверы и СУБД), другие же запускаются лишь при необходимости, делают свои архиважные дела и сразу завершаются; при этом, ни один из вариантов сам по себе не делает реализацию службы сложнее, однако второй требует от разработчика как минимум ещё и умения программно стартовать, а при необходимости и досрочно останавливать её работу. Именно указанный аспект управления службой, плюс добавление некоторых отсутствующих в штатной поставке Delphi возможностей, и сподвиг автора на данный опус.
Чтобы статья воспринималась максимально полезной и практичной, в ней предлагается заготовка (почти готовый к употреблению шаблон) службы, обрабатывающей очередь неких задач (или заданий – кому как больше нравится); после того, как все из них обработаны, служба тут же завершается. Если представить графически, то читатель познакомится со следующей конструкцией:
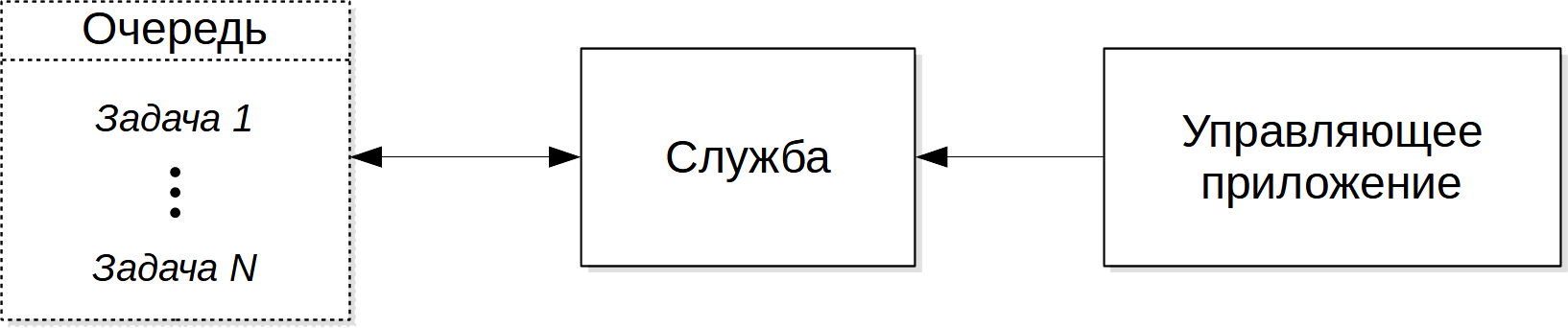
Чтобы статья воспринималась максимально полезной и практичной, в ней предлагается заготовка (почти готовый к употреблению шаблон) службы, обрабатывающей очередь неких задач (или заданий – кому как больше нравится); после того, как все из них обработаны, служба тут же завершается. Если представить графически, то читатель познакомится со следующей конструкцией: