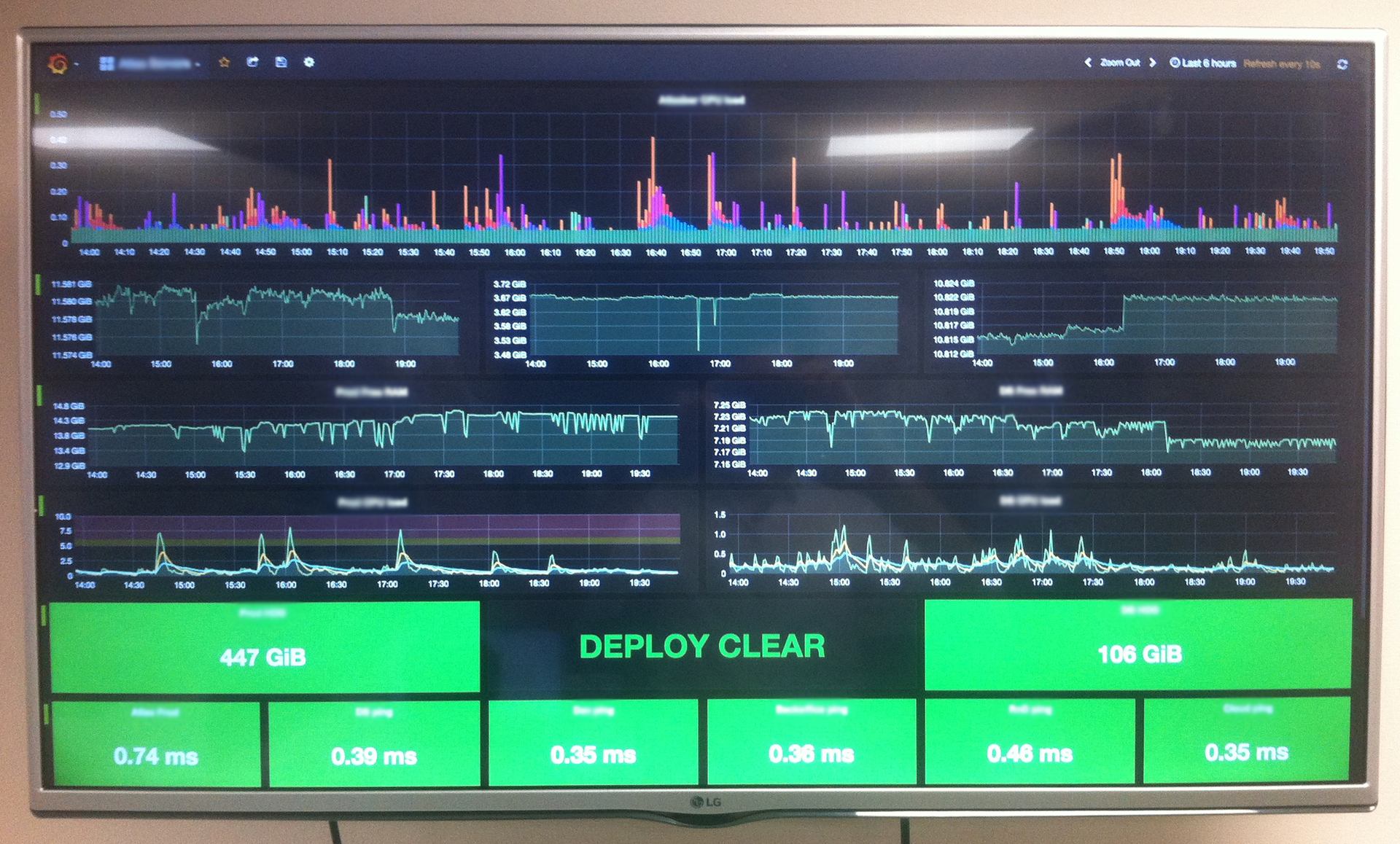
Мы в Атласе любим, когда все находится под контролем. Это касается и всей серверной инфраструктуры, которая, с годами, превратилась в живой организм из многочисленных виртуальных машин, сервисов и служб. Появилась потребность наблюдать за жизненно важными аспектами IT-составляющей нашей деятельности: мониторить боевой сервер, отслеживать изменения системных ресурсов на виртуалках баз данных, следить за ходом бизнес-процессов и тд. Встал вопрос — как же этого добиться и главное какими инструментами? Стали искать какие-то готовые решения. Перепробовали кучу платных/бесплатных сервисов, которые, якобы, предоставляли бы нам "самую ценную" информацию о состоянии нашей системы. Но, в конечном итоге, все сводилось к каким-то непонятных диаграммам, схемам и цифрам, которые, по сути, для нас не имели никакой ценности.
Так мы пришли к пониманию, что надо собирать что-то самостоятельно. За основу решили взять самую гибкую и продвинутую систему, которую можно настроить для мониторинга чего и как угодно — Nagios. Настроили, поставили, работает — круто! Жаль только интерфейс сего чуда застрял где-то в середине 90-х, а нам хотелось, чтобы еще и визуальная составляющая была на уровне.
Недолгий поиск показал, что лидером среди решений по созданию красивых дашбордов является Grafana. Так и решили выводить весь наш мониторинг из Nagios на мониторах в виде красивых графиков в Grafana. Вопрос остался только в том — как их подружить друг с другом?







 В топике блиц-обзор книг, которые будут полезны IT-специалистам, бизнесменам и тем, кто собирается открыть своё дело. Рядом с каждой — короткие пояснения, почему и зачем стоит прочесть.
В топике блиц-обзор книг, которые будут полезны IT-специалистам, бизнесменам и тем, кто собирается открыть своё дело. Рядом с каждой — короткие пояснения, почему и зачем стоит прочесть.