Мы уже привыкли, что запуск тестов производится нажатием одной кнопки. Проверки проходят автоматически при каждом коммите, статистики собираются без участия тестировщика, а баги заводятся в полуавтоматическом режиме. В общем, мы привыкли применять технологии программной и системной инженерии к нашим программным проектам. А теперь представьте себе, что перед вами стоит задача протестировать работу атомной электростанции. Нужно не только протестировать её софт, но и провести испытания всех её составляющих.
Разумеется, никто не сможет сначала построить станцию и потом перенести несущую стену из-за того, что система вентиляции не сможет быть смонтирована в текущей конфигурации. Поэтому процессы реального мира всё больше уходят в «цифру». Как вам понравится комментарий к коммиту «Перенос капитальной стены на 2 метра севернее»? При проектировании и тестировании АЭС применяется полностью цифровой подход: создается информационная модель, к ней применяется классическая V-модель управления жизненным циклом. Таким образом, АЭС превращается в тиражируемый и полностью цифровой объект. Тестирование и запуск современных АЭС происходит в цифровом виде, и только после этого строители приступают к монтажу, используя всё те же цифровые модели.
Из этой статьи вы узнаете о том, что представляет собой современная информационная система, как происходит разработка и тестирование «капитальных» объектов на примере АЭС.
В основе материала — расшифровка
доклада Вячеслава Аленькова, директора по системной инженерии и информационным технологиям инжиниринговой компании «Атомстройэкспорт» (ASE) с нашей декабрьской конференции Heisenbug 2017 Moscow.





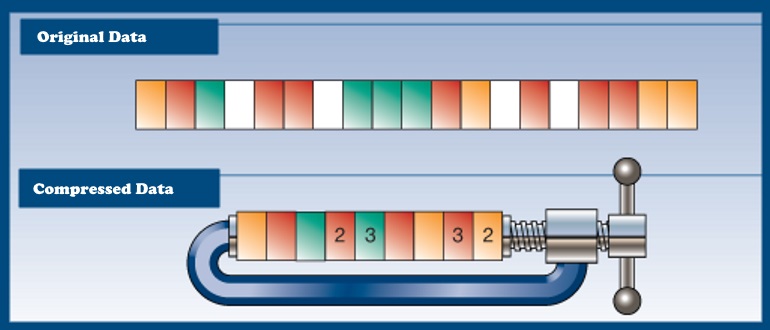






 Мы продолжаем знакомить вас с внутренним устройством
Мы продолжаем знакомить вас с внутренним устройством 