Эта статья рассказывает о проблемах, которые поджидают программиста, работающего с часовыми поясами. В теории, вроде, всё хорошо, просто и понятно, но жизнь — штука сложная, и на практике, порой, возникают совершенно неожиданные ситуации.
TL;DR: Работа с таймзонами — это боль и унижение. Никогда не работайте с таймзонами!
Итак, все кругом твердят вам, что при получении времени от пользователя нужно сразу же переводить его в UTC, работать со временем нужно только в UTC и хранить время тоже нужно строго в UTC. Совет, на первый взгляд, выглядит разумным, и следование ему делает вашу жизнь проще… Если только ваша программа не предполагает сложной работы с датами. Записать в базу данных дату и время регистрации пользователя на сайте? Сохранить время отправки сообщения или дату создания заказа в интернет-магазине? Вывести сообщение в лог с указанием даты-времени? Используйте UTC и всё будет в порядке, можете даже не читать эту статью дальше. Любое текущее время можно совершенно спокойно конвертировать в UTC и забыть о проблемах. Но что, если мы хотим работать с временем в будущем? Или в прошлом? Например, если мы пишем сервис календаря, или сервис для отложенной отправки сообщений?
TL;DR: Работа с таймзонами — это боль и унижение. Никогда не работайте с таймзонами!
Итак, все кругом твердят вам, что при получении времени от пользователя нужно сразу же переводить его в UTC, работать со временем нужно только в UTC и хранить время тоже нужно строго в UTC. Совет, на первый взгляд, выглядит разумным, и следование ему делает вашу жизнь проще… Если только ваша программа не предполагает сложной работы с датами. Записать в базу данных дату и время регистрации пользователя на сайте? Сохранить время отправки сообщения или дату создания заказа в интернет-магазине? Вывести сообщение в лог с указанием даты-времени? Используйте UTC и всё будет в порядке, можете даже не читать эту статью дальше. Любое текущее время можно совершенно спокойно конвертировать в UTC и забыть о проблемах. Но что, если мы хотим работать с временем в будущем? Или в прошлом? Например, если мы пишем сервис календаря, или сервис для отложенной отправки сообщений?

 Разработка Parallels Access потребовала создания геораспределенного сервиса, позволяющего безопасно устанавливать связь между компьютерами и мобильными клиентами пользователей в различных точках земного шара. Команда, которая над ним трудится, хочет поделиться полученным опытом в форме цитат, чтобы облегчить участь тем, кто только планирует создание своего клиент/серверного продукта, и погрузить в ностальгию профессионалов, имеющих за спиной дюжину успешных проектов:
Разработка Parallels Access потребовала создания геораспределенного сервиса, позволяющего безопасно устанавливать связь между компьютерами и мобильными клиентами пользователей в различных точках земного шара. Команда, которая над ним трудится, хочет поделиться полученным опытом в форме цитат, чтобы облегчить участь тем, кто только планирует создание своего клиент/серверного продукта, и погрузить в ностальгию профессионалов, имеющих за спиной дюжину успешных проектов: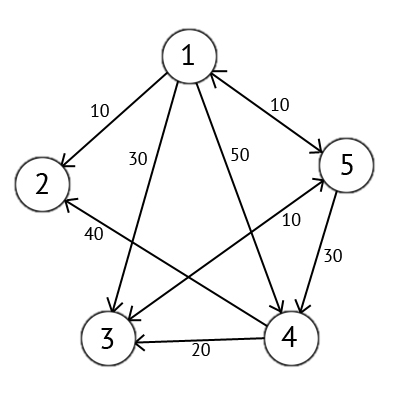


 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.