Я обучил небольшой (порядка 10 миллионов параметров) трансформер по превосходному туториалу Let’s build GPT: from scratch, in code, spelled out Андрея Карпати. После того, как он заработал, я захотел максимально глубоко понять, как он устроен внутри и как создаёт свои результаты.
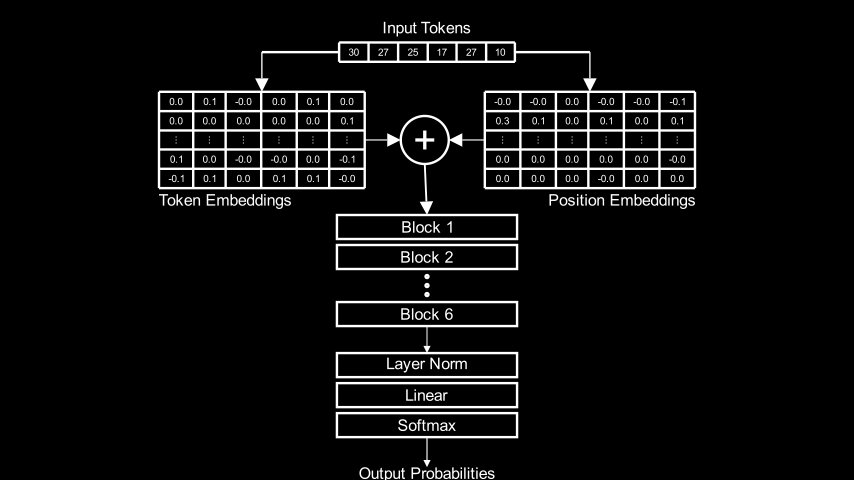
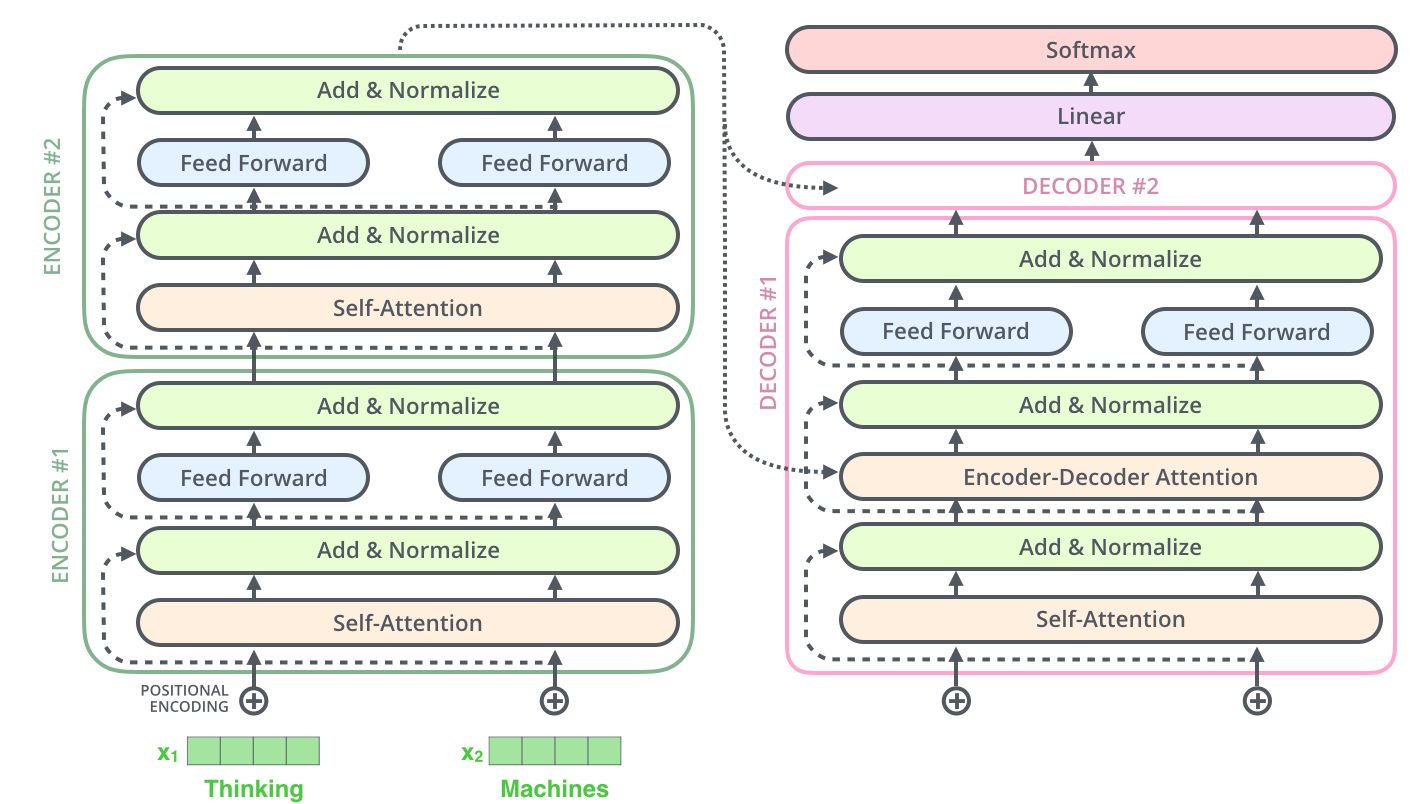
В исходной научной статье, как и во всех туториалах по трансформерам упор в основном делается на многоголовом самовнимании, — механизме, при помощи которого трансформеры обучаются множественным взаимосвязям между токенами, не используя рекурретности или свёртку. Ни в одной из этих статей или туториалов я не нашёл удовлетворительного объяснения того, что происходит после внимания: как конкретно результаты вычисления внимания превращаются в точные прогнозы следующего токена?
Я подумал, что могу пропустить несколько примеров промтов через обученный мной небольшой, но работающий трансформер, изучить внутренние состояния и разобраться в них. То, что казалось мне быстрым исследованием, оказалось полугодовым погружением, но дало результаты, которыми стоит поделиться. В частности, у меня появилась рабочая теория, объясняющая, как трансформер создаёт свои прогнозы, и эмпирические свидетельства того, что это объяснение, по крайней мере, правдоподобно.
Если вы знакомы с трансформерами и хотите сразу узнать вывод, то он таков: каждый блок трансформера (содержащий слой многоголового внимания и сеть с прямой связью) изучает веса, связывающие конкретный промт с классом строк, найденных в обучающем корпусе. Распределение токенов, соответствующее этим строкам в обучающем корпусе, и есть приблизительно то, что блок выводит как прогноз для следующего токена. Каждый блок может ассоциировать один и тот же промт со своим классом строк обучающего корпуса, что приводит к другому распределению следующих токенов, а значит, и к другим прогнозам. Окончательный результат работы трансформера — это линейное сочетание прогнозов каждого блока.