Обзор практически всех *top утилит под linux (atop, iotop, htop, foobartop и т.д.).
top
Все мы знаем top — самую простую и самую распространённую утилиту из этого списка. Показывает примерно то же, что утилита vmstat, плюс рейтинг процессов по потреблению памяти или процессора. Совсем ничего не знает про загрузку сети или дисков. Позволяет минимальный набор операций с процессом: renice, kill (в смысле отправки сигнала, убийство — частный случай). По имени top суффикс "-top" получили и все остальные подобные утилиты в этом обзоре.
atop
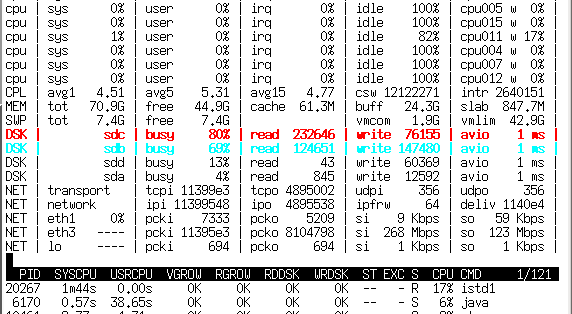
Atop имеет два режима работы — сбор статистики и наблюдение за системой в реальном времени. В режиме сбора статистики atop запускается как демон и раз в N времени (обычно 10 мин) скидывает состояние в двоичный журнал. Потом по этому журналу atop'ом же (ключ -r и имя лог-файла) можно бегать вперёд-назад кнопками T и t, наблюдая показания atop'а с усреднением за 10 минут в любой интересный момент времени.
В отличие от top отлично знает про существование блочных устройств и сетевых интерфейса, способен показывать их загрузку в процентах (на 10G, правда, процентов не получается, но хотя бы показывается количество мегабит).
Незаменимое средство для поиска источников лагов на сервере, так как сохраняет не только статистику загрузки системы, но и показатели каждого процесса — то есть «долистав» до нужного момента времени можно увидеть, кто этот счастливый момент с LA > 30 создал. И что именно было причиной — IO программ, своп (нехватка памяти), процесор или что-то ещё. Помимо большего количества информации ещё способен двумя цветами подсказывать, какие параметры выходят за разумные пределы.