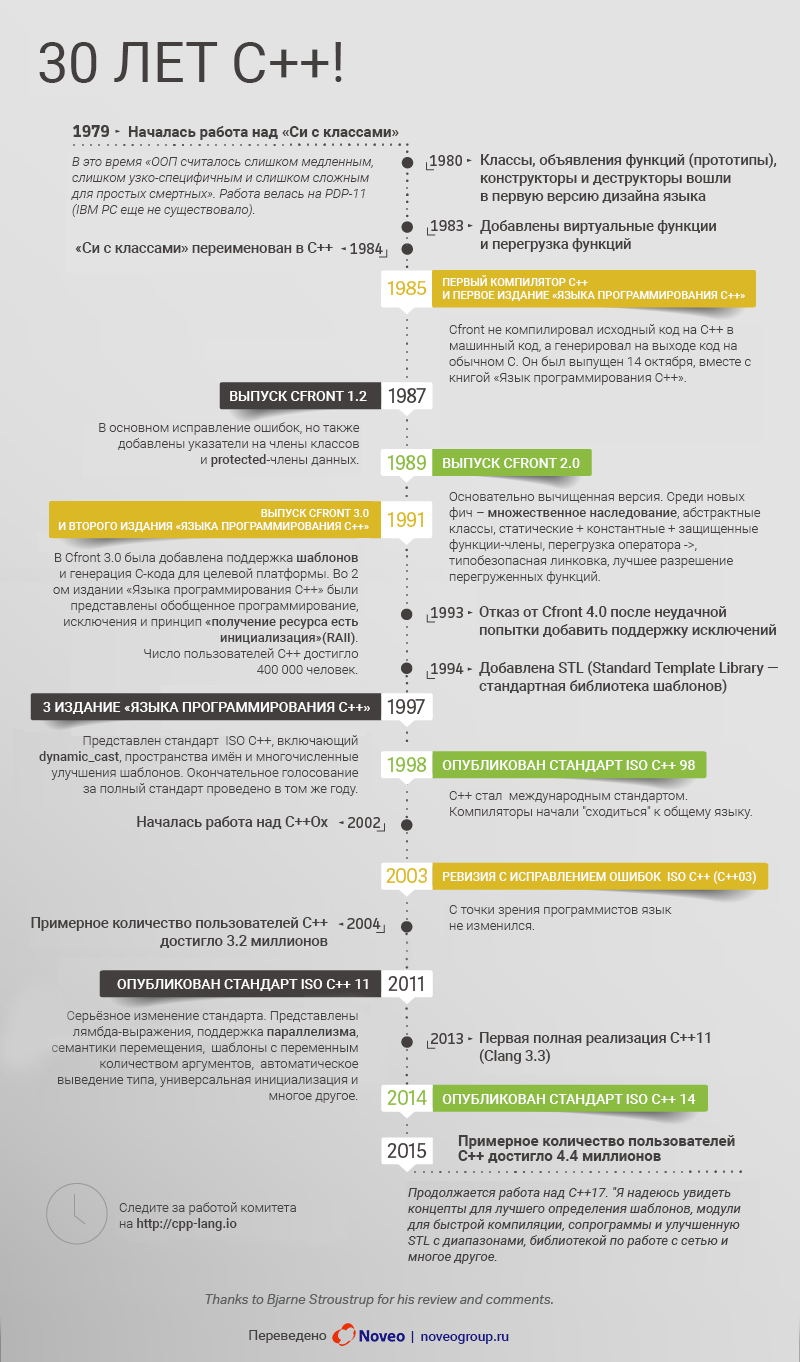
Сегодня мы продолжаем цикл статей о сборщиках мусора, поставляемых с виртуальной машиной Oracle Java HotSpot VM. Мы уже
изучили немного теории и
рассмотрели, каким образом с кучей расправляются два базовых сборщика — Serial GC и Parallel GC. А в этой статье речь пойдет о сборщиках CMS GC и G1 GC, первостепенной задачей которых является минимизация пауз при наведении порядка в памяти приложений, оперирующих средними и большими объемами данных, то есть по большей части в памяти серверных приложений.
Два этих сборщика объединяют общим названием
«mostly concurrent collectors», то есть
«по большей части конкурентные сборщики». Это связано с тем, что часть своей работы они выполняют параллельно с основными потоками приложения, то есть в какие-то моменты конкурируют с ними за ресурсы процессора. Конечно, это не проходит бесследно, и в итоге они разменивают улучшение в части пауз на ухудшение в части пропускной способности. Хотя делают это по-разному. Давайте посмотрим, как.