Я разрабатываю бесплатную библиотеку StreamEx, которая расширяет стандартное Java 8 Stream API, добавляя туда новые операции, коллекторы и источники стримов. Обычно я не добавляю всё подряд, а всесторонне рассматриваю каждую потенциальную фичу. Например, при добавлении новой промежуточной (intermediate) операции встают такие вопросы:
Минусик по любому из этих пунктов заставляет серьёзно задуматься, добавлять ли такую операцию. Минусик по первому — это сразу нет. Например, у конкурентов в jOOλ есть операция shuffle(), которая выглядит как промежуточная, но на самом деле прямо сразу потребляет весь стрим в список, перемешивает его и создаёт новый стрим. Я такое не уважаю.
Минусики по остальными пунктам не означают сразу нет, потому что есть и стандартные операции, которые их нарушают. Второй пункт нарушает
- Будет ли она действительно промежуточной, то есть не будет трогать источник до выполнения терминальной операции?
- Будет ли она ленивой и вытаскивать из источника не больше данных, чем требуется?
- Сработает ли она на бесконечном стриме? Требует ли она ограниченный объём памяти?
- Будет ли она хорошо параллелиться?
Минусик по любому из этих пунктов заставляет серьёзно задуматься, добавлять ли такую операцию. Минусик по первому — это сразу нет. Например, у конкурентов в jOOλ есть операция shuffle(), которая выглядит как промежуточная, но на самом деле прямо сразу потребляет весь стрим в список, перемешивает его и создаёт новый стрим. Я такое не уважаю.
Минусики по остальными пунктам не означают сразу нет, потому что есть и стандартные операции, которые их нарушают. Второй пункт нарушает
flatMap(), третий — sorted(), четвёртый — всякие limit() и takeWhile() (в JDK-9). Но всё-таки я стараюсь этого избегать. Однако на днях я открыл для себя операцию, которая плохо параллелится и в зависимости от использования может не сработать на бесконечном стриме, но всё же слишком хороша. Через неё удаётся буквально в несколько строчек выразить как практически любую существующую промежуточную операцию, так и кучу несуществующих. Я назвал операцию headTail().





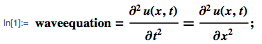

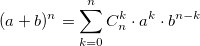 также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы:
также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы: 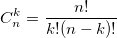 или использовать рекуррентную формулу:
или использовать рекуррентную формулу: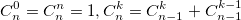 Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.
Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.

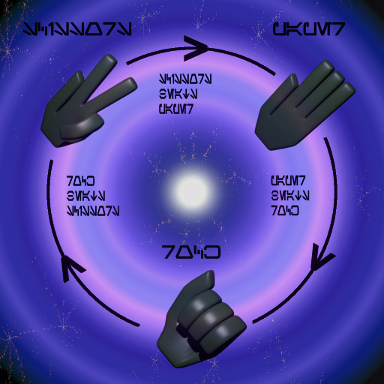 В конце прошлого года Google Translate к выходу нового эпизода «Звёздных войн» добавил поддержку «Галактического языка» Ауребеш. Правда оказалось, что при выборе этого языка просто происходит перевод на английский. Если использовать Chrome или Firefox, то появляется шрифт, в котором вместо латиницы подставлены символы ауребеш, ну а в IE без особых хитростей выводится английский текст.
В конце прошлого года Google Translate к выходу нового эпизода «Звёздных войн» добавил поддержку «Галактического языка» Ауребеш. Правда оказалось, что при выборе этого языка просто происходит перевод на английский. Если использовать Chrome или Firefox, то появляется шрифт, в котором вместо латиницы подставлены символы ауребеш, ну а в IE без особых хитростей выводится английский текст.