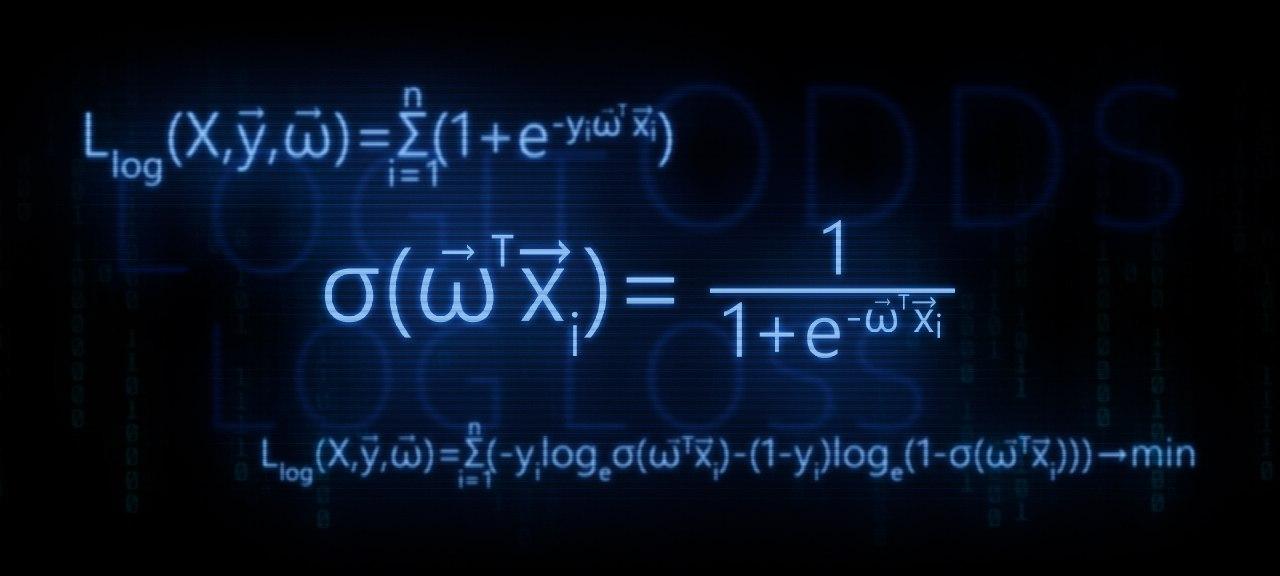Всем привет!
На связи команда Advanced Analytics GlowByte и сегодня мы разберем валидацию моделей.
Иногда термин «валидация» ассоциируется с вычислением одной точечной статистической метрики (например, ROC AUC) на отложенной выборке данных. Однако такой подход может привести к ряду ошибок.
В статье разберем, о каких ошибках идет речь, подробнее рассмотрим процесс валидации и дадим ответы на вопросы:
- на каком этапе жизненного цикла модели проводится валидация? Спойлер: это происходит больше одного раза;
- какие метрики обычно применяются при валидации и с какой целью?
- почему важно использовать не только количественные, но и качественные метрики?
Примеры в статье будут из финансового сектора. Финансовый сектор отличается от других областей (больше предписаний со стороны регулятора — Центрального банка), но в то же время в секторе большой опыт применения моделирования для решения бизнес-задач и есть широкий спектр опробованных на практике тестов по валидации моделей. Поэтому статья будет интересна как тем, кто работает в ритейле, телекоме, промышленности, так и специалистам любой другой сферы, где применяются модели машинного обучения.

 Сначала я хотел честно и подробно написать о методах снижения размерности данных —
Сначала я хотел честно и подробно написать о методах снижения размерности данных —