
Всем привет!
Представляю краткий tutorial по дообучению EasyOCR. возможно обучение на Google colab.

User
Всем привет!
Представляю краткий tutorial по дообучению EasyOCR. возможно обучение на Google colab.

Стабильность и скорость ― это то, что ожидается от автотестов. В этой статье я расскажу о нашей стратегии по оптимизации тестовой пирамиды, о том, почему мы сделали выбор в пользу Cypress и какие выработали подходы к написанию тестов, а также о запуске тестов на инфраструктуре AWS.

Привет! Меня зовут Анвар, я аналитик данных RnD-лаборатории. Перед нашей исследовательской группой стоял вопрос проработки внедрения ИИ в сервис фильтрации веб-контента SWG-решения Solar webProxy. В этом посте я расскажу, зачем вообще нужен анализ веб-контента, почему из многообразия NLP-моделей для автоматизации решения этой задачи мы выбрали модель-трансформер. Кратко объясню, как с помощью математики взвесить смысловые отношения между словами. И, конечно, опишу, как мы приземлили веб-фильтрацию в продукт.

Python стал самым популярным языком во многих быстроразвивающихся областях, таких, как глубокое обучение и различные направления анализа и обработки данных. Но при этом за удобство работы с Python-кодом, за высокий уровень его читабельности, приходится платить производительностью. Конечно, все мы время от времени жалуемся на скорость работы программ, и Python, безусловно, не стоит винить во всех грехах. Несмотря на это, справедливым будет заявление о том, что природа Python, интерпретируемого языка, не способствует высокой производительности кода, особенно когда речь идёт о «тяжёлых» вычислениях (один из признаков таких вычислений — наличие в программе нескольких вложенных циклов).
Если вы когда-либо попадали в одну из следующих ситуация — тогда эта статья, определённо, написана для вас.
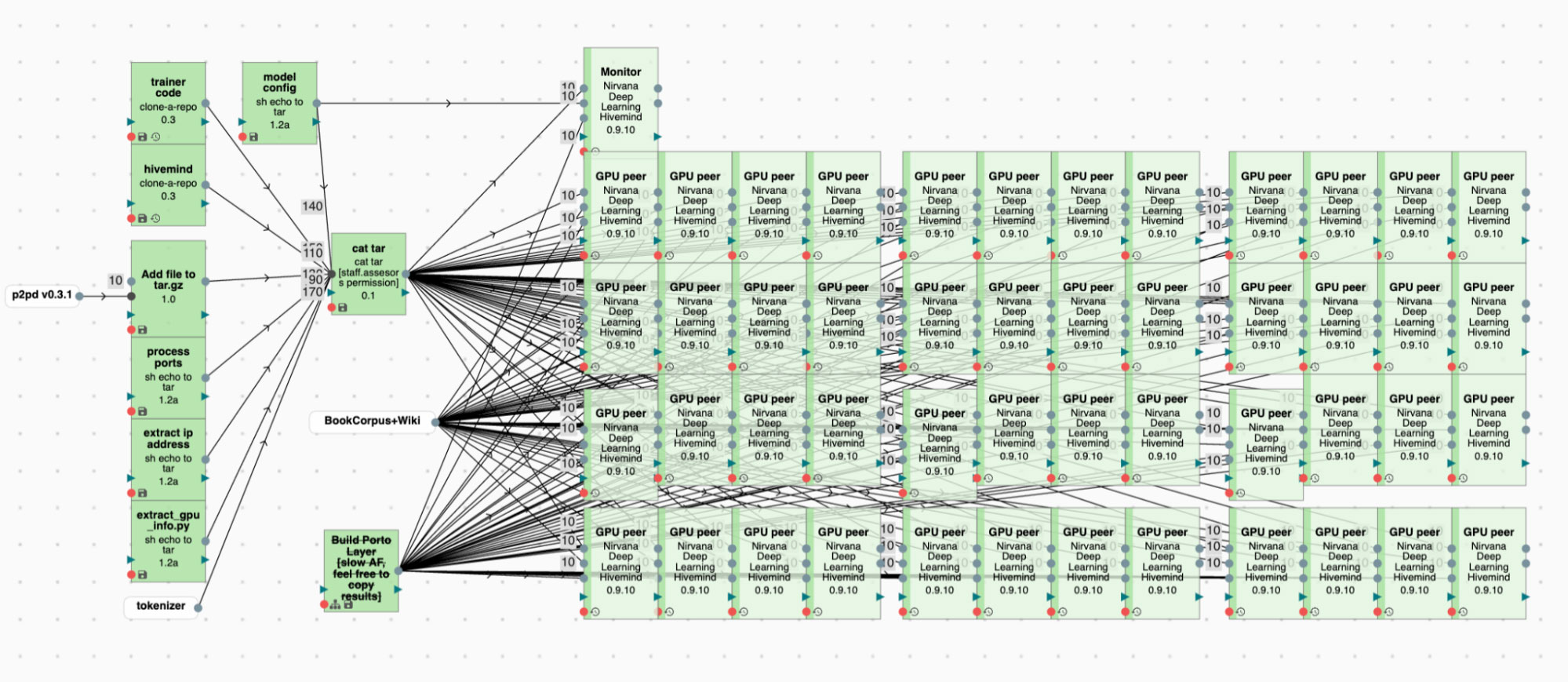
Листая интернет на наличие интересных технологий в области нейронных сетей и различного искуства,я наткнулся на пост в Твиттере, в котором Suraj Patil объявил о возможности обучения модели Stable Diffusion текстовой инверсии используя всего 3-5 изображений.

SVTR - state-of-the-art модель-трансформер для решения задачи OCR.
Авторами статьи была предложена архитектура с одним "зрительным" модулем для эффективного распознавания текста. Основная идея работы заключается в обработке признаков разного уровня, то есть локальных, которые представляют собой признаки отдельных частей символов, и глобальных, признаков целого изображения. Входное изображение с текстом сперва разбивается на компоненты, которым соответствуют определенные части изображения. Далее, применяя механизм self-attention между компонентами модель извлекает важную информацию, используя локальные и глобальные признаки. Также, уменьшая размерность и объединяя признаки после блоков self-attention, модель формирует многогранное представление о тексте на изображении. В результате, модель выдаёт последовательность признаков, в которой уже закодирован текст без использования рекуррентных сетей!

Если вы занимаетесь интернет-маркетингом, вам потребуются качественные изображения. Они влияют на эффективность рекламы ничуть не меньше, чем правильно подобранные ключи, составленное объявление или выбранная аудитория, помогают лучше воспринимать информацию из текста, хорошо запоминаются.
Мы подготовили подборку из 19 популярных фотостоков, на которых вы без проблем сможете найти изображения для любых целей. Почти все фотобанки бесплатные, а платные легко оплатить из России.


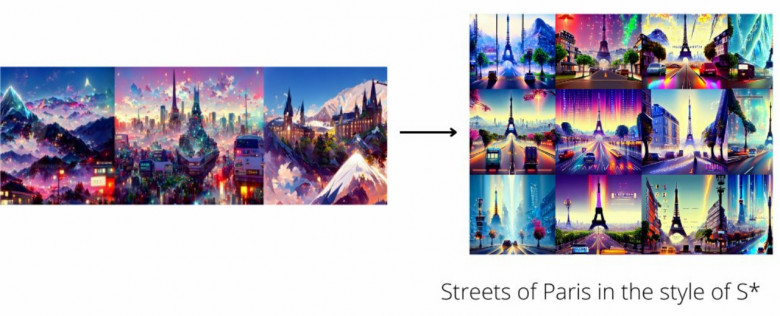
Вероятно вы уже слышали про успехи нейросетей в генерации картинок по текстовому описанию.
Я решил разобраться, и заодно сделать небольшой туториал, по архитектуре модели Stable Diffusion. Сегодня мы не будем глубоко погружаться в математику и процесс тренировки. Вместо этого сфокусируемся на применении и устройстве основных компонент: UNet, VAE, CLIP.

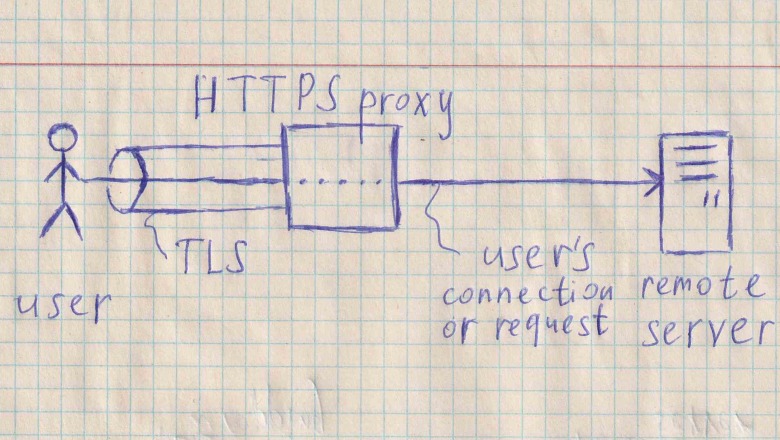
Это руководство описывает развёртывание HTTPS-прокси с помощью dumbproxy на практически любом Linux-сервере. Потребуется только curl и рутовый доступ.

Статья об успешном опыте выращивания шести кустов помидоров на гидропонике - дома, на балконе, без регистрации и СМС без ардуино и автоматизации, а только с помощью разума и сил природы. Написана чайником для чайников.


В этой статье подробно разбирается алгоритм обучения архитектуры CBOW (Continuous Bag of Words), которая появилась в 2013 году и дала сильный толчок в решении задачи векторного представления слов, т.к. в первый раз на практике использовался подход на основе нейронных сетей. Архитектура CBOW не столь требовательна к наличию GPU и вполне может обучаться на ЦП (хотя и более медленно). Большие готовые модели, обученные на википедии или новостных сводках, вполне могут работать на 4-х ядерном процессоре, показывая приемлемое время отклика.

В июне Яндекс опубликовал нейросеть YaLM 100B. Нейросеть умеет генерировать тексты. А это очень мощная вещь, можно попробовать массу всего полезного (и не очень) создать с ее помощью, от сюжетов для книг, игр и приложений, заканчивая рерайтом статей или того хуже, дорвеями.
Эта штука имеет лицензию Apache 2.0. Но чтобы запустить нужно ~ 200GB GPU видеопамяти!
И еще есть нюанс, проверить нейронку в работе, не так-то просто. Яндекс не предоставили ни демок, ни инструкций, как запустить бюджетно YaLM 100B. Пока все ждут урезанную или онлайн версию, я познакомился с ней поближе. Об этом и лонгрид.
Спойлер, дальше рассказ пойдёт о том, через что я прошёл и результаты. Исходников не будет.

Развитие методов глубокого машинного обучения привело к росту популярности нейронных сетей в задачах распознавания образов, машинного перевода, генерации изображений и текстов и многих других. С 2009 года нейронные сети попытались применить напрямую в задачах обработки графов (к которым могут относиться системы веб-страниц, связанных ссылками, словари с определенными отношениями между словами, граф социальных связей и другие) и среди возможных задач можно определить поиск кластеров узлов, создание новых графов на основе имеющейся информации о структуре графа, расширение графа и предсказание новых связей и другие. Сейчас выделяют несколько типов нейронных сетей на основе графов - сверточные графовые сети (Convolutional Graph Network), графовые изоморные сети (Graph Isomorphism Network) и многие другие и они часто используются для анализа цитирования статей, исследования текста (представление предложения как графа с указанием типов отношений между словами), изучения взаимосвязанных структур (например, исследования белковых молекул, в частности сеть Alphafold использует модель GNN) и т.д. В статье мы рассмотрим некоторые общие вопросы создания и обучения графовых сетей на основе библиотеки Python Spektral.

Неглубокое, простите за каламбур, погружение в основные принципы фридайвинга — подводного плавание на задержке дыхания, без акваланга.
О том, где у человека полости в голове, почему в кино обычно ныряют неправильно и как умный организм не даёт нам безвольно утонуть.

Пошаговая инструкция о том, как установить и использовать расширение PostGIS для PostgreSQL в Docker.
Включает в себя: установка и настройка Docker-контейнера, загрузка данных в базу данных, извлечение и визуализация данных, анализ геоданных с помощью PostGIS функционала.