Всем привет. Хочу поделиться своим опытом использования библиотеки ProvingGround, написанной на Скале с использованием Shapeless. У библиотеки имеется документация, правда, не очень обширная. Автор библиотеки — Сиддхартха Гаджил из Indian Institute of Science. Библиотека экспериментальная. Сам Сиддхартха говорит, что это пока не библиотека, а «work in progress». Глобальная цель библиотеки — брать статью живого математика, парсить текст, переводить естественный язык с формулами в формальные доказательства, которые мог бы чекать компилятор. Понятно, что до этого еще очень далеко. Пока что в библиотеке можно работать с зависимыми типами и основами гомотопической теории типов (HoTT), (полу-) автоматически доказывать теоремы.

User
Возвращаясь к Неразмеченным Конечным Интерпретаторам с Dotty
11 min
Неразмеченные Конечные Интепретаторы (Tagless Final interpreters — прим. пер.) — это альтернативный подход традиционным Алгебраическим Типам Данных (и обобщённым ADT), основанный на реализации паттерна "интерпретатор". Этот текст представляет "неразмеченный конечный" подход в Scala, и демонстрирует каким образом Dotty с его недавно добавленными типами неявных функций делает этот подход ещё более привлекательным. Все примеры кода — это прямое переложение их Haskell версий, представленных в Typed Tagless Final Interpreters: Lecture Notes (раздел 2).
Паттерн "интерпретатор" в последнее время привлекает всё больше внимания в сообществе Scala. Множество усилий было затрачено на борьбу с наиболее ярким недостатком решений, основанных на ADT/GADT: расширяемость. Для начала можно взглянуть на typeclass Inject из cats как на реализацию идей Data Type à la Carte. Библиотека Freek предоставляет средства для комбинирования более двух алгебр, используя украшения с задействованием аппарата операций на уровне типов. Решение, предложенное в работе Freer Monads, More Extensible Effects также ставит акцент на расширяемости, и вдохновлено набором небольших Scala-библиотек, таких как eff, emm и paperdoll. Неразмеченные конечные интерпретаторы подходят в некотором смысле с противоположной стороны, используя типы классов в своём непосредственном основании вместо более традиционных ADT/GADT. Они также поставляются с большим превосходством в расширяемости "из коробки" без каких-то явных опасностей.
Повышаем производительность кода: сначала думаем о данных
20 min
Translation

Занимаясь программированием рендеринга графики, мы живём в мире, в котором обязательны низкоуровневые оптимизации, чтобы добиться GPU-фреймов длиной 30 мс. Для этого мы используем различные методики и разработанные с нуля новые проходы рендеринга с повышенной производительностью (атрибуты геометрии, текстурный кеш, экспорт и так далее), GPR-сжатие, скрывание задержки (latency hiding), ROP…
В сфере повышения производительности CPU в своё время применялись разные трюки, и примечательно то, что сегодня они используются для современных видеокарт ради ускорения вычислений ALU (Низкоуровневая оптимизация для AMD GCN, Быстрый обратный квадратный корень в Quake).
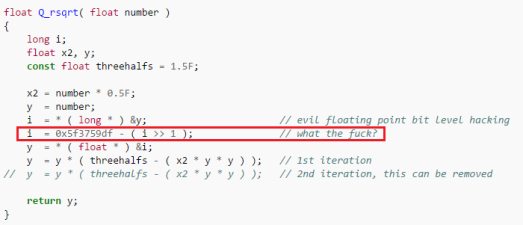
Быстрый обратный квадратный корень в Quake
Но в последнее время, особенно в свете перехода на 64 бита, я заметил рост количества неоптимизированного кода, словно в индустрии стремительно теряются все накопленные ранее знания. Да, старые трюки вроде быстрого обратного квадратного корня на современных процессорах контрпродуктивны. Но программисты не должны забывать о низкоуровневых оптимизациях и надеяться, что компиляторы решат все их проблемы. Не решат.
Эта статья — не исчерпывающее хардкорное руководство по железу. Это всего лишь введение, напоминание, свод базовых принципов написания эффективного кода для CPU. Я хочу «показать, что низкоуровневое мышление сегодня всё ещё полезно», даже если речь пойдёт о процессорах, которые я мог бы добавить.
В статье мы рассмотрим кеширование, векторное программирование, чтение и понимание ассемблерного кода, а также написание кода, удобного для компилятора.
Байесовская нейронная сеть — потому что а почему бы и нет, черт возьми (часть 1)
16 min
То, о чем я попытаюсь сейчас рассказать, выглядит как настоящая магия.
Если вы что-то знали о нейронных сетях до этого — забудьте это и не вспоминайте, как страшный сон.
Если вы не знали ничего — вам же легче, полпути уже пройдено.
Если вы на «ты» с байесовской статистикой, читали вот эту и вот эту статьи из Deepmind — не обращайте внимания на предыдущие две строчкии разрешите потом записаться к вам на консультацию по одному богословскому вопросу.
Итак, магия:

Слева — обычная и всем знакомая нейронная сеть, у которой каждая связь между парой нейронов задана каким-то числом (весом). Справа — нейронная сеть, веса которой представлены не числами, а демоническими облаками вероятности, колеблющимися всякий раз, когда дьявол играет в кости со вселенной. Именно ее мы в итоге и хотим получить. И если вы, как и я, озадаченно трясете головой и спрашиваете «а нафига все это нужно» — добро пожаловать под кат.
Если вы что-то знали о нейронных сетях до этого — забудьте это и не вспоминайте, как страшный сон.
Если вы не знали ничего — вам же легче, полпути уже пройдено.
Если вы на «ты» с байесовской статистикой, читали вот эту и вот эту статьи из Deepmind — не обращайте внимания на предыдущие две строчки
Итак, магия:
Слева — обычная и всем знакомая нейронная сеть, у которой каждая связь между парой нейронов задана каким-то числом (весом). Справа — нейронная сеть, веса которой представлены не числами, а демоническими облаками вероятности, колеблющимися всякий раз, когда дьявол играет в кости со вселенной. Именно ее мы в итоге и хотим получить. И если вы, как и я, озадаченно трясете головой и спрашиваете «а нафига все это нужно» — добро пожаловать под кат.
Функторы, аппликативные функторы и монады в картинках
5 min
Translation
Вот некое простое значение:

И мы знаем, как к нему можно применить функцию:
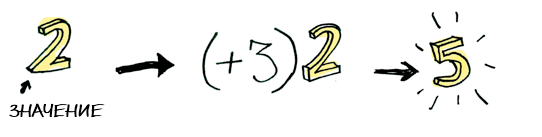
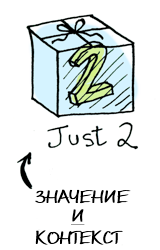
Элементарно. Так что теперь усложним задание — пусть наше значение имеет контекст. Пока что вы можете думать о контексте просто как о ящике, куда можно положить значение:
Теперь, когда вы примените функцию к этому значению, результаты вы будете получать разные — в зависимости от контекста. Это основная идея, на которой базируются функторы, аппликативные функторы, монады, стрелки и т.п. Тип данных
Позже мы увидим разницу в поведении функции для
И мы знаем, как к нему можно применить функцию:
Элементарно. Так что теперь усложним задание — пусть наше значение имеет контекст. Пока что вы можете думать о контексте просто как о ящике, куда можно положить значение:
Теперь, когда вы примените функцию к этому значению, результаты вы будете получать разные — в зависимости от контекста. Это основная идея, на которой базируются функторы, аппликативные функторы, монады, стрелки и т.п. Тип данных
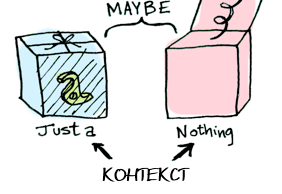
Maybe определяет два связанных контекста:data Maybe a = Nothing | Just a
Позже мы увидим разницу в поведении функции для
Just a против Nothing. Но сначала поговорим о функторах!Как я победил в конкурсе BigData от Beeline
7 min

Все уже много раз слышали про конкурс по машинному обучению от Билайн и даже читали статьи (раз, два). Теперь конкурс закончился, и так вышло, что первое место досталось мне. И хотя от предыдущих участников меня и отделяли всего сотые доли процента, я все же хотел бы рассказать, что же такого особенного сделал. На самом деле — ничего невероятного.
Некоторые репозитории в помощь изучающим и преподающим Python и машинное обучение
13 min
Привет сообществу!
Я Юрий Кашницкий, раньше делал здесь обзор некоторых MOOC по компьютерным наукам и искал «выбросы» среди моделей Playboy.
Сейчас я преподаю Python и машинное обучение на факультете компьютерных наук НИУ ВШЭ и в онлайн-курсе сообщества по анализу данных MLClass, а также машинное обучение и анализ больших данных в школе данных одного из российских телеком-операторов.
Почему бы воскресным вечером не поделиться с сообществом материалами по Python и обзором репозиториев по машинному обучению… В первой части будет описание репозитория GitHub с тетрадками IPython по программированию на языке Python. Во второй — пример материала курса «Машинное обучение с помощью Python». В третьей части покажу один из трюков, применяемый участниками соревнований Kaggle, конкретно, Станиславом Семеновым (4 место в текущем мировом рейтинге Kaggle). Наконец, сделаю обзор попавшихся мне классных репозиториев GitHub по программированию, анализу данных и машинному обучению на Python.
Машинное обучение, предсказание будущего и анализ причин успеха в электронной коммерции
10 min

Мы продолжаем публиковать материалы с летней конференции Bitrix Summer Fest. На этот раз хотим поделиться выступлением Александра Сербула, посвящённым текущим трендам в сфере машинного обучения, доступным методикам, а также практическим способам использования математики для увеличения конверсии и удержания клиентов.
Материал ни в коем случае не претендует быть формальным и научно строгим. Воспринимайте его как лёгкое, весёлое, полезное и ознакомительное «чтиво».
19 советов по повседневной работе с Git
14 min
Tutorial
Translation

Если вы регулярно используете Git, то вам могут быть полезны практические советы из этой статьи. Если вы в этом пока новичок, то для начала вам лучше ознакомиться с Git Cheat Sheet. Скажем так, данная статья предназначена для тех, у кого есть опыт использования Git от трёх месяцев. Осторожно: траффик, большие картинки!
Содержание:
- Параметры для удобного просмотра лога
- Вывод актуальных изменений в файл
- Просмотр изменений в определённых строках файла
- Просмотр ещё не влитых в родительскую ветку изменений
- Извлечение файла из другой ветки
- Пара слов о ребейзе
- Сохранение структуры ветки после локального мержа
- Исправление последнего коммита вместо создания нового
- Три состояния в Git и переключение между ними
- Мягкая отмена коммитов
- Просмотр диффов для всего проекта (а не по одному файлу за раз) с помощью сторонних инструментов
- Игнорирование пробелов
- Добавление определённых изменений из файла
- Поиск и удаление старых веток
- Откладывание изменений определённых файлов
- Хорошие примечания к коммиту
- Автодополнения команд Git
- Создание алиасов для часто используемых команд
- Быстрый поиск плохого коммита

FP на Scala: Invariant Functor
7 min
Tutorial
В статье рассматривается
Публикация является продолжением FP на Scala: Что такое функтор? в которой были рассмотрены следующие вопросы
Содержание
- Как такая абстракция теории категорий как инвариантный функтор (Invariant Functor), который иногда называют экпоненциальным функтором (Exponential Functor), выражается на Scala.
- Два правила (Identity Law, Composition Law), которым доложен следовать каждый инвариантный функтор.
- Приведен пример инвариантного функтора с состоянием (Value Holder)
- Приведен пример инвариантного функтора-отношения между элементами множества (полугруппа)
Публикация является продолжением FP на Scala: Что такое функтор? в которой были рассмотрены следующие вопросы
- Какая имеется связь между теорией категорий, Haskell и Scala.
- Что такое ковариантный функтор.
- Что такое контравариантный функтор.
Содержание
- Введение
- Что такое Invariant Functor
- Invariant Functor — Identity Law
- Invariant Functor — Composition Law
- Пример #1: Value Holder
- Пример #2: Полугруппа
- Инвариантный функтор в библиотеках
FP на Scala: Что такое функтор?
15 min
Tutorial
Специалист, приступающий к изучению функционального программирования, сталкивается как с неоднозначностью и запутанностью терминологии, так и с постоянными ссылками на «серьезную математику».
В этой статье, не используя теорию категорий с одной стороны и эзотерические языковые механизмы Scala с другой стороны, рассмотрены два важнейших понятия
Объяснено происхождение категориальной терминологии, указана роль языковых механизмов в реализации категориальных абстракций и рассмотрено несколько ковариантных (Option, Try, Future, List, Parser) и контравариантных (Ordering, Equiv) функторов из стандартной библиотеки Scala.
Первая статья в «категориальной серии»:
Если Вы желаете сильнее погрузиться в мир Scala, математики и функционального программирования — попробуйте онлайн-курс «Scala for Java Developers» (видео + тесты, всего за 25% цены!).
В этой статье, не используя теорию категорий с одной стороны и эзотерические языковые механизмы Scala с другой стороны, рассмотрены два важнейших понятия
- ко-вариантный функтор
- контра-вариантный функтор
- Exponential (Invariant) Functor, BiFunctor, ProFunctor
- Applicative Functor, Arrow, Monad / Co-Monad
- Monad Transformers, Kleisli, Natural Transformations
Объяснено происхождение категориальной терминологии, указана роль языковых механизмов в реализации категориальных абстракций и рассмотрено несколько ковариантных (Option, Try, Future, List, Parser) и контравариантных (Ordering, Equiv) функторов из стандартной библиотеки Scala.
Первая статья в «категориальной серии»:
- FP на Scala: что такое функтор?
- FP на Scala: Invariant Functor
Если Вы желаете сильнее погрузиться в мир Scala, математики и функционального программирования — попробуйте онлайн-курс «Scala for Java Developers» (видео + тесты, всего за 25% цены!).
- Про языковые механизмы абстракции
- Про теорию категорий и Haskell
- Что такое ковариантный функтор
- Примеры ковариантных функторов
- Ковариантный функтор: Identity Law
- Ковариантный функтор: Composition Law
- Ковариантный функтор: используем для оптимизации
- Что такое контравариантный функтор
- Примеры контравариантных функторов
- Контравариантный функтор: Identity Law
- Контравариантный функтор: Composition Law
- Что дальше?
Прокладка трубопровода со spark.ml
8 min
Tutorial
 Сегодня я бы хотел рассказать о появившемся в версии 1.2 новом пакете, получившем название spark.ml. Он создан, чтобы обеспечить единый высокоуровневый API для алгоритмов машинного обучения, который поможет упростить создание и настройку, а также объединение нескольких алгоритмов в один конвейер или рабочий процесс. Сейчас на дворе у нас версия 1.4.1, и разработчики заявляют, что пакет вышел из альфы, хотя многие компоненты до сих пор помечены как Experimental или DeveloperApi.
Сегодня я бы хотел рассказать о появившемся в версии 1.2 новом пакете, получившем название spark.ml. Он создан, чтобы обеспечить единый высокоуровневый API для алгоритмов машинного обучения, который поможет упростить создание и настройку, а также объединение нескольких алгоритмов в один конвейер или рабочий процесс. Сейчас на дворе у нас версия 1.4.1, и разработчики заявляют, что пакет вышел из альфы, хотя многие компоненты до сих пор помечены как Experimental или DeveloperApi.Ну что же, давайте проверим, что может новый пакет и насколько он хорош.
Такие удивительные семафоры
9 min
Translation
От переводчика: Джефф Прешинг (Jeff Preshing) — канадский разработчик программного обеспечения, последние 12 лет работающий в Ubisoft Montreal. Он приложил руку к созданию таких известных франшиз как Rainbow Six, Child of Light и Assassin’s Creed. У себя в блоге он часто пишет об интересных аспектах параллельного программирования, особенно применительно к Game Dev. Сегодня я бы хотел представить на суд общественности перевод одной из статей Джеффа.
Поток должен ждать. Ждать до тех пор, пока не удастся получить эксклюзивный доступ к ресурсу или пока не появятся задачи для исполнения. Один из механизмов ожидания, при котором поток не ставится на исполнение планировщиком ядра ОС, реализуется при помощи семафора.
Раньше я думал, что семафоры давно устарели. В 1960‑х, когда еще мало кто писал многопоточные программы, или любые другие программы, Эдсгер Дейкстра предложил идею нового механизма синхронизации — семафор. Я знал, что при помощи семафоров можно вести учет числа доступных ресурсов или создать неуклюжий аналог мьютекса, но этим, как я считал, область их применения ограничивается.
Поток должен ждать. Ждать до тех пор, пока не удастся получить эксклюзивный доступ к ресурсу или пока не появятся задачи для исполнения. Один из механизмов ожидания, при котором поток не ставится на исполнение планировщиком ядра ОС, реализуется при помощи семафора.
Раньше я думал, что семафоры давно устарели. В 1960‑х, когда еще мало кто писал многопоточные программы, или любые другие программы, Эдсгер Дейкстра предложил идею нового механизма синхронизации — семафор. Я знал, что при помощи семафоров можно вести учет числа доступных ресурсов или создать неуклюжий аналог мьютекса, но этим, как я считал, область их применения ограничивается.
Топ-10 data mining-алгоритмов простым языком
24 min
Translation

Примечание переводчика: Мы довольно часто пишем об алгоритмической торговле (вот, например, список литературы по этой теме и соответствующие аналитические материалы) и API для создания торговых роботов, сегодня же речь пойдет непосредственно об алгоритмах, которые можно использовать для анализа различных данных (в том числе на финансовом рынке). Материал является адаптированным переводом статьи американского раработчика и аналитика Рэя Ли.
Сегодня я постараюсь объяснить простыми словами принципы работы 10 самых эффективных data mining-алгоритмов, которые описаны в этом докладе.
Когда вы узнаете, что они собой представляют, как работают, что делают и где применяются, я надеюсь, что вы используете эту статью в качестве отправной точки для дальнейшего изучения принципов data mining.
Java 8: Овладейте новым уровнем абстракции
5 min
Translation
Одной из многих причин, почему мне нравится работать именно с функциональным программированием, является высокий уровень абстракции. Это связано с тем, что в конечном итоге мы имеем дело с более читаемым и лаконичным кодом, что, несомненно, способствует сближению с логикой предметной области.
В данной статье большее внимание уделяется на четыре вещи, представленные в Java 8, которые помогут вам овладеть новым уровнем абстракции.

В данной статье большее внимание уделяется на четыре вещи, представленные в Java 8, которые помогут вам овладеть новым уровнем абстракции.
Как работает yield
6 min
Translation
На StackOverflow часто задают вопросы, подробно освещённые в документации. Ценность их в том, что на некоторые из них кто-нибудь даёт ответ, обладающий гораздо большей степенью ясности и наглядности, чем может себе позволить документация. Этот — один из них.
Вот исходный вопрос:
Вот исходный вопрос:
Как используется ключевое слово yield в Python? Что оно делает?
Например, я пытаюсь понять этот код (**):
def _get_child_candidates(self, distance, min_dist, max_dist): if self._leftchild and distance - max_dist < self._median: yield self._leftchild if self._rightchild and distance + max_dist >= self._median: yield self._rightchild
Вызывается он так:
result, candidates = list(), [self] while candidates: node = candidates.pop() distance = node._get_dist(obj) if distance <= max_dist and distance >= min_dist: result.extend(node._values) candidates.extend(node._get_child_candidates(distance, min_dist, max_dist)) return result
Что происходит при вызове метода _get_child_candidates? Возвращается список, какой-то элемент? Вызывается ли он снова? Когда последующие вызовы прекращаются?
** Код принадлежит Jochen Schulz (jrschulz), который написал отличную Python-библиотеку для метрических пространств. Вот ссылка на исходники: http://well-adjusted.de/~jrschulz/mspace/
Как попасть в топ на Kaggle, или Матрикснет в домашних условиях
9 min
Хочу поделиться опытом участия в конкурсе Kaggle и алгоритмами машинного обучения, с помощью которых добрался до 18-го места из 1604 в конкурсе Avazu по прогнозированию CTR (click-through rate) мобильной рекламы. В процессе работы попытался воссоздать оригинальный алгоритм Мактрикснета, тестировал несколько вариантов логистической регрессии и работал с характеристиками. Обо всём этом ниже, плюс прикладываю полный код, чтобы можно было посмотреть, как всё работает.
Рассказ делю на следующие разделы:
1. Условия конкурса;
2. Создание новых характеристик;
3. Логистическая регрессия – прелести адаптивного градиента;
4. Матрикснет – воссоздание полного алгоритма;
5. Ускорение машинного обучения в Python.
Рассказ делю на следующие разделы:
1. Условия конкурса;
2. Создание новых характеристик;
3. Логистическая регрессия – прелести адаптивного градиента;
4. Матрикснет – воссоздание полного алгоритма;
5. Ускорение машинного обучения в Python.
Указатели, ссылки и массивы в C и C++: точки над i
10 min
Tutorial
В этом посте я постараюсь окончательно разобрать такие тонкие понятия в C и C++, как указатели, ссылки и массивы. В частности, я отвечу на вопрос, так являются массивы C указателями или нет.
Указатели. Что такое указатели, я рассказывать не буду. :) Будем считать, что вы это знаете. Напомню лишь следующие вещи (все примеры кода предполагаются находящимися внутри какой-нибудь функции, например, main):
Обозначения и предположения
- Я буду предполагать, что читатель понимает, что, например, в C++ есть ссылки, а в C — нет, поэтому я не буду постоянно напоминать, о каком именно языке (C/C++ или именно C++) я сейчас говорю, читатель поймёт это из контекста;
- Также, я предполагаю, что читатель уже знает C и C++ на базовом уровне и знает, к примеру, синтаксис объявления ссылки. В этом посте я буду заниматься именно дотошным разбором мелочей;
- Буду обозначать типы так, как выглядело бы объявление переменной TYPE соответствующего типа. Например, тип «массив длины 2 int'ов» я буду обозначать как
int TYPE[2]; - Я буду предполагать, что мы в основном имеем дело с обычными типами данных, такими как
int TYPE,int *TYPEи т. д., для которых операции =, &, * и другие не переопределены и обозначают обычные вещи; - «Объект» всегда будет означать «всё, что не ссылка», а не «экземпляр класса»;
- Везде, за исключением специально оговоренных случаев, подразумеваются C89 и C++98.
Указатели и ссылки
Указатели. Что такое указатели, я рассказывать не буду. :) Будем считать, что вы это знаете. Напомню лишь следующие вещи (все примеры кода предполагаются находящимися внутри какой-нибудь функции, например, main):
int x;
int *y = &x; // От любой переменной можно взять адрес при помощи операции взятия адреса "&". Эта операция возвращает указатель
int z = *y; // Указатель можно разыменовать при помощи операции разыменовывания "*". Это операция возвращает тот объект, на который указывает указатель
Взлом пароля на Mac с Arduino и OpenCV
6 min
О том, как взламывали запароленный мак с помощью Arduino и OpenCV. По мотивам статьи Брутфорсим EFI с Arduino.
