
Привет, habr! Предлагаю вашему вниманию статью о том, как я писал велосипед библиотеку для передачи сообщений между потоками с возможностью мультиплексирования.

User
Привет, habr! Предлагаю вашему вниманию статью о том, как я писал велосипед библиотеку для передачи сообщений между потоками с возможностью мультиплексирования.

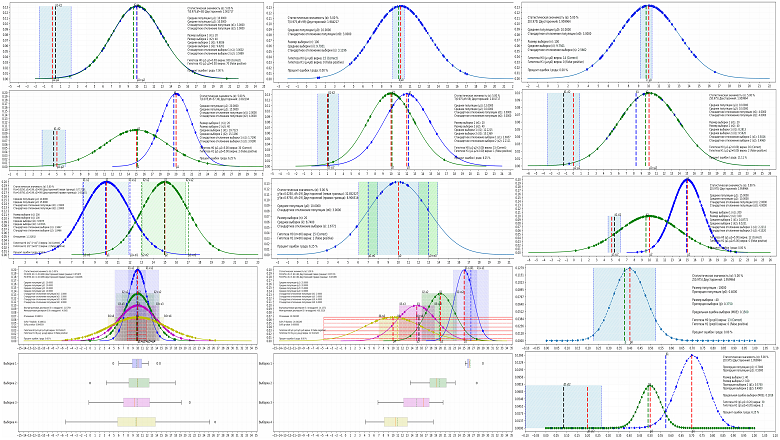
Одной из самых распространённых задач аналитики является формирование суждений о большой совокупности (например, о миллионах пользователей приложения), опираясь на данные лишь небольшой части этой совокупности - выборке. Можно ли сделать вывод о миллионной аудитории крупного мобильного приложения, собрав данные 100 пользователей? Или стоит собрать данные о 1000 пользователях? Какую вероятность ошибиться при анализе мы можем допустить: 5% или 1%? Относятся ли две выборки к одной совокупности, или между ними есть ощутимая значимая разница и они относятся к разным совокупностям? Точность прогноза и вероятность ошибки при ответе на эти и другие вопросы поддаются вполне конкретным расчётам и могут корректироваться в зависимости от потребностей продукта и бизнеса на этапе планирования и подготовки эксперимента. Рассмотрим подробнее, как параметры эксперимента и статистические критерии оказывают влияние на результаты анализа и выводы обо всей совокупности, а для этого смоделируем тысячу A/A, A/B и A/B/C/D тестов.

Написать этот материал меня побудило... отсутствие хороших статей по корутинам в C++ в русскоязычном интернете, как бы странно это не звучало. Ну серьезно, C++20 существует уже несколько лет как, но до сих пор почти все статьи про корутины, что встречаются в рунете, относятся к одному из двух типов. Или обзор начинается с самых глубин и мелочей, пересказывая cppreference, а потом автор выдыхается и все сводится к "ну а дальше все понятно, возьмите и примените это в своем коде", что напоминает известную картинку с совой. Либо иногда в статьях рассматривается применение корутин на примере генераторов, и этим все и ограничивается. Но, давайте будем честны, генераторы — это замечательно, но за все время моей многолетней карьеры разработчика я, вероятно, делал что‑то подобное генераторам разве что разок, в то время как асинхронный ввод‑вывод приходится использовать почти в каждом проекте. И поэтому меня гораздо больше интересует реализация асинхронного ввода‑вывода с использованием корутин, а не генераторы. Поэтому пришлось разбираться во всем самому.


Чем больше ты становишься экспертом, тем чаще HR видят в тебе не просто коллегу… а спикера на конференциях и митапах. Ну потому что нельзя скрывать такое сокровище!
Одно дело — подготовить доклад, другое — с ним выступить (тяжкий вздох). Словить атаческую панику за 5 минут до триумфального появления перед публикой может даже самый титулованный специалист. И это ок.
Чтобы не переживать и с удовольствием делиться опытом с аудиторией, нужно просто настроиться на выступление: привести в порядок голос и нервы.
Накануне Митапа в Уфе 28 марта собрали в статье лайфхаки, которые помогут чувствовать себя перед аудиторией комфортнее, а звучать — увереннее.

Это история про то, как не довести дело до конца, но получить уйму опыта, и вообще ни разу не обломаться.
Итак, у нас был один программист, один художник, абсолютное непонимание рабочего процесса, незнакомый нам игровой движок и желание что-то намутить. Если вам интересно, как в одном месте сошлись карта Вороного, частный случай расстояния Минковского, преобразования над полигонами, процедурная генерация и шумы — и все это в красивой стилизованной обертке, то вам под кат.
Осторожно, очень много картинок!
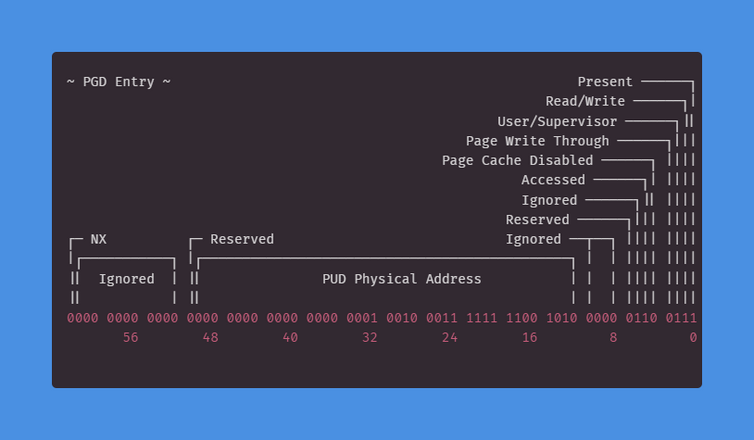
В этом посте я буду говорить о страничной организации только в контексте PML4 (Page Map Level 4), потому что на данный момент это доминирующая схема страничной организации x86_64 и, вероятно, останется таковой какое-то время.
Окружение
Это необязательно, но я рекомендую подготовить систему для отладки ядра Linux с QEMU + gdb. Если вы никогда этого не делали, то попробуйте такой репозиторий: easylkb (сам я им никогда не пользовался, но слышал о нём много хорошего), а если не хотите настраивать окружение самостоятельно, то подойдёт режим практики в любом из заданий по Kernel Security на pwn.college (вам нужно знать команды vm connect и vm debug).
Я рекомендую вам так поступить, потому что считаю, что самостоятельное выполнение команд вместе со мной и возможность просмотра страниц (page walk) на основании увиденного в gdb — хорошая проверка понимания.

При разработке приложений на платформе .NET почти всегда возникает необходимость включить в сборку сторонние ресурсы. Попробуем настроить процесс сборки небольшого проекта на Avalonia UI для Windows и Linux.

Я потратил неделю, копаясь во внутренностях MySQL/MariaDB вместе с ещё примерно 80 разработчиками. Хотя MySQL и MariaDB — это, по большей части, одно и то же (я ещё к этому вернусь), я сосредоточился именно на MariaDB.
Раньше я никогда сам не собирал MySQL/MariaDB. В первый день «недели хакерства» я смог наладить локальную сборку MariaDB и твикнул код так, что запрос SELECT 23 возвращал 213. Сделал я и другой твик — такой, что запрос SELECT 80 + 20 возвращал 60. На второй день я смог заставить заработать простую UDF на C, благодаря которой запрос SELECT mysum(20, 30) давал 50.
Остаток недели я потратил, пытаясь разобраться с тем, как сделать минимальный движок для хранения данных в памяти. Именно о нём я и расскажу. Это — 218 строк кода на C++.


git pull или git push! Да, так и есть, и некоторые случаи довольно просты, но другие гораздо сложнее. Более того, тот алгоритм, что используется в Git, не слишком хорошо документирован – в общем, мы полагали, что у нас может получиться лучше.
В интернете невероятное количество статей о том "как написать свой генератор на С++20", но почти все они сводятся к новичковым хело вордам и почти ни одной статьи о том как написать хороший генератор. Что ж, это нужно исправлять!
Есть много локальных аналогов ChatGPT, но им не хватает качества, даже 65B модели не могут конкурировать хотя бы с ChatGPT-3.5. И здесь я хочу рассказать про 2 открытые модели, которые всё-таки могут составить такую конкуренцию.
Речь пойдет о OpenChat 7B и DeepSeek Coder. Обе модели за счет размера быстры, можно запускать на CPU, можно запускать локально, можно частично ускорять на GPU (перенося часть слоев на GPU, на сколько хватит видеопамяти) и для такого типа моделей есть графический удобный интерфейс.
И бонусом затронем новую модель для качественного подробного описания фото.
UPD: Добавлена информация для запуска на Windows с ускорением на AMD.
Меня зовут Валя Борисов, и я — аналитик в команде Ozon. Задача нашей команды — создавать инструменты для мониторинга и анализа скорости.
Наши усилия направлены на то, чтобы в реальном времени следить за тем, как быстро работают наши сервисы и платформа. Благодаря инструментам, которые мы создаём и поддерживаем, команды разработки получают представление о том, как пользователи видят работу нашего сайта или приложения. Мы помогаем выявлять причины деградации скорости и определять узкие места в инфраструктуре.
Наши дашборды играют ключевую роль в предоставлении информации о скорости работы платформы. Вместе с командой аналитиков я занимаюсь созданием и поддержкой этой системы в Grafana. Мы стремимся делать ее не только информативной, но и быстрой, стабильной и удобной для всех пользователей. В этой статье я хочу поделиться методами и приемами, к которым мы пришли в процессе работы.

Привет, Хабр! Сегодня я хочу вам представить подборку интересных новостей и материалов из мира C++ за последние две недели.
Приятного чтения!

Сборная солянка из существующих best practices по работе с Grafana и немного с Prometheus, проверенных мной лично. Можно просто положить в закладки — когда-нибудь да пригодится.

В этой статье мы рассмотрим, почему API-шлюзы стали ключевым элементом экосистемы современных облачных вычислений и как появление Kubernetes API Gateway упростило и стандартизировало работу с ними.
Статья составлена на основе сразу двух англоязычных материалов. В первом (его мы поместили в самое начало) авторы на примере профессий объясняют роль различных компонентов облачных приложений, а во втором — проводят глубокий анализ все возрастающей значимости API-шлюзов для экосистемы облачных приложений, их места в рамках концепции «Kubernetes — облачная операционная система» и того, как повлияет на дальнейшее развитие API-шлюзов появление Kubernetes API Gateway.